-
数据是研究方法的基础,本文档详细阐述SPSSAU系统中常见的几类研究方法对应的数据格式参考,包括方差分析、T 检验、配对t 检验、多选题、卡方检验、重复测量方差、模糊综合评价、AHP层次分析法、时间序列ARIMA模型、面板模型等。
无论是哪种数据,均需要规范整理才可以,包括如下要点:
-
第一行只能是标题,并且第一行不能出现空,否则就没有标题可以拖拽操作;
-
不能出现任何的合并单元格;
-
不能出现完整的空行,或者完整的空列。
-
-
1、方差分析【通用方法>方差】
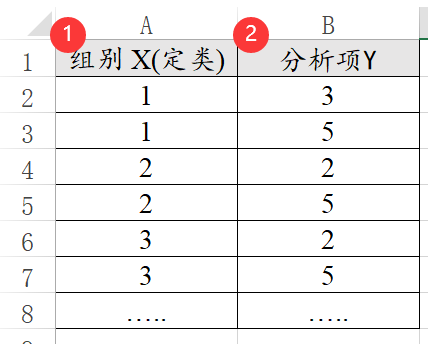
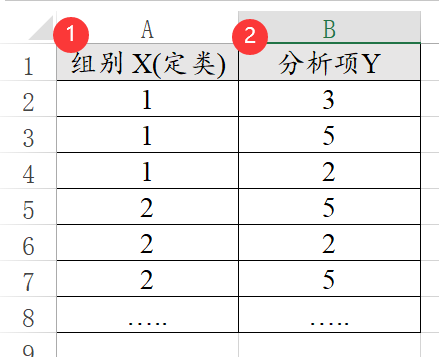
方差分析是研究不同组别的差异,比如不同学历时满意度的差异。因此数据格式中一定需要有组别X(比如学历)和分析项Y(比如满意度)。
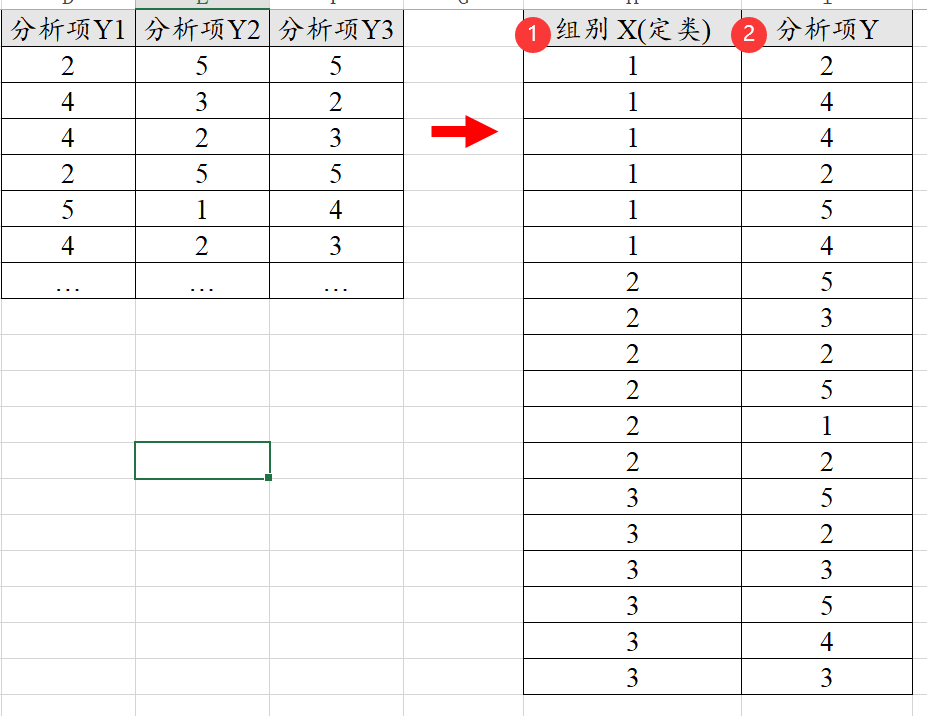
有时候只有分析项(比如3个分析项),但是现在希望此3个分析项的差异,那么就需要对数据进行改造,自己加入一列‘组别’,然后把数据重叠起来得到分析项Y,类似如下图:
-
2、t 检验【通用方法>t 检验】
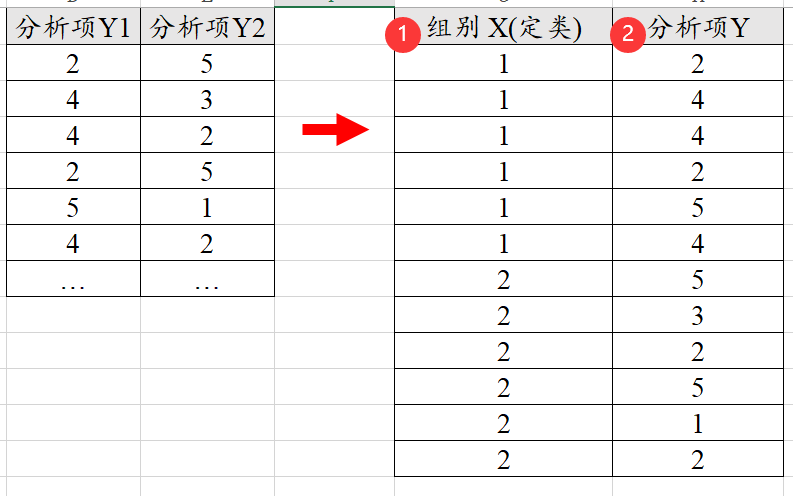
t 检验是研究2组数据的差异,比如不同性别时满意度的差异。数据格式中需要有组别X(比如性别)和分析项Y(比如满意度)。
有时候数据格式中只有2列,而没有组别,比如实验组和对照组。那么就需要对数据进行改造,自己加入一列‘组别’,然后把数据重叠起来得到分析项Y,类似如下图:
-
3、配对t 检验【通用方法>配对t 检验】
配对数据的格式相对较为特殊,包括配对t 检验,或者配对卡方等。比如实验组和对照组数据的差异。如下图:
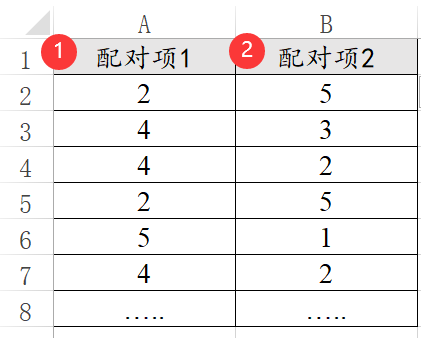
配对数据一般是在实验时使用,而且配对数据的特点为:行数一定完全相等并且只有两列。如果研究数据的行数不相等,那可能不是配对数据,如果还想对比差异,可能需要使用独立t 检验。独立t 检验和配对t 检验的数据格式不一样,需要特别注意。
-
4、多选题【问卷研究>多选题】
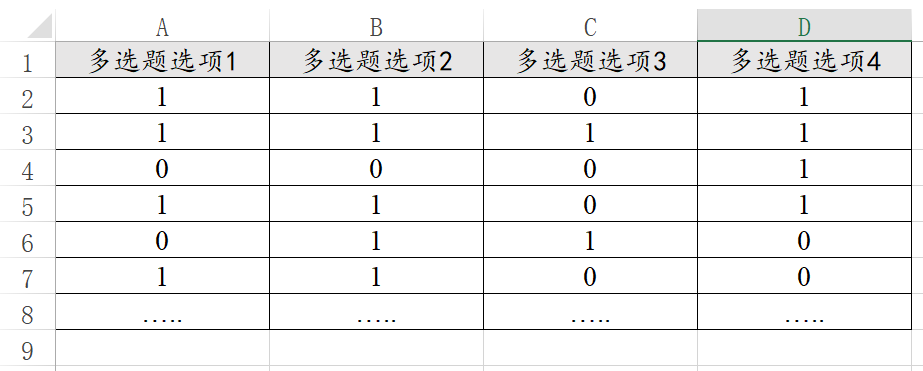
在问卷研究时会使用到多选题,多选题的数据格式比较特殊。比如一个多选题有4个选项,那么其数据中就会有4列,分别代表4个选项。而且使用数字1表示选中,数字0表示没有选中。如下图:
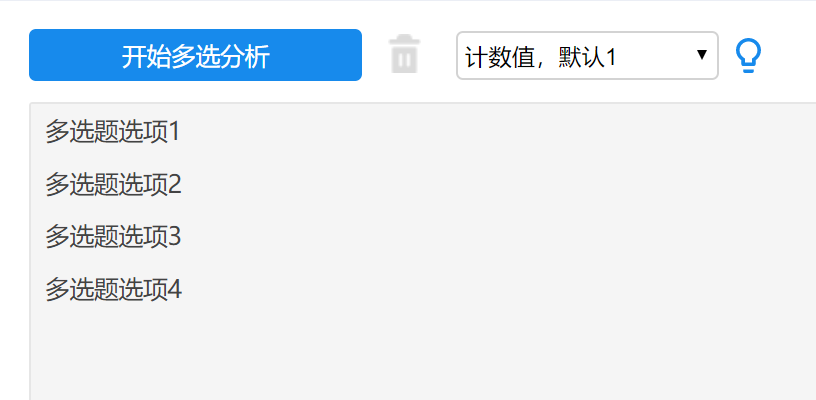
在进行多选题相关的研究时,需要把同一个多选题下面所有的选项全部放到分析框中才可以。比如下图操作:
-
5、卡方检验【实验/医学研究>卡方检验】
卡方检验研究X和Y的差异,并且X和Y都是定类数据。使用SPSSAU实验/医学研究模块下的卡方检验时,SPSSAU可支持两类数据格式,一种是常规格式(非加权格式),另外一种是加权数据格式。
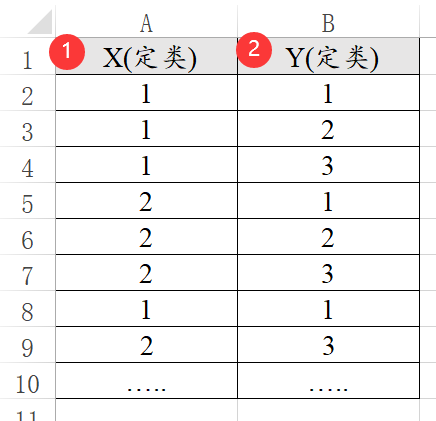
上图为常规格式(即非加权格式),一行代表一个样本,一列代表一个属性,将全部的原始数据信息列出即可。
在医学/实验研究时,很多时候只有汇总数据,即带加权项的数据,比如下图中X有2种情况,Y有3个情况,一种有2*3=6种组合,数据信息只有6种组别的汇总项(即加权项),分别是40,10,20,30,20,50;相当于总共有170个样本,如果是使用常规格式(即非加权格式),此时应该有170行;但加权格式则只需要6行即可表示,如下图。
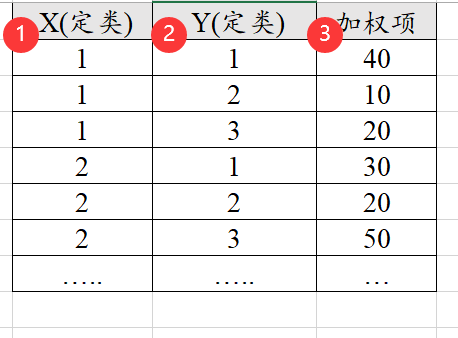
加权数据格式基本只针对全部是定类数据的研究时使用,SPSSAU支持常规格式和加权格式两种数据。常规格式提供所有的原始数据信息,而加权格式只提供汇总数据信息。涉及以下方法时,SPSSAU会支持加权数据格式,如下:
-
【可视化】词云
-
【问卷研究】对应分析
-
【实验/医学研究】卡方检验
-
【实验/医学研究】Kappa
-
【实验/医学研究】配对卡方
-
【实验/医学研究】Poisson回归
-
【实验/医学研究】Ridit分析
-
【实验/医学研究】卡方拟合优度
-
【实验/医学研究】Poisson检验
-
-
6、重复测量方差【实验/医学研究>重复测量方差】
