
灰色关联分析法通过研究数据关联性大小(母序列与特征序列之间的关联程度),通过关联度(即关联性大小)进行度量数据之间的关联程度,从而辅助决策的一种研究方法。
-
灰色关联分析通常包括以下五步。
-
第一步:确定母序列和特征序列,且准备好数据格式;
-
第二步:针对数据进行无量纲化处理(通常情况下需要);
-
第三步:求解母序列和特征序列之间的灰色关联系数值;
-
第四步:求解关联度值;
-
第五步:对关联度值进行排序,得出结论。
-
特别提示:
-
针对第1步:母序列是指标准值,特征序列用于研究与母序列之间的关联关系;如果没有单独提供,SPSSAU默认以特征序列的最大值作为母序列值;
-
针对第2步:通常情况下数据的量纲(单位)并不相同,因此需要进行标准化处理,常见的处理方式分别是:标准化和初值化。二者的选择上并没有明显的界限划分,建议可结合实际情况对比选择即可。
-
特别提示:灰色关联分析法对于数据格式要求严格,请参考下表格:
| 年份 | 国内生产总值 | 第一产业 | 第二产业 | 第三产业 |
| 2000 | 1988 | 386 | 839 | 763 |
| 2001 | 2061 | 408 | 846 | 808 |
| 2002 | 2335 | 422 | 960 | 953 |
| 2003 | 2750 | 482 | 1258 | 1010 |
| 2004 | 3356 | 511 | 1577 | 1268 |
| 2005 | 3806 | 561 | 1893 | 1352 |
-
上表格为灰色关联分析法的数据格式要求,比如研究第一产业,第二产业,第三产业分别与国内生产总值之间的灰色关联关系,因此国内生产总值称之为‘母序列’,第一产业,第二产业和第三产业称之为‘特征序列’。单独使用一列即年份标识出具体某年的数据,但是年份并不需要参与计算,但输出关联系数值时可能需要一列标识值,SPSSAU默认以比如“第1项,第2项”类似的标识进行标出。
-
除此之外,需要提示用户,总共6年的数据一定需要对应排序好,比如2000年一定是放在最前面。原因在于如果使用初值化这种标准化方式会涉及到对应计算。
SPSSAU分析结果表格示例如下:
| 关联系数结果 | |||
| 项 | 第一产业 | 第二产业 | 第三产业 |
| 第1项 | 1.000 | 1.000 | 1.000 |
| 第2项 | 0.919 | 0.890 | 0.912 |
| 第3项 | 0.739 | 0.884 | 0.756 |
| 第4项 | 0.631 | 0.665 | 0.795 |
| 第5项 | 0.388 | 0.546 | 0.898 |
| 第6项 | 0.333 | 0.403 | 0.618 |
| 关联度结果 | ||
| 评价项 | 关联度 | 排名 |
| 第一产业 | 0.668 | 3 |
| 第二产业 | 0.731 | 2 |
| 第三产业 | 0.830 | 1 |
灰色关联分析法
-
1、背景
当前公司研究国内生产总值分别与第一产业,第二产业或者第三产业之间的灰色关联性情况,以研究出国内生产总值受哪个行业的影响更大。一共为2000~2005共6年的数据,国内生产总值为‘母序列’,第一产业,第二产业或者第三产业为‘特征序列’,整理得到的数据如下所示:
年份 国内生产总值 第一产业 第二产业 第三产业 2000 1988 386 839 763 2001 2061 408 846 808 2002 2335 422 960 953 2003 2750 482 1258 1010 2004 3356 511 1577 1268 2005 3806 561 1893 1352 2、理论
