
-
HLM模型(hierarchical linear model,分层线性模型)有着多种称呼,可称作多水平模型,层次线性模型,或者混合效应模型,随机效应模型等。普通的线性回归模型研究X对于Y的影响,而HLM模型也研究X对于Y的影响,但是其考虑了group的聚集性因素(即考虑组内相关不独立问题)。
比如研究‘入学成绩X’对于‘中考成绩Y’的影响,个体是学生,学生隶属于学校group,并且样本数据来源于几个学校。那么不同学校(即group层面)之间的情况时‘入学成绩X’对于‘中考成绩Y’的影响时很可能不一样(比如好学校时可能影响幅度更高),如果希望将学校因素考虑进入,此时学校就是一个聚集性因素group,诸如此类研究时即可使用HLM模型。
HLM模型时涉及到两个重要的专业术语,分别是‘固定效应’和‘随机效应’,其说明如下表:
效应 说明 备注 固定效应 X对Y的影响时,不会随着group变化而变化 比如‘学生入学成绩’对于‘中考成绩’的平均影响情况 随机效应 完全在group层面考虑的因素,跟随group而变化 比如‘学生入学成绩’对于 ‘中考成绩’的影响时不同group即学校间的差异性 固定效应是指做HLM模型时,不涉及group干扰时的影响关系研究;随机效应可指在group层面时的影响关系情况,更进一步说明例子如下表:
场景 说明 完全不考虑group 此种情况直接就是线性回归即可 考虑group,但不考虑group层面的效应 有固定效应项,无随机效应项 考虑group,并且考虑group层面的效应 有固定效应项,也有随机效应项 如果完全不考虑group,即不考虑‘聚集性’问题,那么直接使用线性回归即可,并不需要使用HLM模型,HLM模型就是处理‘聚集性’问题的一种进阶方法;如果说使用HLM模型,并且在分析时只考虑个体效应不需要考虑group层面的效应,即只有固定效应项并无随机效应项;如果说使用HLM模型,并且在分析时考虑个体效应的同时还考虑group层面的效应,即包括固定效应项和随机效应项。
HLM模型案例
-
1、背景
当前有一项研究,研究样本为65所学校共计4059名学生,研究内容为学生入学成绩对于最终成绩的影响情况,由于学生样本来源于65所不同的学校,而且不同学校层次有着较大区别,因此需要将学校(即group项)的聚集性纳入考虑范畴中。研究数据中涉及的字段如下说明:
字段名称 说明 学校代码 学校的代码,取值为1~65 学号id 每个学生的学号id 最终成绩 学生成绩(已进行正态变换) 入学成绩 学生入学成绩(已进行正态变换) 性别 数字1代表男,数字0代表女 学校类型 学校类型,1为男女混合,2为男校,3为女校 入学成绩 学校学生入学考试平均成绩(已进行正态变换) -
2、理论
HLM模型研究是对传统回归模型的进一步精细分析,研究者可深入探讨数据的变异是否在高层次(group)中存在着聚集性。一般分析时分为两个步骤如下说明:
第一步:首先只考虑固定效应,即不纳入随机效应;然后通过结果中的ICC值判断【group层面】因变量的变异幅度(ICC值越大意味着【group层面】因变量的变异幅度越大,一般ICC值较小比如小于0.1时,意味着【group层面】因变量的变异力度较低,意味着聚集性较弱,此时可考虑直接放弃HLM模型改用常见的回归模型即可);
第二步:如果说ICC值较大(比如大于0.1时),此时可进一步探究‘随机效应’对【group层面】带来的变异情况,加入group层次水平的研究项,深入探究它们对于【group层面】变异的解释情况。比如第一步中得到的ICC值为0.2,第二步之后 得到的ICC值为0.1,减少为0.2-0.1=0.1,也即说明新加入‘随机效应’项会对【group层面】产生0.1(10%)的变异解释力度。