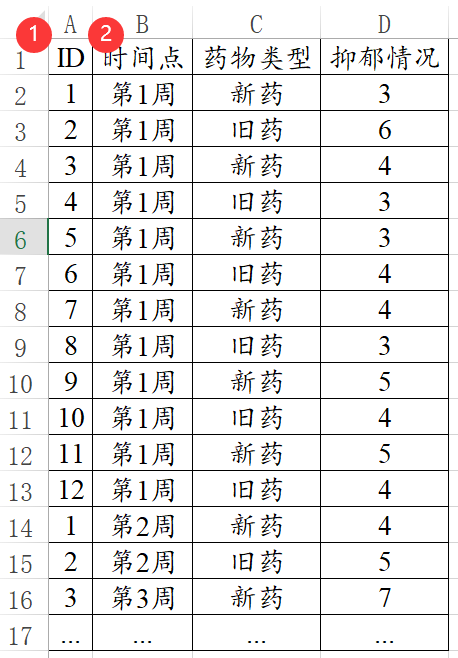
重复测量数据是指同一批样本(病例)在不同的时间点测量了多次数据,因此重复测量数据的特殊之处在于一定会有ID号(即样本或者病例号),以及时间点数据,如下图。同一个ID会有多个时间点的数据,比如下面有12个样本(12个ID号),并且测量5个时间点。那么就一定会有12*5=60行数据。同一个ID号会重复5次,同一个时间点会重复12次。
-
特别提示
-
本例中12个ID号,测量5个时间点,那么12*5=60行数据。这种数据叫做平衡数据,如果数据有测量丢失,比如ID为1的样本在第2个时间点没有数据,即少了一个数据最终为59行。那么此种叫非平衡数据,此种数据无法进行重复测量方差分析。
-
-
7、糊综合评价【综合评价>模糊综合评价】
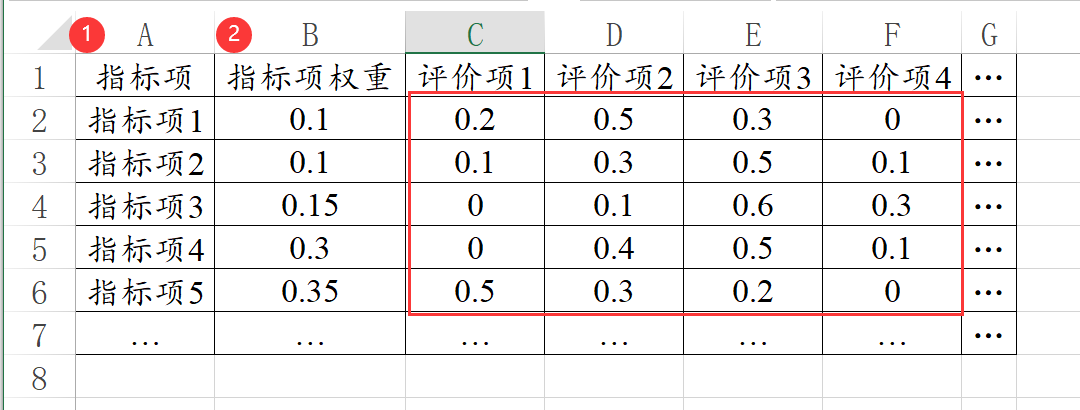
模糊综合评价研究指标项综合来看,应该属于那个评价项。1列放1个评价项(比如不满意、比较不满意、满意、非常满意之类的评价项)。
如果说各个指标项有着自己的权重,那么就需要单独用一列表示‘指标项权重值’,‘指标项权重’是可选项,如果没有此数据,默认各个指标的权重完全一致。
指标项这一列只需要研究人员自己知道就好,并不需要放入分析框中。
下图格式里面,各评价项的数字代表选择百分比,比如指标项1时,评价项1的选择比例为0.2即20%,评价项2的选择比例是0.5即50%。研究人员也可以输入选择个数而不是比例,不论是输入比例还是选择数字,SPSSAU默认都会进行归一化处理让同一个指标项下,各评价项的比例加和为1。
模糊综合评价的数据格式如下图所示:
-
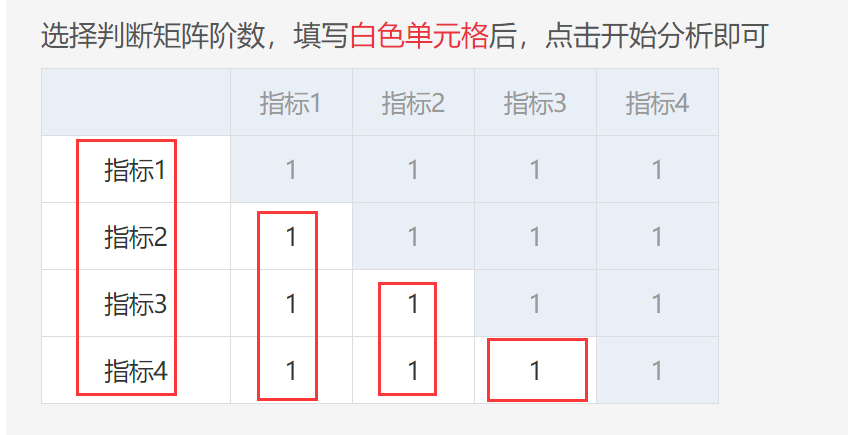
8、AHP层次分析【综合评价>AHP层次分析】
AHP层次分析法的数据格式(即判断矩阵)最为特殊,如下图,研究人员可修改指标项名称,以及白色单元格内的数字即可。判断矩阵是‘下三角’完全对称矩阵,因此‘白色’底纹处的信息变化时,‘蓝色’背景的信息会自动变化。
SPSSAU系统的问卷研究》权重模板里面,也可以进行AHP层次分析,但是数据格式要求是问卷研究时的数据格式,而非‘判断矩阵’格式。如果使用问卷研究》权重分析,SPSSAU会自动将问卷研究的数据进行转化处理成‘判断矩阵’格式后进行分析。具体可参考此页面说明: https://www.spssau.com/helps/questionnaire/quesweight.html
-
9、ARIMA模型【计量研究>ARIMA预测】
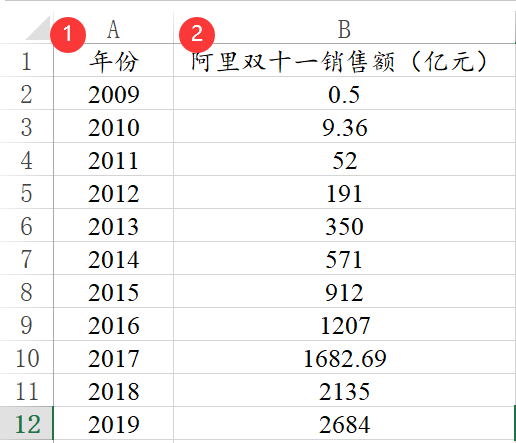
ARIMA模型是针对时间序列数据进行研究,时间序列的格式包括时间和实际分析项共两列。比如下图中年份就是时间项,“阿里双十一销售额(亿元)”就是实际分析项。分析时并不需要设置时间项,但研究人员整理的数据一定是类似如下图,从上至下的日期递增,因为算法在分析时也是默认按照从上至下递增进行计算。
-
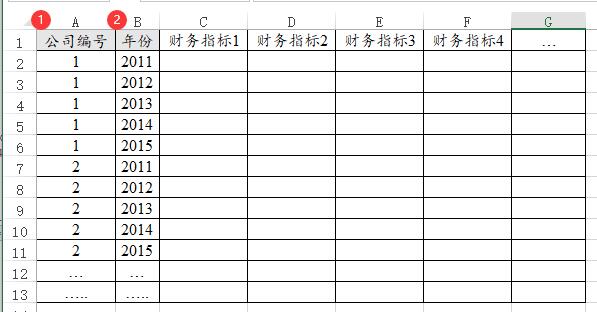
10、面板模型【计量研究>面板模型】
面板模型是针对面板数据进行分析,面板数据是一种特殊的数据格式。比如当前研究100家公司5年的财务数据。100家公司,每家5年,最终会有100*5=500行数据。
如果说100家公司全部都有完整的5年数据,即100*5=500行数据,这种叫平衡面板数据。如果说某家公司只有3年的数据,意味着有2年的缺失数据,这种叫非平衡面板数据。
使用SPSSAU进行分析时,‘个体ID’就是下图中的‘公司编号’,‘时间’就是下图中的‘年份’。‘公司编号’一般是指上市公司的股票代码,也或者只是个编号均可;‘年份’一般是指年或者时间点。‘公司编号’和‘年份’两项共同用于告诉系统当前为面板数据,通常无其它意义。
-
11、Kendall协调系数【实验/医学研究>Kendall协调系数】
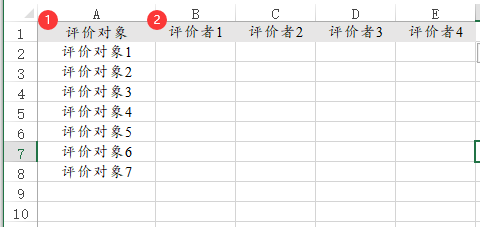
Kendall协调系数研究评价多个‘评价者’对多个‘评价对象’的一致性情况。比如4个评委对于10个选手的打分一致性,评价者即评委为4个(即4列),选手即评价对象为10个(即10行)。
数据格式上,通常1列标识1个评价者,1行标识1个评价对象。这是SPSSAU默认格式;但有时候反过来1列标识1个评价对象,1行标识1个评价者,如果是这样则需要在参数处设置为‘评价者(行)’即可。
