效度分析的几点思考
数据效度分析在学术研究中非常常见,其用于分析‘测量项是否真实有效的测量自己希望测量的变量’,效度分析的研究方式有多种,通常包括内容效度,结构效度(探索性因子分析法)和区分效度或聚合效度(验证性因子分析法)。可见下表格:
| 效度分析类型 | 说明 |
|---|---|
| 内容效度 | 使用文字描述量表设计的合理性 |
| 结构效度(探索性因子分析) | 探索性因子分析结果,与专业预期进行对比 |
| 区分或聚合效度(验证性因子分析) | 验证性因子分析判断量表是否合理 |
-
第一种内容效度是指使用文字叙述形式对问卷的合理性、科学性进行说明,比如问卷中测量量表题有着严谨的参考依据,问卷设计得到专家的认可等,如果有参考依据,也或者有着专家认可,那么即是说测量项确实可以测量自己希望测量的变量;比如测量‘美丽’这个变量,用了三个量表题,分别是‘看起来很年轻’,‘看上去五官端正’,‘看上去心情很好’,这3个测量题是有着参考依据,也或者专家认为此3项确实可以测量‘美丽’这个关键变量,那么就说明具有内容效度。
-
第二种结构效度通常使用探索性因子分析(EFA)进行验证,即通过探索性因子分析对题项进行分析,如果输出结果显示题项与变量对应关系基本与预期一致,则说明结构效度良好。即在收集好数据后,让软件运行下,软件会运行出来‘变量’与‘测量项’之间的对应关系情况,而自己也有着‘变量’与‘测量项’之间的对应关系,如果说二者基本吻合,那么说明自己想的,与软件出来的结果基本一致,那么就说明结构上数据具有有效性,即具有结构效度。此种测量方式最为普遍,在实际研究中最常使用。当然很可能结果为‘变量’与‘测量项’之间的对应关系情况,与自己预期不一致,此时需要自行分析,通常是删除掉对应关系出错的‘测量项’,最终让余下的‘测量项’与‘变量’的对应关系,与预期保持一致。
-
第三种效叫区分或聚合效度,其实质也是一种结构效度。区分效度强调本不应该在同一因子的测量项,确实不在同一因子下面。聚合效度强调本应该在同一因子下面的测量项,确实在同一因子下面。区分效度的具体测量方式是使用AVE值,以及聚合效度是使用AVE开根号然后再与相关分析结果进行对比,除此之外还可以使用HTMT异质-单质比率法测量聚合效度,在SPSSAU中均有默认提供。
-
下表格展示各种效度与测量方式等。
| 项 | 概述 | 使用方法 |
|---|---|---|