-
特别提示:
-
HLM模型时,研究思路并不完全固定,完全由研究者的研究目的而定;
-
group的数据格式需要特别注意,比如本案例中某个学校(id=1)有73个个体学生,那么id=1就要对应重复73次。
-
-
3、操作
本例子中操作上第一步先不放入‘随机效应’项,即只放入如下图所示:
在第一次分析之后,发现ICC值为0.144较大,即意味着【group层面】即学校中考成绩的变异为14.4%。因此考虑纳入‘随机效应’项,将‘入学成绩’项纳入模型中,以深入探究‘入学成绩’对于【group层面】‘中考成绩’的解释力度(即入学成绩会对中考成绩有影响,但是在不同学校group间是否有差异性)。
-
4、SPSSAU输出结果
SPSSAU共输出4个表格,分别‘模型基本情况’,‘固定效应参数估计’,‘随机效应协方差估计结果’,‘随机效应参数估计的相关矩阵’,分别说明如下:
表格 说明 模型基本情况 描述模型分析样本基本情况等 固定效应参数估计 展示固定效应参数估计值,包括回归系数和p 值等 随机效应协方差估计结果 展示随机效应协方差估计值,包括ICC值,SD值和p 值等 随机效应参数估计的相关矩阵 展示随机效应间的相关关系情况,意义较小 -
5、文字分析
本案例共进行了两次。第一次时不纳入‘随机效应’项,得到结果分别如下:

上表格展示出本次研究的总样本数量是4059个,而且有65组,即group项有65个不同的数字(即65所学校),其中某学校最少只有2个学生个体样本,某学校最多有198个学生个体样本,平均来看每所学校为62.4个学生个体样本。以及HLM模型使用REML似然法估计,log似然值为-4681.13。
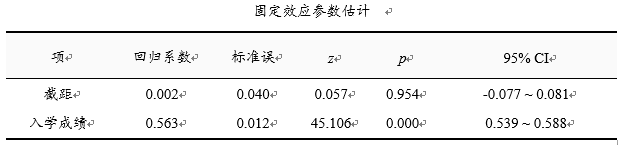
‘固定效应参数估计’表格展示固定效应情况,即‘入学成绩’对于‘中考成绩’的影响,上表可知:回归系数值为0.563>0,并且此路径呈现出0.01水平的显著性(z =45.106,p =0.000 <0.01),因而说明入学成绩会对中考成绩产生显著的正向影响关系,即学生入学成绩越高,那么学生中考成绩也会越高。
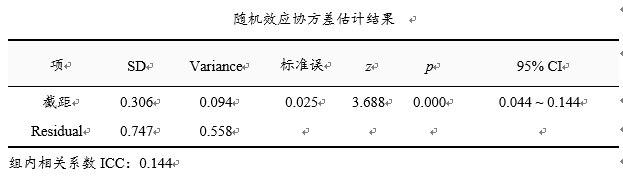
由于第一次分析结果中并没有纳入‘随机效应’分析项,因此‘随机效应协方差估计结果’只会有截距和残差这两项,通过此两项可计算得到ICC值,计算公式为:组内相关系数ICC=截距项方差 / (截距项方差+残差项方差),即组间方差 /(组间方差 + 组内方差)。上表格显示ICC为0.144(此值相对较大),意味着【group层面】中考成绩的变异为14.40%。
与此同时,截距的回归系数值(variance或sd值均可称回归系数值)为0.094且呈现出显著性,意味着【group层面】之间的中考成绩有着明显的差异性。由于ICC值较大和【group层面】之间有着差异性,因此接下来再进一步纳入‘随机效应项’进行深入考虑,考虑‘随机效应项’对于【group层面】上的中考成绩变异的解释情况。
接着将‘入学成绩’这个学校水平上的数据作为‘随机效应项’纳入模型中,因而第2次分析的操作如下图:
第2次分析的结果分别如下面4个表格所示:
此表格信息并没有变化,不再赘述。
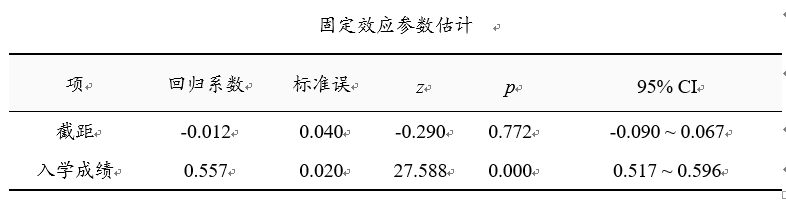
‘固定效应参数估计’表格展示固定效应情况,即‘入学成绩’对于‘中考成绩’的影响,上表可知:回归系数值为0.557>0,并且此路径呈现出0.01水平的显著性(z =27.588,p =0.000 <0.01),因而说明入学成绩会对中考成绩产生显著的正向影响关系,即学生入学成绩越高,那么学生中考成绩也会越高。