-
12、Kappa【实验/医学研究>Kappa】
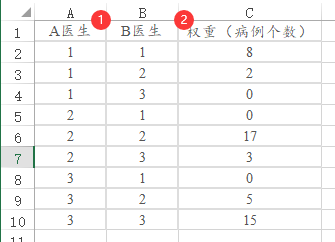
Kappa一致性系数研究2个措施(比如2种诊断方法,2个医生,2个评委)对于评价对象(比如病人、选手)的一致性情况。
数据格式上,SPSSAU共支持两种即‘加权’和‘不加权’格式。如果是‘加权’格式如下图:A列和B列分别代表2个措施(医生),单独用一列标识对应医生诊断的病例数量。‘加权’格式时,一定需要把权重加权项放入对应的框中才可以。
如果是‘不加权’格式,那么没有权重列。只需要两列原始数据即可。
-
13、灰色关联法【综合评价>灰色关联法】
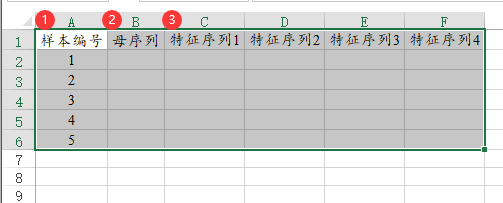
灰色关联法研究数据之间的关联程度,即特征序列与母序列的关联性情况。母序列单独使用一列标识,每个特征序列都使用1列标识。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,一般是比如年份一类的数据信息,分析时并不需要使用。
-
14、熵值法【综合评价>熵值法】
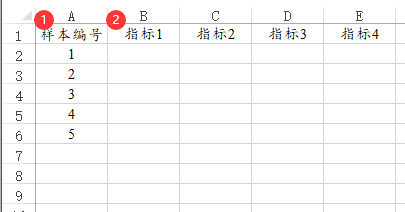
熵值法用于指标的权重情况。1个指标占用1列数据。下图中样本编号只是个编号无实际意义,用于标识下样本的ID号,一般是比如年份一类的数据信息,分析时并不需要使用。
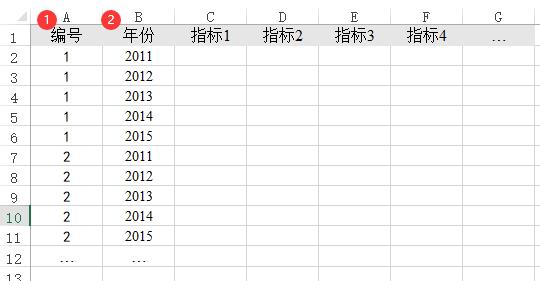
如果是面板数据希望进行熵值法,其数据格式如下图所示,比如有100家公司分别5年的指标数据,那么一共就有100*5=500行数据。数据格式上需要如此,但在分析时只需要放入‘指标列’数据即可。
-
15、熵权TOPSIS【综合评价>熵权TOPSIS】。
熵权TOPSIS法用于研究指标与理想解的接近度情况。1个指标占用1列数据。1个研究对象为1行,但研究对象在分析时并不需要使用,SPSSAU默认会从上到下依次编号。
-
16、TOPSIS【综合评价>TOPSIS】。
TOPSIS法用于研究指标与理想解的接近度情况。1个指标占用1列数据。1个研究对象为1行,但研究对象在分析时并不需要使用,SPSSAU默认会从上到下依次编号。
-
17、权重【问卷研究>权重】。
问卷研究模块中和权重计算,其包括AHP层次分析法和优序图法。1个样本为1行,1个计算权重的指标占1列数据即可。即直接使用正常的问卷研究数据即可。
-
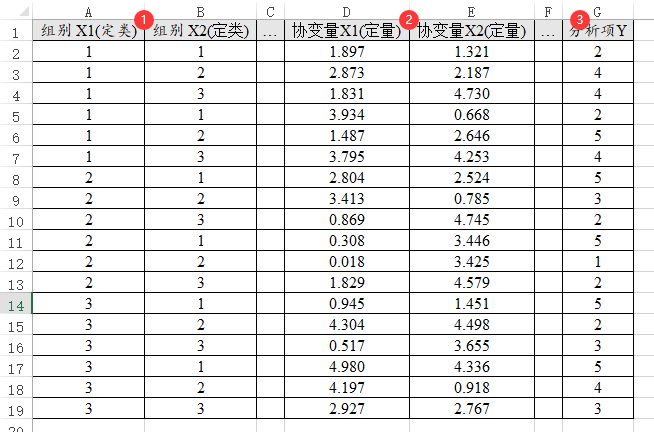
18、方差【进阶方法>双因素方差,三因素方差,多因素方差,协方差】
只要是方差分析,不论是单因素方差(通用方法>方差),也或者进阶方法中的双因素方差,三因素方差,多因素方差和协方差。其均是研究X对于Y的差异,1个X均占用1列,1个Y也占用1列,如果有协变量那么1个协变量占用1列。数据格式类似如下:
-
19、象限图【可视化>象限图】
象限图可把数据点投影到坐标中去,数据点包括X轴和Y轴两个属性,因此占用2列,以及某个数据点的意义(即标签项)也占用1列,‘标签项’是可选,如果有标签,系统会以设定好的标签进行展示点的标签信息;如果没有标签项,系统就不进行展示标签信息。数据格式类似如下:
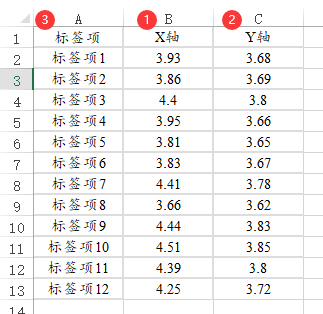
-
20、RSR秩和比
RSR秩和比可分析研究对象在‘研究指标’上的综合表现水平情况。数据格式上需要1列表示1上研究指标,1行表示1个研究对象,如下图所示:
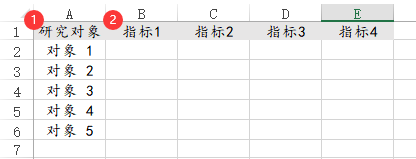
-
21、耦合协调度
耦合协调度研究不同系统之间的耦合协调情况,因此1列表示1个系统的数据,1行表示1个研究对象,其数据格式如下图所示:

-
特别提示:
-
很多时候1个系统会由多个指标构成,因此‘系统’数据并不是直接就有,而是需要使用比如熵值法或主成分分析法等得到‘综合得分’数据来表示,具体可查看对应的 耦合协调度手册。
-
-
22、Ridit分析
Ridit分析研究X与Y的差异,X是定类数据,Y通常是定距数据。SPSSAU共支持不加权和加权两种格式。如果是不加权格式,即1行代表1个研究对象(样本),其数据格式如下图所示:
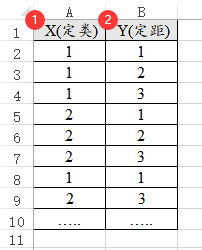