灰色关联分析时一般需要找出标准参考值(即‘母序列’),然后通过对比‘特征序列’与‘母序列’的近似程度(即关联度),近而通过关联度大小表述‘特征序列’与‘母序列’间的关联强度情况。其分析一般分为五步分别为:
-
第一步:确定母序列和特征序列,且准备好数据格式;
-
第二步:针对数据进行无量纲化处理(通常情况下需要);
-
第三步:求解母序列和特征序列之间的灰色关联系数值;
-
第四步:求解关联度值;
-
第五步:对关联度值进行排序,得出结论。
3、操作
本例子中已经确认好母序列和特征序列,并且准备好数据,标准化方式采用‘初值化’,操作如下。
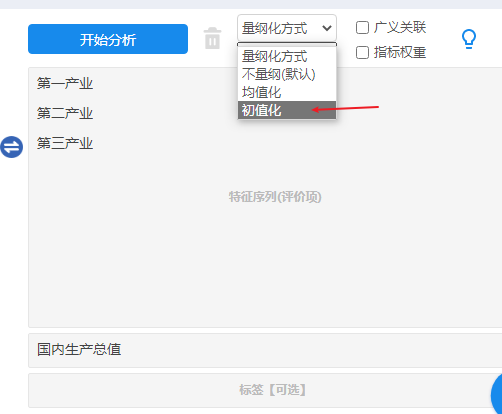
4、SPSSAU输出结果
关联系数结果 项 第一产业 第二产业 第三产业 第1项 1.000 1.000 1.000 第2项 0.919 0.890 0.912 第3项 0.739 0.884 0.756 第4项 0.631 0.665 0.795 第5项 0.388 0.546 0.898 第6项 0.333 0.403 0.618 上表格展示关联系数值,关联系数的目的在于计算得到最终关联度。下表格展示关联度结果。
关联度结果 评价项 关联度 排名 第一产业 0.668 3 第二产业 0.731 2 第三产业 0.830 1 5、文字分析
关联系数结果 项 第一产业 第二产业 第三产业 第1项 1.000 1.000 1.000 第2项 0.919 0.890 0.912 第3项 0.739 0.884 0.756 第4项 0.631 0.665 0.795 第5项 0.388 0.546 0.898 第6项 0.333 0.403 0.618 从上表可知,针对3个评价项(第一产业, 第二产业, 第三产业),以及2000~2005共六年数据进行灰色关联度分析,并且以国内生产总值作为“参考值”(母序列),研究3个评价项(第一产业, 第二产业, 第三产业与国内生产总值的关联关系(关联度),并基于关联度提供分析参考,使用灰色关联度分析时,分辨系数取0.5,结合关联系数计算公式计算出关联系数值,并根据关联系数值,然后计算出关联度值用于评价判断。
-
特别提示
-
上表格中第1列‘项’,是由SPSSAU默认生成的,其即代表2000到2005共6个年份数字
关联度结果 评价项 关联度 排名 第一产业 0.668 3 第二产业 0.731 2 第三产业 0.830 1 结合上述关联系数结果进行加权处理,最终得出关联度值,使用关联度值针对6个评价对象进行评价排序;关联度值介于0~1之间,该值越大代表其与“参考值”(母序列)之间的相关性越强,也即意味着其评价越高。从上表可以看出:针对本次3个评价项,第三产业的综合关联度最高(关联度为:0.830),其次是第二产业(关联度为:0.731),第一产业与国内生产总值之间的关联程度相对最低(关联度值为0.668)。
6、剖析
-
特别提示
-
灰色关联分析对于数据格式要求严格,请按照事例进行,母序列或特征序列均分别为一列;
-
如果没有放置母序列,SPSSAU默认会以特征序列的最大值作为母序列值。
-
灰色关联分析时,数据一定需要大于0,原因在于如果小于0进行计算时会出现‘抵消’现象,并不符合灰色关联分析的计算原理。如果出现小于0数据,建议作为空值处理或者填补(SPSSAU异常值功能)。
-
SPSSAU使用邓聚龙教授提出且使用最为广泛的‘邓氏灰色关联法’算法。
-
关于数据无量纲化方法分别是均值化和初值化,二者并无固定使用标准,初值化对数据格式要求更严格,SPSSAU建议使用均值法。
疑难解惑
-
母序列是否需要标准化处理?