| 内容效度 | 用文字描述量表的有效性,比如具有参考文献来源,量表经过专家认可等 | 文字描述 |
| 结构效度 | 因子与测量项(量表题项)对应关系是否符合预期,如果符合预期则说明具有结构效度 | 探索性因子分析(EFA) |
| 聚合(收敛)效度 | 强调本应该在同一因子下面的测量项,确实在同一因子下面 | 验证性因子分析(CFA)的AVE和CR指标等 |
| 区分效度 | 强调本不应该在同一因子的测量项,确实不在同一因子下面 | AVE和相关分析结果对比 |
在实质研究中,内容效度较为基础基本上所有的研究均会涉及到内容效度。一般使用探索性因子分析EFA进行效度研究的情况最为常见。在效度分析过程中,通常会出现‘变量’与‘测量项’之间的对应关系严重偏离,即效度不达标。一般此种偏离可具体分为两种情况,分别是‘张冠李戴’和‘纠缠不清’,‘张冠李戴’指对应关系完全出错,此种情况需要直接把‘测量项’删除掉;如果是出现‘纠缠不清’,即‘测量项’归到两个或更多个‘变量’里面都可以,但是一定在自己希望测量的‘变量’里面有出现,那么这种情况就是‘纠缠不清’,此种情况一般可以不处理。接下来会以一个具体的例子讲解如何做效度分析,便于删除掉不合理的‘测量项’,最终数据效度达标。
-
1、剖析思路‘全进入效度法’和‘步进效度法’
首先说明下案例数据背景,总共有收回634份样本数据。数据从专业预期上是分为A,B,C,D,E共5个因子共33个测量项。其中4个因子预期对应着6个量表题 ,还有1个因子预期对应着9个量表题 。预期对应关系如下:
A 因子 B 因子 C 因子 D 因子 E 因子 A1 B1 C1 D1 E1 A2 B2 C2 D2 E2 A3 B3 C3 D3 E3 A4 B4 C4 D4 E4 A5 B5 C5 D5 E5 A6 B6 C6 D6 E6 D7 D8 D9 现希望使用探索性因子分析进行结构效度分析。分析的思路有两种,分别是‘全进入效度法’和‘步进效度法’,如下:
-
直接把总共33个测量项进行因子分析,SPSSAU称其‘全进入效度法’。
-
直接把33项放入因子分析框中进行分析,然后按照流程下述流程进行分析,此种操作方法SPSSAU称其为‘全进入效度法’:

-
首先设置维度个数为5个数,并且接着把‘共同度’值较低(一般小于0.4或0.5)移除掉,‘共同度值’低意味着‘测量项’的信息没有被提取出来,说明根本不适合对‘测量项’进行测量;接着移除掉‘张冠李戴’的项,似情况而定,一般一次移除尽量少的‘测量项’;重复第2步和第3步操作,直到最终‘测量项’与‘变量’之间的对应关系情况与预期符合。