除此之外,SPSSAU进行Ridit分析时,也支持加权数据格式,即汇总数据,比如下图中X有2种情况,Y有3个情况,一种有2*3=6种组合,数据信息只有6种组别的汇总项(即加权项),分别是40,10,20,30,20,50;相当于总共有170个样本,如果是使用常规格式(即非加权格式),此时应该有170行;但加权格式则只需要6行即可表示,如下图:
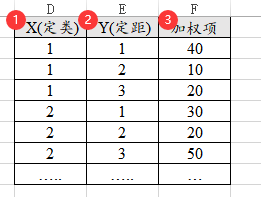
-
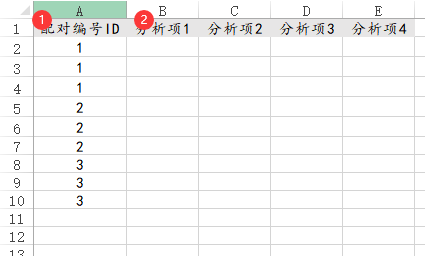
23、条件logit回归
条件logit回归通常在病例对照实例时使用,即数据具有配对性,比如一个病例和若干个对照匹配即1:1,常见是1:M(M <=3),即1个病例和1或2或3个对照匹配。那么在数据准备时就需要有‘配对编号ID’列,用于标识配对信息,其数据格式类似如下:
-
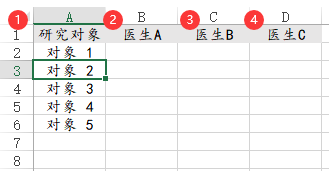
24、ICC组内相关系数
ICC组内相关系数通常可用于重测信度分析等,比如有3个医生对于5个病人的智商打分一致性。那么需要有3个医生的数据,1个医生为1列即可,其格式类似于配对数据,如下图所示:
-
25、卡方拟合优度
卡方拟合检验分析定类数据各项的占比差异情况,SPSSAU可支持两类数据格式,一种是常规格式(非加权格式),另外一种是加权数据格式。
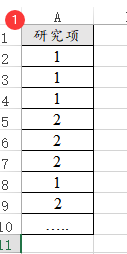
上图为常规格式(即非加权格式),一行代表一个样本,一列代表一个属性,将全部的原始数据信息列出即可。
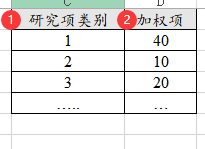
很多时候只有汇总数据,即带加权项的数据,比如下图中研究项有3种情况,每种情况时样本量分别是40,10,20;相当于总共有70个样本,如果是使用常规格式(即非加权格式),此时应该有70行;但加权格式则只需要3行即可表示,如下图。
-
26、配对Wilcoxon
配对数据的格式相对较为特殊,包括配对Wilcoxon,配对t 检验,或者配对卡方等。比如实验组和对照组数据的差异。如下图:
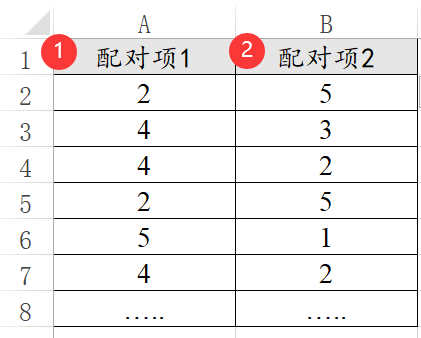
配对数据一般是在实验时使用,而且配对数据的特点为:行数一定完全相等并且只有两列。如果研究数据的行数不相等,那可能不是配对数据,如果还想对比差异,可能需要使用非参数检验。非参数检验和配对Wilcoxon的数据格式不一样,需要特别注意。
-
27、对应分析
对应分析研究多个定类数据的关系情况。使用SPSSAU问卷研究模块下的对应分析时,SPSSAU可支持两类数据格式,一种是常规格式(非加权格式),另外一种是加权数据格式。
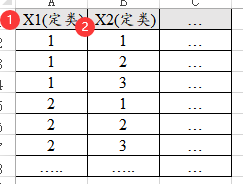
上图为常规格式(即非加权格式),一行代表一个样本,一列代表一个属性,将全部的原始数据信息列出即可。
很多时候只有汇总数据,即带加权项的数据,比如下图中X有2种情况,Y有3个情况,一种有2*3=6种组合,数据信息只有6种组别的汇总项(即加权项),分别是40,10,20,30,20,50;相当于总共有170个样本,如果是使用常规格式(即非加权格式),此时应该有170行;但加权格式则只需要6行即可表示,如下图。
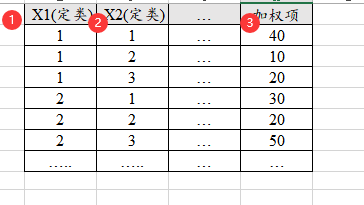
-
28、KANO模型
KANO模型研究功能/服务的需求优先级情况。其一般使用问卷形式收集数据,而且一个功能/服务会有正向题和负向题两项。并且其只支持5个选项,即数据只能是1,2,3,4,5共5个数字。1行代表1个测量样本,1列表示1个属性,类似数据格式如下图:
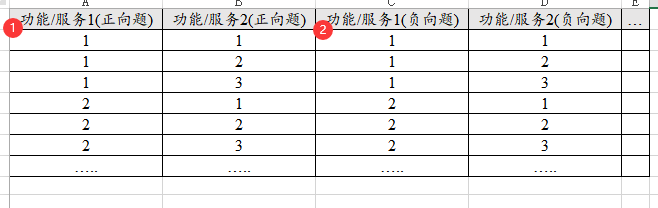
-
29、灰色预测模型
灰色预测GM(1,1)模型通常针对数量非常少的样本进行预测,如果数据带有时间项,其并不纳入分析项中,但自己整理数据时一般需要将数据依次按时间排序好录入数据,类似数据格式如下图:
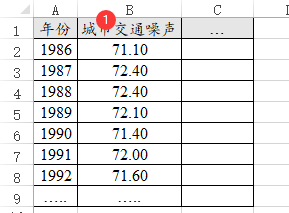
-
30、广义估计方程
广义估计方程GEE是针对纵向数据(重复测量数据或面板数据)等进行分析,因此数据中需要有一列为‘subjectID’用于标识测量对象的ID号,而且该ID号一般会重复出现多次(比如一个人同时测量了5次,则该人的ID号会出现5次),类似数据格式如下图:
