异质性和稳健性等名词探讨
-
1.总述
在当前统计数据分析时,对于研究结论的质量关注度越来越高,正是基于此原因,有必要对下述名词进行关注。分别是:异质性、稳健性、鲁棒性、敏感性和控制变量,该五个名词的意义如下表格所述:
名词 定义 异质性(Heterogeneity) 其关注研究数据内部的差异性,比如不同学历样本时结论是否有差异 稳健性(Robust) 其关注研究结论的稳定性,比如换某个分析方法后结论是否一致 鲁棒性(Robust) 其关注出现异常据等时,结论的稳定性 敏感性(Sensitivity) 其关注某参数或假设变化时,结论的反应程度 控制变量(Control Variable) 其通常指可能对模型带来干扰的变量,比如性别、年龄、学历等基本信息项 就一般而言,当前对于异质性和稳健性的关注度较高,异质性研究不同数据时结论的稳定性,比如上市公司和非上市公司时,X对于Y的影响关系是否有着差异性。而稳健性更多关注于X对于Y的影响时,在不同情况(比如不同数据,或者不同方法等)时,结论是否有着稳定性。异质性和稳健性有着较多的共同点,比如其均可观察研究模型的稳定性情况,但二者的角度并不相同,异质性出发点是关注不同数据组别时结论稳定性,稳健性出发点是关注模型的稳定性。
鲁棒性与稳健性基本一致,均是关注结论的稳定性,但鲁棒性更多倾重于数据中存在异常值或违反一些数学模型假设时结论的稳定性,鲁棒性与稳健性的落角点完全一致,只是关注的具体点并不相同。
控制变量指一些可对模型带来干扰影响的变量,如果不关注此类变量,那么结论可能有着偏差,自然也会影响到稳健性,以及多数情况下控制变量也可能带来异质性问题,比如是否上市公司(或者类似性别这类个体属性项),其很可能是控制变量,因为上市和非上市公司(也或者男和女)时,X对于Y的影响情况可能不同,其会对模型带来干扰,因而将其放入模型中以减少其对于模型的干扰。
-
2.关于异质性
异质性关注研究数据内部的差异性,比如不同学历样本时结论是否有着差异性。那么关于异质性的分析上,通常有着以下方式:
处理方式 描述 亚组分析 比如分别过滤出上市公司或者非上市公司样本,然后分别进行分析,并且对比结论情况 控制变量法 比如将可能的干扰因素纳入模型中 Meta分析 Meta分析本身就需要重点考虑异质性问题,Meta分析是单独的文献汇总评价方法,其对异质性关注度很高 HLM混合模型 社会学中可能考虑HLM混合模型 其它 发现差异纳入为调节变量进行调节作用分析等 异质性是一种数据内部差异性的思想,其并非一个固定的研究方法,并且不同领域的处理方式也并不相同。多数情况下,亚组分析较为常见,亚组分析是指将数据拆分为不同组别时分别进行分析,然后对比结论的一致性,如果结论基本一致那么说明没有异质性问题。比如研究X对于Y的影响,使用线性回归,并且‘是否上市公司’可能是异质项,那么此时可先筛选出‘是上市公司’做一次线性回归,再筛选出‘非上市公司’做一次线性回归。汇总两次分析结果进行对比,如果结论基本一致意味着没有异质性。在SPSSAU系统中,可能使用到‘筛选样本功能’,类似如下图:
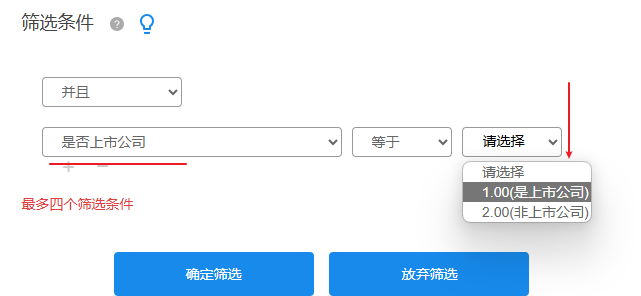
亚组分析是异质性问题最常用的方法。当然在研究时,有时候将可能的异质性纳入模型中,其也可在一定程度上控制异质性。Meta元分析,其是一种对文献结论汇总进行综合评价的方法,其对于异质性问题的关注度极高,研究者可关于SPSSAU对于Meta分析模型内容。社会学研究中,如果其为嵌套数据,那么则可能使用HLM分层模型(混合模型)等考虑异质性问题,但在社会学相关研究中,其首先已经确定好很可能具有异质性,本身就使用HLM模型等在处理异质性问题。当然一般情况下,如果发现具有异质项,那么其为新发现,研究角度上可进一步研究该异质性的调节作用情况等。
-
3.关于稳健性
稳健性关注研究结论的稳定性,这是其核心诉求,稳健性是一种思想,并非一种研究方法。那么如何证明研究结论具有稳健性呢?通常有着以下方式:
处理方式 描述 亚组分析 比如分别过滤出上市公司或者非上市公司样本,然后分别进行分析,并且对比结论情况 更换数据集 比如有1000个样本,仅随机筛选出500个进行分析,并且对比结论情况 更换模型变量法 比如将‘毛利润’改成‘净利润’分析,也或者删除或者增加个别变量后,也或者加入和不加入控制变量情况时,对比结论差异 更换研究方法 比如使用OLS回归研究时,可改用robust回归;也或者使用有序logit回归时改用线性回归,然后对比结论差异情况 更换参数法 比如OLS回归时是否使用稳健标准误参数时,结论差异情况 其它 比如研究正态性时,可使用检验法或者图示法等 稳健性检验是确保研究结论的稳定性,其是一种思想并非一个研究方法,其目的是保障研究的准确可靠性。具体如何研究稳健性,其没有固定标准。通常情况下,亚组分析和更换数据集,也或者更换模型变量,该3种方法使用最为常见。比如预期‘是否上市公司’两种样本集时,结论可能有着差异,那么就分拆出上市公司和非上市公司这两组数据,分别进行模型构建,并且汇总模型结果进行对比,如果发现结论基本一致,那就说明具有稳健性。具体在SPSSAU中的操作上,可能使用到SPSSAU的筛选样本功能,与此同时,如果是使用线性回归研究X对于Y的影响,那么可使用SPSSAU分组回归方法,分组回归就是线性回归的亚组分析。
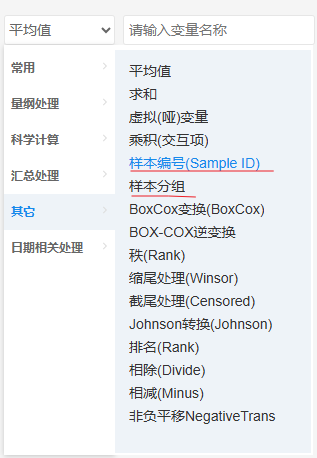
更换数据集的思想就是换不同的数据时,结论是否具有稳定性,至于具体如何换不同数据,没有固定标准,其需要似研究具体情况而定,也或者直接进行随机筛选样本。如果需要使用随机筛选样本,可先对样本进行随机编号,比如1000个样本先随机编号1到1000,然后筛选出编号为1到500即500个样本进行分析即可(当然也可对样本随机分成两组然后筛选出第1组或者第2组后进行分析)。随机编号(或样本分组)功能可查看SPSSAU-》生成变量功能,如下图所示:
更换模型变量法,通常是指将核心的研究变量换成一个比较接近意义的变量,然后再次分析进行对比,此处难点为找到一个比较接近意义的变量。但有一种较为常见的做法是对核心变量做一些数据处理,比如取自然对数处理,其意义不变化,但数字已经发生变量,这种处理方式通常是减少比如异方差问题,但也可似为一种模型稳健性检验的方式。
除此之外,更换研究方法或者更换参数法,其更多是从数学模型的视角上分析稳健性,比如社会学中研究X对于Y的影响,可以使用线性回归,也可以使用路径分析。也或者有序logit回归类似,也可考虑使用线性回归。也或者OLS回归的时候可分别使用是否稳健标准误,通过修改数学模型的参数情况,分别对比研究结论的稳定性情况。
稳健性检验的处理方式可能还有很多,不同文献的做法不尽相同,比如研究数据正态性时,可使用图示法也或者检验法等。
总而言之,使用不同的处理办法,然后发现结论依旧稳定,那就说明已经关注稳健性检验问题。
-
4.关于鲁棒性
稳健性和鲁棒性,二者均是关注结论的稳定性,但鲁棒性更多倾重于数据中存在异常值或违反一些数学模型假设时结论的稳定性,鲁棒性与稳健性的落角点完全一致,只是关注的具体点并不相同。
如果数据中有异常值,一种做法是不处理让数学模型去适应它,另一种做法是进行异常值处理后再次分析,如果两种做法后研究结论依旧保持着较强的一致性,那么就说明数据具有鲁棒性。当然有时候鲁棒性也单指数学模型的稳定性对异常值(或对样本量)不敏感等。比如社会学研究中,方差分析理论上要求数据具有方差齐、正态性,但事实上即使不满足该前提条件,结论依旧可靠和可信,即说明方差分析这一数学研究方法具有鲁棒性。
-
5.关于敏感性
本文主要关注于异质性和稳健性,但敏感性也是相关名词。敏感性其关注某参数或假设变化时,结论的反应程度。其在Meta元分析是有较多使用,也或者其它领域也有单独的处理。本文暂不讨论。
-
6.关于控制变量
控制变量指可能对模型带来干扰的变量,比如性别、年龄、学历等基本信息项。既然控制变量可能对模型带来干扰,那么就可能影响到模型的稳健性,因此在研究稳健性入手时,首先可能想到的就是那些控制变量是异质变量,即比如不同性别(男和女时)情况下研究结论是否具有稳定性;当然是否加入控制变量两种情况下,模型的结论是否具有一致性,也是很常见的稳健性检验方式。当然讨论异质性时,也可从常见的控制变量入手。如果在研究时并不讨论异质性或稳健性问题,通常也可将一些可能的变更直接纳入到模型中,控制变量并非核心研究变量,但其是可能带来干扰的项,因此一般纳入到模型中就好。从软件角度来看(比如SPSSAU平台中),其并没有“控制变量”这样的名词,“控制变量”就是自变量,所以直接放入“自变量X”框中就好。 如果是方差分析时,‘控制变量’通常也称作‘协变量’。
如果数据中有异常值,一种做法是不处理让数学模型去适应它,另一种做法是进行异常值处理后再次分析,如果两种做法后研究结论依旧保持着较强的一致性,那么就说明数据具有鲁棒性。当然有时候鲁棒性也单指数学模型的稳定性对异常值(或对样本量)不敏感等。比如社会学研究中,方差分析理论上要求数据具有方差齐、正态性,但事实上即使不满足该前提条件,结论依旧可靠和可信,即说明方差分析这一数学研究方法具有鲁棒性。