-
灰色关联法分析时,通常首先需要对数据进行无量纲化处理,一般如果数据全部均大于0则使用‘均值化’较多,可选这初值化。共有两种方式可进行无量纲化处理。第1种方法是:SPSSAU数据处理>生成变量功能里面,需要针对母序列和特征序列均一并进行。第2种方法是直接使用SPSSAU的参数下拉设置即可(默认是不处理,可选这初值化和均值化)。
-
母序列是什么意思?
-
母序列是指标的参照对比项,比如研究5个指标与母序列的关联程度,通常研究者需要自己提供母序列数据。如果没有放置母序列数据,SPSSAU默认会将特征序列的最大值,即‘每行的最大值’作为母序列数据。
-
只有三级指标数据无二级指标数据,如何计算二级指标的关联情况?
-
如果只有三级指标数据但无上一级(二级指标)数据,此时如何计算二级指标灰色关联情况呢,思路上一般可以将三级指标汇总成对应的二级指标,使用主成分分析法。
-
多次使用主成分分析,并且保存得到‘成分得分’,使用主成分得分来表示对应的二级指标数据;
-
为什么分析样本量小于实际样本量?
-
如果分析时出现‘分析样本量’小于样本量,有3种可能。1是免费版(免费版仅分析前100行数据);2是做过‘筛选样本’功能(即主动设置只分析其中一部分数据);3是原始数据中有缺失数据(系统右上角‘我的数据’处可查看原始数据,也可下载原始数据等)。
-
灰色关联法时初值化和均值化的选择?
-
灰色关联法时,一般在分析前可进行量纲化处理(建议以文献为准)。量纲化处理方式有非常多种,比如标准化,归一化,初值化,均值化等等。一般来说,灰色关联法分析的数据均大于0,而且数字较大,那么此时使用‘均值化’较多;如果说数据的第1项有特别的意义,比如第1项是1978年的Gdp,后面的项都想将1978年作为一个参考基准点,那么此时量纲化处理方式选择为‘初值化’较好。至于选择某种量纲化方式,并没有固定标准,一般以文献为准。实际研究中,‘均值化’处理方式相对较多。
-
SPSSAU灰色关联 分辨系数值如何设定?
-
默认分辨系数值为0.5(绝大部分情况下均应为0.5),如果研究者有特殊需求可自行修改分辨系数值。
-
灰色关联法初值化时,第一行数据中有数字0,则会出现null?
-
如果使用初值化量纲处理方式,‘初值化’的原理为数据除以第一行数据,因此第一行数据中不能出现数字0,如果出现数字0则会导致结果为null。
-
SPSSAU如何计算绝对关联度,相对关联度和综合关联度?
-
在SPSSAU进行灰色关联度分析时,选中‘广义关联’参数按钮,即可对应输出广义关联度指标值,包括绝对关联度,相对关联度和综合关联度。
-
SPSSAU进行灰色关联分析时‘权重项’的意义?
-
如果设置权重项,SPSSAU会首先对设置的权重项进行归一化处理,然后在计算关联系数时,自动乘上权重值,并且最终关联度值也是基于计算后的关联系数。
-
灰色关联法时加入权重值?
-
如果在灰色关联法分析时设置各研究项的权重值,即意味着计算灰色关联系数和灰色关联度时会对应乘上权重值。并且系统会首先对设置的权重值进行归一化处理后计算。另如果不设置(默认情况下),各项的权重值均为1。
-
分析结果中提示“预览前100项数据结果”?
-
SPSSAU中进行某些分析时,比如vikor/灰色关联法/topsis/熵权topsis/耦合协调度/综合指数时,并且分析样本量过大导致需要输出非常多结果时,此时结果仅输出前100项数据结果进行预览。此时可通过以下两步得到全部结果。
-
第1步:在‘开始分析’按钮右侧选中‘保存结果值’,系统将指标值存储在原始数据文档中,并且以不同的标题名称进行标识;
-
第2步:分析完成后,右上角‘我的数据’下载该数据文档,即将全部数据下载出来使用。