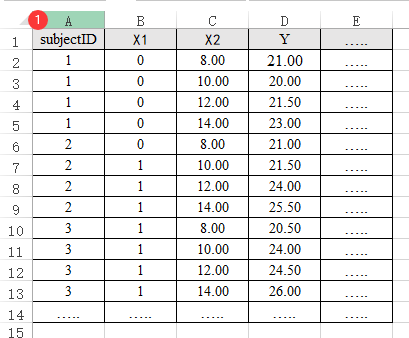
-
31、Poisson回归
Poisson回归时,如果数据中带有基数,比如‘患癌症’人数是Y,而且患癌症人数是基于某个省而言,那么基数就是‘每省的人口总数’,类似数据格式如下图:
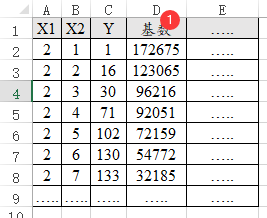
-
32、负二项回归
负二项回归时,如果数据中带有基数,比如‘患癌症’人数是Y,而且患癌症人数是基于某个省而言,那么基数就是‘每省的人口总数’,类似数据格式如下图:
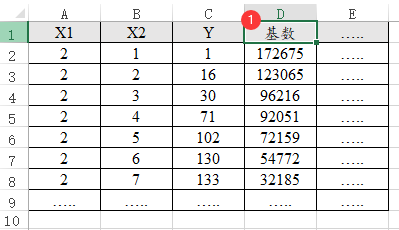
-
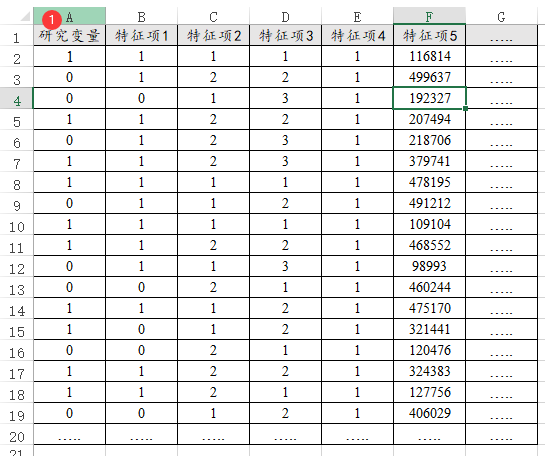
33、PSM倾向得分匹配
倾向得分匹配时,研究变量一定只能包括数字0和1,特征项的数据特征并无特别要求,类似数据格式如下图:
-
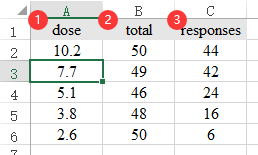
34、剂量反应
剂量反应时总共数据为3列,分别是dose, total, responses;dose表示剂量值,responses表示dose水平时出现反应的case数量,total表示某剂量水平时的总共case数量,类似数据格式如下图:
-
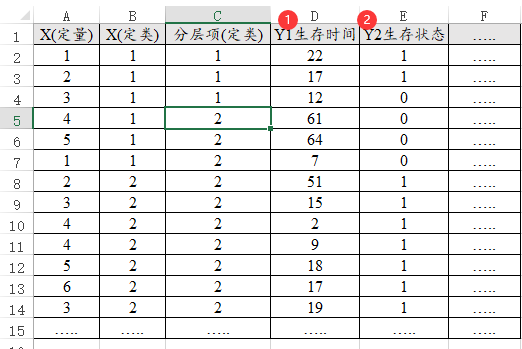
35、Cox回归
Cox回归生存分析时,因变量包括两项,分别是Y1生成时间和Y2生存状态,Y2生存状态一定只能包括2个数字分别是0和1,至于X或分层项的数据特征不固定,分层项在分析时为可选,没有也没关系,类似数据格式如下图:
-
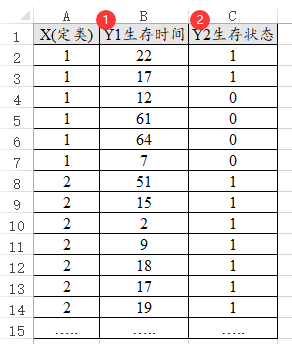
36、Kaplan-Meier
Kaplan-Meier分析时,因变量包括两项,分别是Y1生成时间和Y2生存状态,Y2生存状态一定只能包括2个数字分别是0和1,类似数据格式如下图:
-
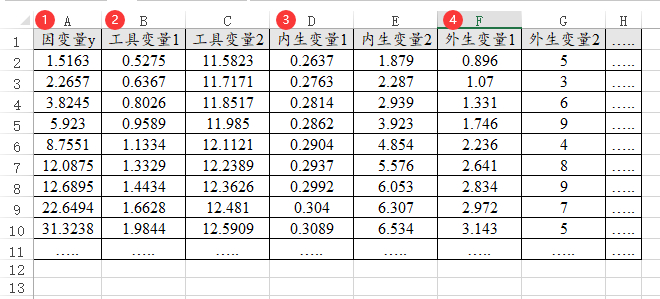
37、TSLS两阶段最小二乘回归
TSLS两阶段最小二乘回归时,包括4种类型的数据,分别是因变量1个,工具变量,内生变量和外生变量;工具变量的个数一定要大于等于内生变量的个数;外生变量可有可无,类似数据格式如下图:
-
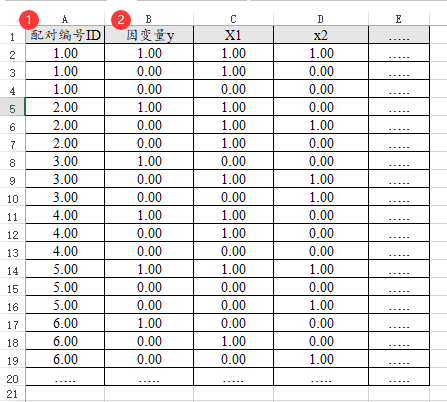
38、条件logsitic回归
条件logit(logistic)回归时,配对编号ID用于标识ID,而且是配对,因此一个ID会出现多次,比如1:1配对,那么1个ID就会出现2次(1:2配对时,1个ID就会出现3次);因变量Y一定只能包括数字0和1,类似数据格式如下图:
-
39、主成分分析
主成分分析时,一列标识1个指标,一行为1个样本;如果为面板数据,比如100家公司每家公司10年,那么就会有100*10=1000个样本,可能需要单独两列分别是公司名和年份来标识面板格式而已,但主成分分析并不区分是否面板数据,只针对指标进行分析即可,另一般分析样本量需要超出分析项(指标)的5倍,类似数据格式如下图:
-
40、因子分析
因子分析时,一列标识1个指标,一行为1个样本;如果为面板数据,比如100家公司每家公司10年,那么就会有100*10=1000个样本,可能需要单独两列分别是公司名和年份来标识面板格式而已,但因子分析并不区分是否面板数据,只针对指标进行分析即可,另一般分析样本量需要超出分析项(指标)的5倍,类似数据格式如下图:
-
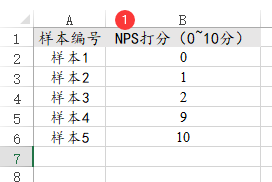
41、NPS
NPS分析时,NPS打分值(即数据)计算上需要介于0~10分共11个数字,如果原始数据为1~12分或其它,建议上传后使用“数据处理->数据编码”处理后再分析,NPS类似数据格式如下图:
-
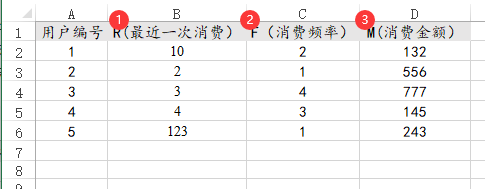
42、RFM模型
RFM模型时共需要三列数据,分别是最近一次消费间隔时间,消费频率和消费金额,最近一次消费间隔时间应该为具体的数字,而不能是日期,如果是日期数据,建议在EXCEL中处理后再上传到SPSSAU即可,类似数据格式如下图:
-