-
特别提示:
-
如果说进行过多次HLM模型分析,一般固定效应的分析只以最后一次结果为准即可。
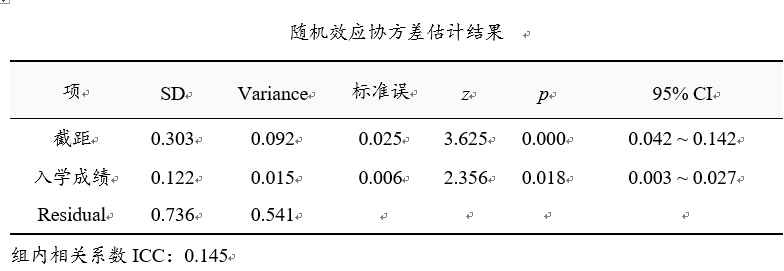
在纳入‘入学成绩’这一‘随机效应’项之后,从上表可以看出:ICC值由第1次分析时的0.144上升到0.145,即增加幅度为0.001,也即说明‘入学成绩’可以提高【group层面】即学校层面‘中考成绩’的变异幅度为0.1%,此比例相对非常低可以基本可以忽略。
截距项呈现出0.01水平的显著性(z=3.625,p=0.000 <0.01),即意味着不同【group层面】即学校层面之间的中考成绩有着差异性。与此同时从上表格看到:‘入学成绩’这一‘随机效应’项呈现出显著性(z =2.356,p =0.018<0.05),即意味着‘入学成绩’对于中考成绩的影响时,不同【group层面】即学校层面时有着差异性。
即最终得到结论:【group层面】即学校层面之间的中考成绩确实有着差异性(z=2.356,p=0.018 <0.05),而且‘入学成绩’对于‘中考成绩’的影响时(z=2.356,p=0.018<0.05),会有着【group层面】即学校之间的差异性。
-
特别提示:
-
如果希望研究某随机效应项的加入,带来【group层面】(本案例为学校)中考成绩的解释力度变化,那么可使用计算公式为:(Coef_intercept1 – Coef_intercept2)/ Coef_intercept1【Coef_intercept表示第n次‘随机效应协方差估计结果’表格中‘截距’项的回归系数】,本案例中第1次分析得到的值为0.094,第2次为0.092,即为(0.094-0.092)/0.094=2.12%,即‘入学成绩’可以解释【group层面】即学校层级的平均成绩差异2.12%的原因。

‘随机效应参数估计的相关矩阵’表格展示随机效应项间的相关关系情况,比如上表格中0.494指随机效应截距项与‘入学成绩’间的相关情况,可理解为【group层面】学校间成绩差异与‘入学成绩’间的相关关系情况。该值较大,因此并不需要设置‘随机效应协方差为0’,如果该值较小比如小于0.2,可考虑设置模型中‘随机效应协方差为0’打勾即假定没有协方差关系。
-
-
6、剖析
涉及以下几个关键点,分别如下:
-
HLM模型分析思路如何?
-
HLM分析思路上并没有固定标准,通常是第1步不纳入‘随机效应项’,结合ICC值和随机效应表格中的截距项显著性,判断【group层面】的变异是否存在,如果存在则纳入‘随机效应项’后深入挖掘‘随机效应项’带来【group层面】的变异情况等;
-
疑难解惑
-
HLM模型的数据格式是什么样的?
-
HLM模型的数据格式 可点击查看
-
HLM模型中ICC值的意义是?
-
HLM模型时,ICC的计算公式为:组内相关系数ICC=截距项方差 / (截距项方差+残差项方差),即组间方差 /(组间方差 + 组内方差),该指标值代表着【group层面】差异幅度。
-
涉及几个名词的意义说明?
-
在HLM效应分析时,涉及到专业名词包括固定效应,随机效应等,说明如下表格:
| 名词 | 备注说明 |
| 固定截距 | 因变量Y的平均水平 |
| 固定斜率 | X对于因变量Y的平均影响水平 |
| 随机截距 | 不同group对于因变量Y的差异情况,即组间方差 |
| 随机斜率 | X对于因变量Y影响时,不同group之间是否有着差异性 |
-
标准误计算说明:z 或t 检验?
-
HLM模型时标准误的计算时,不同软件的计算方式并不同,并且可能使用t 检验或者z 检验,SPSSAU当前使用z 检验。