-
此种操作流程较为常见,可在SPSSAU官网帮助手册里面找到 详细例子点击查看。但此种流程有个前提,即数据质量还比较OK的时候较为有效,如果说数据质量比较糟糕,出现非常多的‘张冠李戴’,也或者很多‘测量项’的共同度值都很低。那么就会出现调整很多次也调整不好,比如本次的案例数据就是这样, 结果点击查看。
-
因而建议可使用下一种办法即‘步进效度法’。
-
分别每个‘变量’做因子分析,然后组合回去,SPSSAU称其为‘步进效度法’。
-
当数据质量较差(当然很多时候会这样),使用‘全进入效度法’进行效度分析时均无果,原因在于数据对应关系很差,使用‘全进入效度法’时,重复次数过多,容易出现误删除‘测量项’,最终导致无论如何也不行。因而可使用‘步进效度法’,具体操作思路流程如下图:

-
‘步进效度法’,其思想在于首先将非常糟糕的测量项直接‘干掉’,然后再进行‘全进入效度法‘分析流程。这样可大大减少测量项的个数,减少分析难度。
-
其第1步时,先以‘变量’为单位进行效度分析,那么‘测量项’仅测量一个‘变量’,维度/因子个数自然就设置为数量1;多个‘变量’就重复多次。删除掉‘共同度值’较低项。
-
接下来会使用案例讲述‘步进效度法’。
-
-
2、案例详细说明
首先本案例如果直接进入‘全进入效度法’时,结果较糟糕 可点击查看。
那么按照‘步进效度法’的思想,先分别进行5次效度分析,第1次针对因子A,SPSSAU操作截图如下:
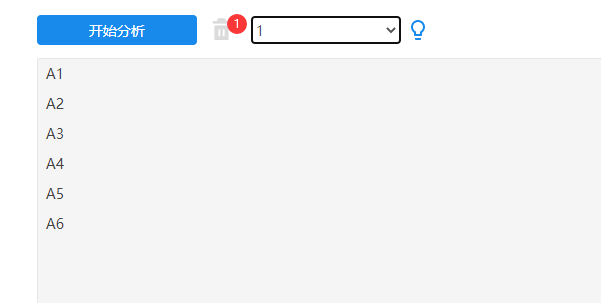
SPSSAU输出结果 可点击查看
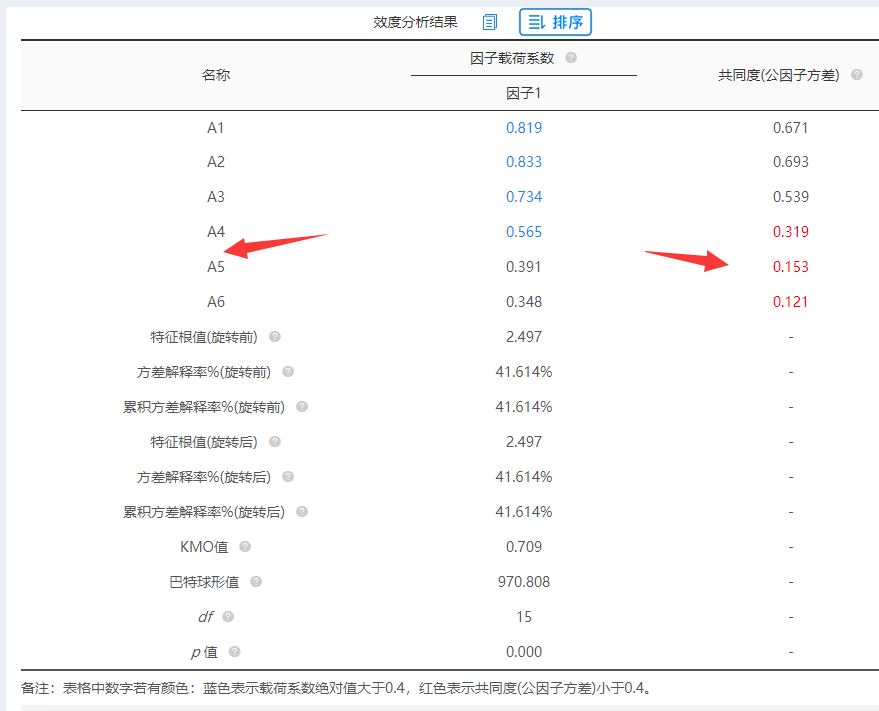
明显的可以看出:A4,A5,A6这3个‘测量项’的共同度值小于0.4,因此将此3项删除后再次分析。结果如下:
-
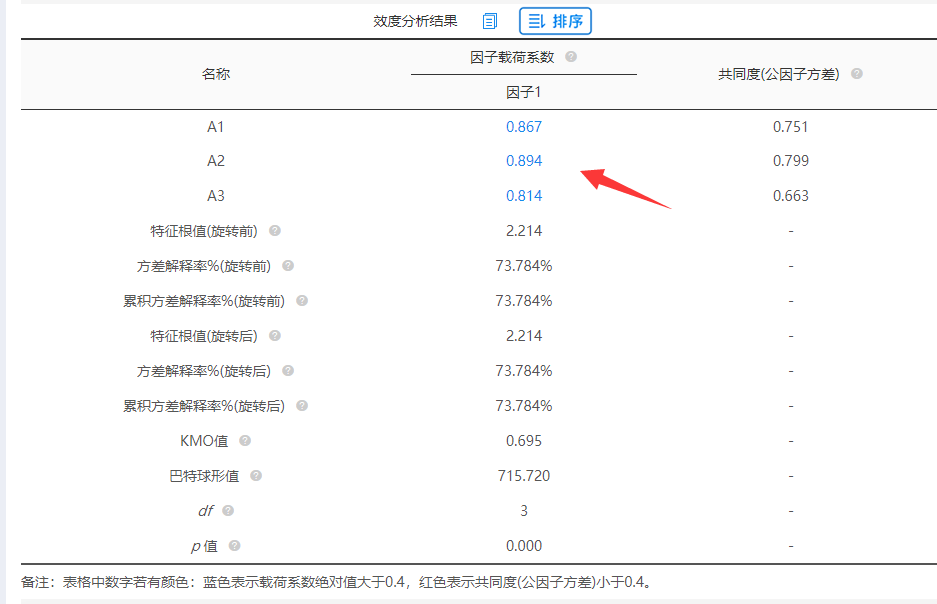
此时显示因子A余下3个‘测量项’(A1,A2,A3),而且‘测量项’的共同度值均大于0.6,且载荷系数值均大于0.8,说明余下3个‘测量项’还可以。
-
针对因子B,因子C,因子D,因子E均一样的操作流程。
-
因子B余下B5,B6共2项;因子C余下C1,C3,C5,C6共4项;因子D余下D5和D6共2项;因子E余下E1,E2,E3共3项。最终余下项如下表格:
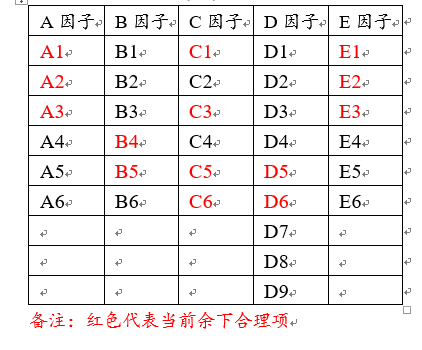
当前余下共14项,进入‘步进效度法’的第4步,即进行‘全进入效度法’。操作如下图:
最终结果如下图,而且全部对应关系均良好,没有‘张冠李戴’现象。
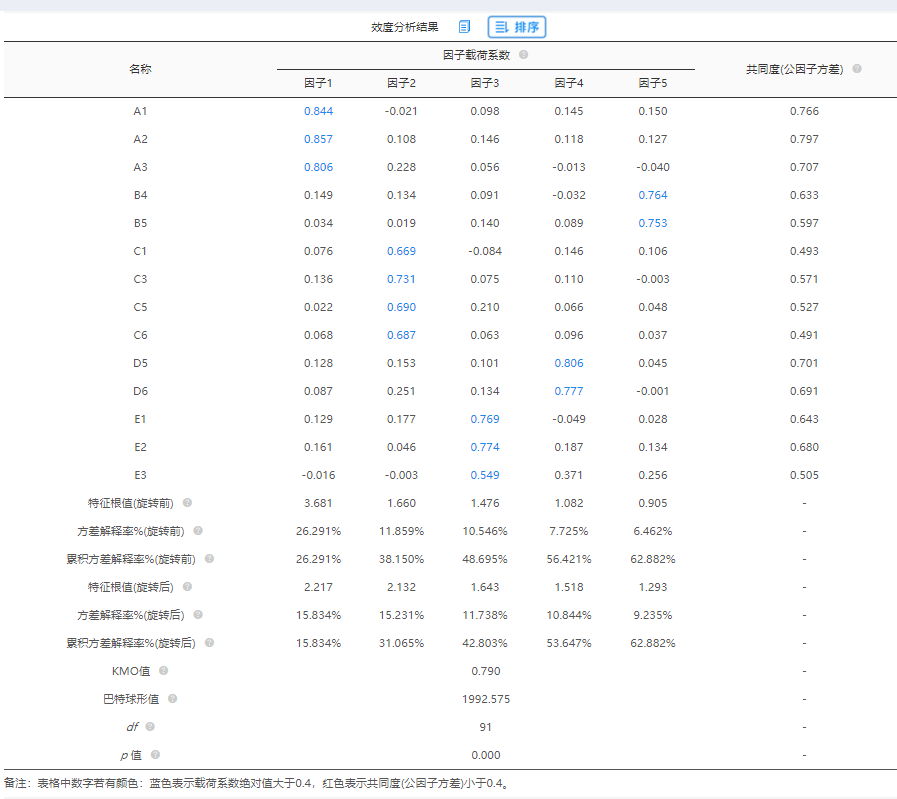
完整结果 可点击查看。
相对‘全进入效度法’,‘步进效度法’首先以‘变量’为单位进行分析,首先将完全不合理项进行删除,这样做的目的在于进行最后‘全进入效度法’时,先过滤掉不合理项,减少进行‘全进入效度法’的分析难度。SPSSAU建议‘新手’或者‘测量项’很多时使用‘步进效度法’。
-
-
3、‘步进效度法’后依旧不达标如何办?
如果使用‘步进效度法’,数据依然不达标,即效度依旧很糟糕,可有3种处理或者简易方式。
-
第一种:直接使用KMO值来表述效度
-
直接使用KMO值来测量效度水平,这种方式非常粗糙,原因在于KMO值实质上是测量‘测量项’之间的相关关系程度,即KMO值越高,意味着‘测量项’之间的关系程度高,当然此种测量方式也在一定程度上说明数据有着效度,只是比较简单而已。
-
第二种:以一个因子作为单位分析后组合结果
-
以一个因子作为单位进行分析,即进行‘步进效度法’的前3步,但不进行‘步进效度法’的最后一步。即只考虑每个‘变量’的效果可行,并不考虑所有变量放在一起时的效度。此种方式在一定程度上可行,但其没有考虑到‘所有变量之间的测量项的干扰性’,实质上没有考虑‘区分效度’问题,仅考虑‘聚合效度’问题。当前此种方式使用也较多,思路上也可行。
-
第三种:内容效度
-
一般来说量表数据才能做结构效度分析,如果数据并不适合进行结构效度,那么直接使用内容效度分析就好。很多数据是非量表结构,从分析方法上并没有对应的分析方法。那么如何论证数据的有效性,此时可使用内容效度即可。
-
-
4、关于CFA做效度分析
如果在使用探索性因子分析之后,还想进一步研究区分效度或聚合效度,此时需要使用验证性因子分析进行。特别提示:验证性因子分析和探索性因子分析,二者实质测量的‘核心底层’范畴一致,如果说探索性因子分析没有完成,直接进行验证性因子分析,很难使数据达标。正确的操作流程如下:

一般来说,验证性因子分析对于数据质量的要求明显更高,一定需要严格按照EFA后再CFA这种流程进行检验,否则数据基本不可能达标。也或者直接进行CFA分析时,也需要删除掉非常多不合理‘测量项’。