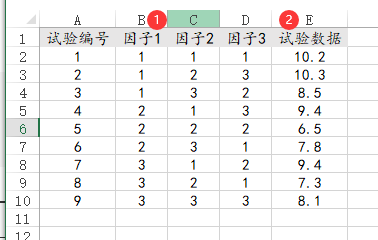
43、极差分析
极差分析是针对正交设计表格进行分析,比如进行正交设计(SPSSAU->正交实验),然后做完试验数据后得到的EXCEL表格,因子个数是由正交或实验设计决定,上传数据的格式上一定需要为因子水平编号,比如1,2,3(即第几个水平编号),上传后使用数据处理->数据标签功能,标识数字代表的水平实际意义。类似数据格式如下图:
-
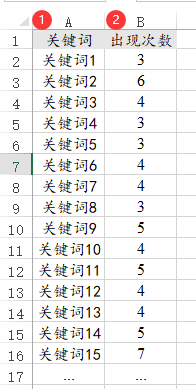
44、词云
词云一般是对关键词的图示化,SPSSAU支持两种数据格式,分别是加权格式和不加权格式。如果是加权格式:第1列是展示的关键词,第2列为出现次数,即关键词的加权值,加权格式时需要把加权项即‘出现次数’放入对应的加权框中。如果是不加权格式,那么只需要单独一列数据,即全部均为关键词,此时关键词会有很多的重复。
-
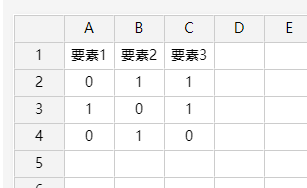
45、DEMATEL
如果是进行DEMATEL分析,直接将数据粘贴至表格中即可(或在表格中自行编辑),DEMATEL的数据格式说明为:第1行为标题,第2行起为数据,数据一定为方阵(即除标题外的数据需要行和列相等),右下三角线数据一定为0。数据格式类似下图。
-
46、ISM
如果是进行ISM分析,直接将数据粘贴至表格中即可(或在表格中自行编辑),ISM的数据格式说明为:第1行为标题,第2行起为数据,数据一定为方阵(即除标题外的数据需要行和列相等),数据中只能出现0或1,并且右下三角线数据一定为0。数据格式类似下图。
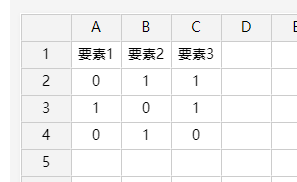
-
47、HLM模型
如果是多水平模型HLM分析,即医学研究中的HLM模型,则数据格式类似下图:group项代表研究样本的编号,特别提示该列数据一定会有非常的重复,比如下图中数字1重复几次,原因在于group就是代表多个样本都隶属于同一组(比如很多个学生都同隶属于同一个学校)。
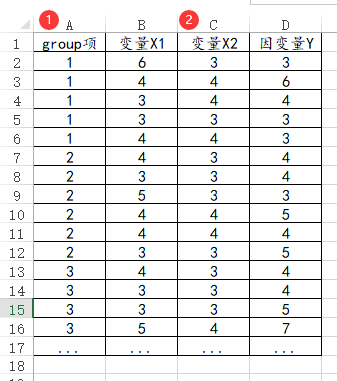
-
48、价格敏感度PSM
如果是进行价格敏感度PSM分析,即问卷研究中的PSM分析,SPSSAU支持两种数据格式,分别虽按‘价格’为标题和按‘态度’为标题的格式。下图中左侧为按‘价格’为标题的格式,1列代表1种价格点,1行代表1个样本;图中右侧为按‘态度’为标题的格式,1列代表1种态度选项(一定共为4项即4种态度),1行代表1个样本。具体是哪种格式,需要似问卷如何设计而定。
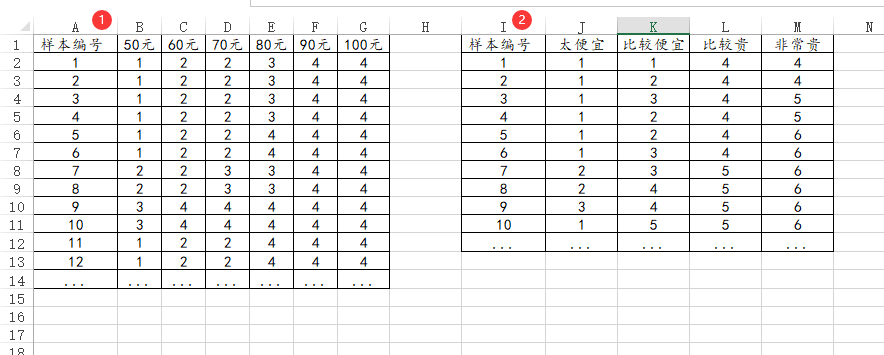
-
49、DEA数据包络分析
如果是进行数据包络DEA分析,数据格式类似下图:单独一列为决策单元DMU(如果没有,或者不放入分析‘标签’中,SPSSAU默认会称其为第1项,第2项,第3项依次类似这样)。一个指标占用一列(不论是投入还是产出指标)
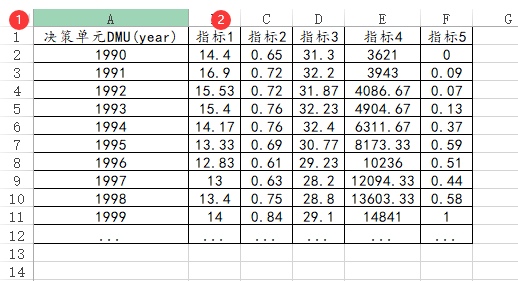
-
50、VIKOR
如果是进行VIKOR分析,数据格式类似下图:单独一列为评价对象(如果没有,或者不放入分析‘标签’中,SPSSAU默认会称其为第1项,第2项,第3项依次类似这样)。一个指标占用一列(不论是正向还是负向指标)
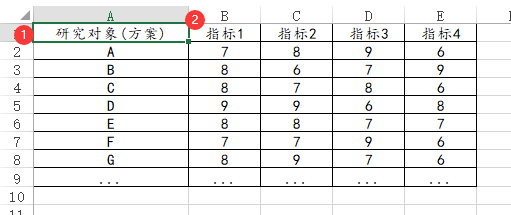
-
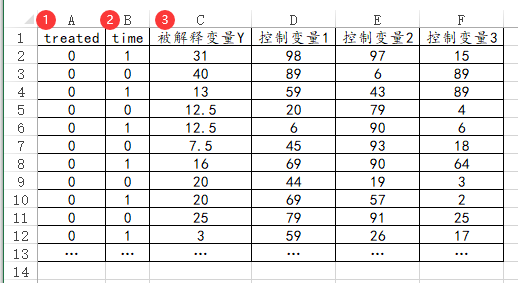
51、双重差分数据格式DID
如果是进行双重差分DID分析,那么Treated和time数据只能包括数字0或者1,并且有对应的被解释变量Y,至于控制变量可有可无,由实际研究情况而定。
如果是多期DID数据,格式类似如下图,treated只能为数字0或1,数字0标识‘控制组’,数字1标识‘实验组’;time只能为数字0或1,数字0标识‘before’(实验前),数字1标识‘after(实验后)。Treate*time即为交互项,可使用SPSSAU数据处理->生成变量->乘积得到。
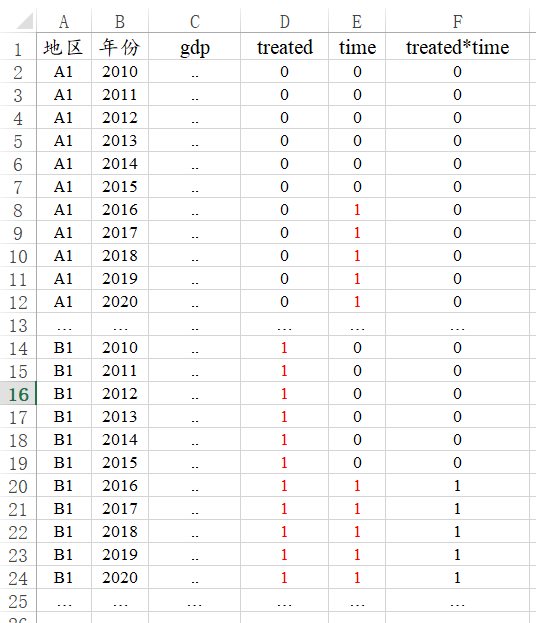
-
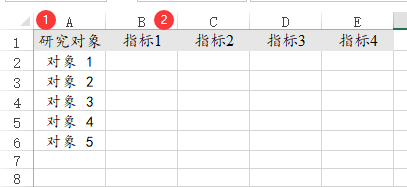
52、综合指数
