信度分析剖析
一、 信度系数说明
信度分析是用于测量数据真实可靠性程度的研究方法。其可分为以下几种测量形式,分别为文字描述和信度研究方法共两处,如下所述:
-
1、文字描述证明数据可靠性:
-
使用文字详细描述数据的收集和处理过程,比如如何收集数据(比如数据中设置作弊题进行甄别),以及在收集数据过程中如何防范不真实数据,在数据收集完成后对数据进行何种清理,比如将回答同一答案的数据设置为无效样本等。通过科学客观地描述数据收集过程,即使用文字描述数据收集和处理过程等,用于证明数据的真实可靠,即说明数据具有信度。
2、 使用信度研究方法
-
信度研究方法通常有四种,分别是Cronbach α信度系数,折半信度系数,McDonald's ω信度系数和theta信度系数。
-
默认情况下,使用信度分析方法进行信度分析时,其有一定适用性,一般情况下是针对问卷量表类数据进行分析,其它类型的数据不能进行信度研究方法使用。
-
一般情况下,使用最多的为Cronbach α信度系数,如果是经典量表题,并且某个维度的测量项较多(比如大于5项)时,也可使用折半信度系数进行研究;Cronbach α信度系数和折半信度系数,此两种方法的原理是基于‘相关或变异’进行测量,即同一维度时各测量项之间应该有着较高的相关关系,如果数据真实,那么各测量项间的相关性也会较高,基于‘相关性’原理最终得到信度系数。
-
除此之外,还可使用另外两种测量方法,分别是McDonald's ω信度系数和theta信度系数,此两种测量方法的测量原理是利用‘信息浓缩’(内部原理为因子分析且提取为1个因子),各个测量项隶属于同一维度且数据真实,那么它们应该浓缩出较高的信息,结合因子分析输出的载荷系数loading值等进一步计算,最终得到指标值。
-
-
二、 信度分析计算公式和解读
1、关于Cronbach α信度系数,其计算公式如下:
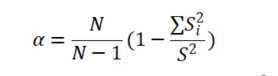
其中N为测量个数(即放入SPSSAU的分析项个数),
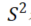 表示数据求和后的总变异,
表示数据求和后的总变异,
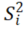 表示第i项的数据变异,
表示第i项的数据变异,
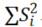 表示各项数据变异求和。从公式可以看出,测量项个数会对Cronbach α信度系数产生影响关系,分析项个数越多时,Cronbach α信度系数可能会越高。测量项个数最少为2个,此时信度系数相对可能会最低。
表示各项数据变异求和。从公式可以看出,测量项个数会对Cronbach α信度系数产生影响关系,分析项个数越多时,Cronbach α信度系数可能会越高。测量项个数最少为2个,此时信度系数相对可能会最低。
2、关于折半信度系数,其计算公式如下:
折半系数涉及到Spearman-Brown系数和Guttman Split-Half系数。其中Spearman-Brown系数又分为等长和不等长两种计算。分别说明如下:
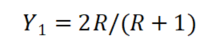
如果是等长,此时等长Spearman-Brown系数计算公式如上,其中R代表拆分成两部分数据(先将数据拆分成两部分,然后分别求和,分别得到两列数据)的相关系数值。如果不等长,即拆分成两部分分析项的数量不一致(即奇数项时),此时不等长Spearman-Brown系数计算公式如下。
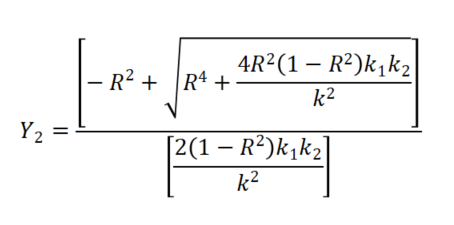
上公式中R为两部分数据的相关系数,k1和k2分别代表两部分数据分别的分析项个数,k=k1+k2。

与此同时,SPSSAU还有提供Guttman Split-Half 系数,其也可用于测量信度。计算公式如下:上式中,
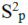 表示整体求和部分的方差;
表示整体求和部分的方差;
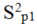 和
和
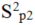 分别代表第1部分,第2部分方差。
分别代表第1部分,第2部分方差。
-
3、关于McDonald's ω信度系数,其计算公式如下:
McDonald's ω信度系数的计算原理是利用因子分析浓缩信息,然后得到loading载荷系数值,进而计算。计算公式如下:
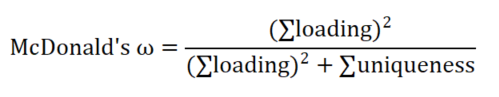
上式中loading为载荷系数值,uniqueness为1-loading^2。从上式可知,loading值整体绝对值越大时,McDonald's ω信度系数值也会越高。
-
4、关于theta信度系数,其计算公式如下:
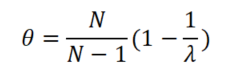
上式中N为分析项个数,
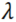 为最大特征根值。从上式可以看到,当分析项个数越多时,theta信度系数很可能会越大,而且最大特征根越大,theta信度系数值也会越大。
为最大特征根值。从上式可以看到,当分析项个数越多时,theta信度系数很可能会越大,而且最大特征根越大,theta信度系数值也会越大。
-
三、信度分析操作
关于SPSSAU进行信度分析,其操作路径为“问卷研究模块”->信度。
四、信度系数解读
-
关于信度系数的衡量标准上,通常情况下,信度系数值高于0.8,则说明信度高;信度系数介于0.7~0.8之间;则说明信度较好; 信度系数介于0.6~0.7;则说明信度可接受; 信度系数小于0.6;说明信度不佳。并且此标准通常适用于上述4个研究指标,包括Cronbach α信度系数,折半信度系数,McDonald's ω信度系数和theta信度系数。
-
但从公式中可以看出,测量项很可能影响信度系数值,当测量项个数较少时,通常信度系数值受公式影响,其会‘相对较少’,建议实际研究中一般维度对应着4~7个测量项较为适合。
-
实际中可能会出现真实数据,但是数据依旧不达标的现象,具体处理和原因查看等,可点击查看。
-
最后关于信度的测量上,有时也可考虑使用比如相关系数,SPSSAU的kappa一致性系数,也或者kendall协调系数等方法进行,各个测量方法有其对应的适用场景,比如kappa系数或者kendall协调系数,更加适用于专家打分类数据,具体均可在SPSSAU医学/实验研究模块中找到对应的方法。
-