计算综合指数时,数据格式类似下图:单独一列为评价对象(如果没有,或者不放入分析‘标签’中,SPSSAU默认会称其为第1项,第2项,第3项依次类似这样)。一个指标占用一列(不论是高优还是低优指标)。
-
53、障碍度
障碍度模型时,1个指标占1列数据,至于指标隶属于‘准则层’对应关系情况,研究者自行对应放置即可。以及障碍度模型时需要输入各‘准则层’和‘指标层’的权重,可点击SPSSAU‘开始分析’按钮右侧‘指标权重’按钮进行设置。
-
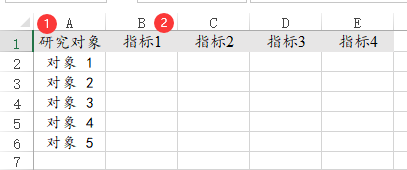
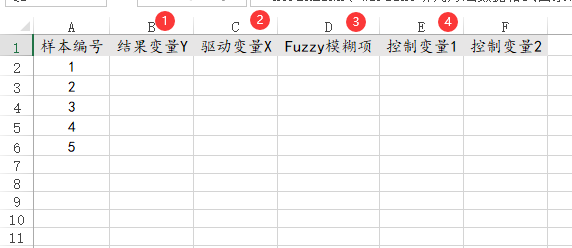
54、RDD断点
RDD断点回归时,1行代表1个样本,研究数据中一定包括结果变量Y和驱动变量X,Fuzzy模型项为可选项,控制变量可为0个或者多个。
-
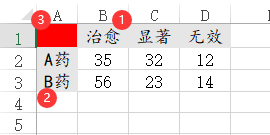
55、fisher卡方
SPSSAU医学研究模块中的fisher卡方,其格式为汇总格式,数字代表交叉项的个数,A1单元格一定是空着的。比如下图是2*2=6结构的数据,2表示A药和B药,3表示治愈、显著和无效。里面的数字代表某交叉的具体数字,比如A药并且无效的样本个数为12个。
-
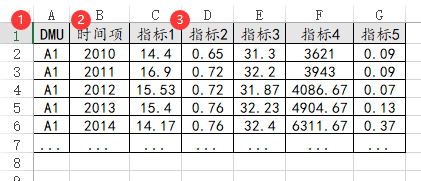
56、malmquist指数
如果是进行malmquist指数,其是计算面板数据投入产出效率的指标,因而输入数据一定是面板数据格式,即比如100个企业分别5年,即100*5=500行数据,单独一列叫DMU即企业名称,时间项即分别5年比如2020、2021、2022、2023和2024等。以及分别1个研究指标占1列数据。
-
特别提示
-
面板数据格式不能错误,比如出现同一个DMU有2个相同的时间项,也或者有的年份是100个DMU,但有的年份是99个DMU等。一定是100个DMU,分别5年,那么一定是100*5=500行数据。
-
-
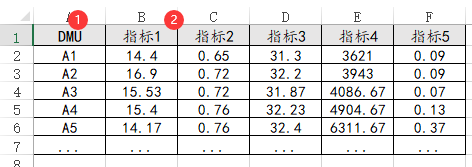
57、SBM
如果是进行SBM模型(或者超效率SBM模型),此时单独一列放DMU,其余各列放置研究指标,包括投入指标、产出指标或者非期望产出指标,与此同时,DMU列可有可无,如果有则可拖拽放入‘DMU标签【可选】’框中。
-
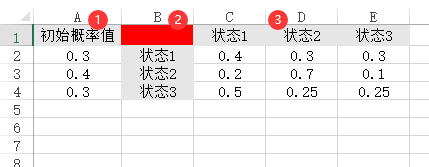
58、马尔可夫预测
如果是马尔可夫预测,通常包括两个数据,分别是‘初始概率值’和‘状态转移矩阵’。‘初始概率值’放在A列中。‘状态转移矩阵’是n*n矩阵格式,其从B列开始放入,并且B1这个单元格一定是空着的。类似如下图所示:
-
特别提示
-
比如有10个状态,那么‘初始概率值’就会有10个概率数字且加和一定为1,‘状态转移矩阵’则为10*10结构,并且状态转移矩阵的每行数字加和一定为1。
-
-
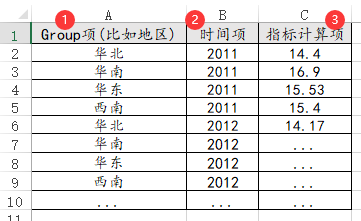
59、dagum基尼系数
如果是进行dagum基尼系数,一定需要有计算项(比如人均GDP)。至于group项和时间项可有可无,但通常二者均会有。Group项一般为地区,时间项一般为年份。Group项放入后会进行组间PK,放入时间项时,会循环输出不同时间项的计算结果。
-
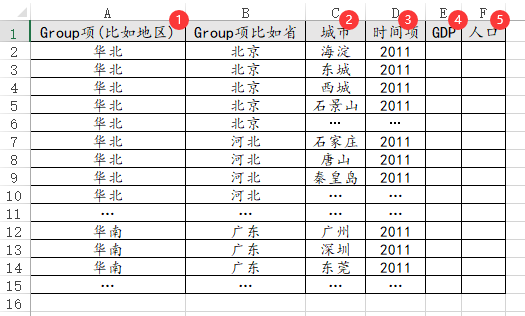
60、泰尔指数
如果是进行泰尔指数计算,通常会涉及group项,比如区域(华北、华南、华东、西南、东北)其层次最高,也或者区域的下一层次省份group(北京、天津、河北、上海、浙江等),以及具体最小单位粒度城市,及其对应的GDP/人口信息数据等。一行代表一个最小粒度1个时间点(通常1年)的数据。类似结果如下图:
-
特别提示
-
如果只有1个group项,比如区域->省,区域->城市,省->城市;如果有2个group项,比如区域->省->城市,省->城市->区县。Group的层次是相对的,但最小粒度单位为最细分的数据,其决定有多少行数据。比如区域->省这种结构时,省是最小粒度单位共31个省并且5年,那么就有31*5=155行数据。
-
-
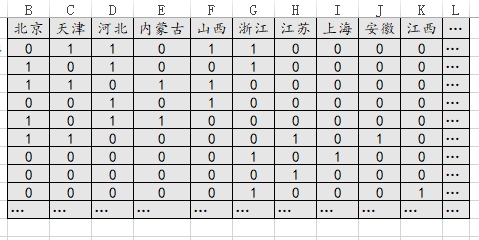
61、莫兰指数Moran
如果是进行莫兰指数研究,那么其关键是提供‘空间权重矩阵’,即n*n格式的数据,通常是01格式,0代表不相邻1代表相邻,此时右下三角线上的数据一定是0,因为其表示自己与自己的距离。关于更多权重矩阵的内容,建议查阅SPSSAU对应的帮助手册说明。
-
62、多维尺度MDS
如果是进行多维尺度MDS分析,SPSSAU共支持两种数据格式,分别是n*n数据格式和原始数据格式。n*n格式时:右下三角线数字一定是1其表示自己,其余数字表示交叉研究对象之间的距离度(数字越大代表距离越远即越不相似)。
如果是原始数据格式,那么单独1列为‘研究对象名称’,接着放置各项指标数据,比如中国各城市的文化相似情况,研究对象为城市,共有31个省市,使用5个指标来衡量文化,分别是经度、纬度、全年平均气温、全年平均降雨量、全年平均有太阳天数(数字大小均代表该指标下的具体数据,数字的差值越大代表距离越远)。

-
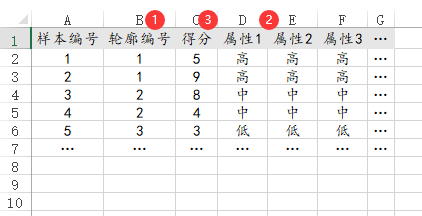
63、联合分析
如果是进行联合分析,其通常是先正交试验后得到‘轮廓’即各属性水平组合虚拟产品,然后进行调研,得到各样本对于各轮廓的打分情况,即‘得分’数据。每个轮廓均有对应着属性的水平值。
放入SPSSAU系统进行分析时,系统只关注于‘轮廓得分’数据和属性数据。但研究数据时是以样本编号作为最小粒度单位,比如调研100个人,每个人只针对1种‘轮廓’进行打分,那么就有100行数据。如果是100个人,每人针对2种‘轮廓’进行打分,那么就有100*2=200行数据。
-
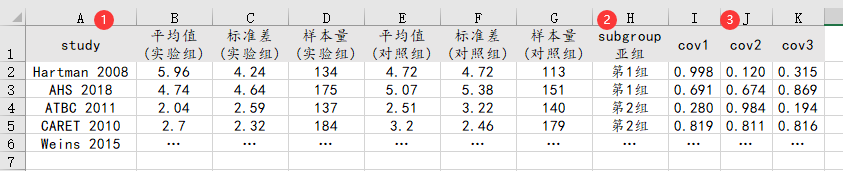
64、MEAT分析
如果是进行META荟萃分析,那么每个META分析的格式均可能不同。但通常相同的地方在于均有Study,如下图所示。以及如果有subgroup亚组或者协变量cov,那么subgroup亚组可直接为文字即可,类似下图,协变量直接放入对应Study的数据即可。但多数情况下并没有协变量,此时留空即可,如果没有subgroup亚组也直接留空即可。
-
65、Apriori关联分析
如果是进行apriori关联分析,其数据格式较为特殊,比如有1000个购物订单,每名购物订单可能有不同的购买商品,那么整理为两列,第1列为订单编号,第2列为具体商品,注意1行仅包括1个订单的1个商品,通常情况下1个订单有多个商品比如5个商品,那么重复5行即可。如果从数据库中下载出来数据为1个订单为1行,而且购买商品信息有多个时以固定的符号比如逗号分开,那么可使用SPSSAU提供的‘ apriori_spssau_dataformat_trans.xlsm。 ’这个EXCEL宏文件(有代码的EXCEL文件)进行处理,一键整理成SPSSAU支持的数据格式。

-
66、空间计量
如果是进行空间计量模块分析,包括空间OLS、空间滞后SLM模型、空间误差SEM模型、空间滞后误差SAC模型、空间杜宾SDM模型、空间杜宾误差SDEM模型、自变量空间滞后SLX、空间面板模型等,其通常均需要两个数据,分别是空间权重数据和分析数据,需要上传两个数据到SPSSAU中,然后针对‘分析数据’进行分析,但是在分析的时候需要下拉选择‘空间权重数据’。
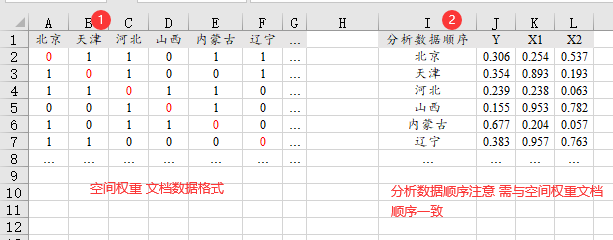
‘空间权重数据’以数据文件的形式上传到SPSSAU中,其格式如下图左侧所示,第1行是名称比如省份的名称,从第2行起为n*n的空间权重具体数据,需要提示的是,空间权重数据一定是n*n格式,并且一定是右下三角线为数字0,并且完全对称才可以,这是空间权重矩阵的基本要求。‘分析数据’的顺序需要与‘空间权重数据’的顺序保持一致,比如空间权重数据是北京、天津、河北这样的顺序,那么分析数据的顺序也需要这样对应起来。
如果是空间面板数据,比如31个省5年(2020到2024年),那么分析数据为31*5格式,但空间权重依旧是31行,那么原理上:其顺序对应应该是(2020年 北京/天津/河北/山西/内蒙古/辽宁..-> 2021年 北京/天津/河北/山西/内蒙古/辽宁.. -> 2022年…),简单来说需要自己先对分析数据依次按 时间和ID进行升序排序(且ID的顺序需要与空间权重的顺序保持一致)。面板数据的格式需要特别注意:如果ID为文字数据,在上传到SPSSAU时会自动替换成数字并且进行编码成数字,比如北京编码成数字3,数学算法上会认为北京即为第3个,但空间权重的顺序是北京为第1列,这样就会错位对应不上。因而建议研究者上传的ID列数据为‘数字’切记为‘数字’非文字上传。