
KANO模型由东京理工大学教授狩野纪昭(Noriaki Kano)发明,其用于分析用户对于各类需求的排名偏好情况,其在企业产品需求调研,市场研究中有着广泛的应用。KANO模型的数据一般通过问卷进行收集,而且有着严格的规范格式。比如当前针对手机功能/服务做需求调研,共头脑风暴出10项功能/服务,分别是:投影功能, 左右手模式, 超级快充, 取消SIM卡, 3D投影, 照片搜索, 自动美颜, 防盗加锁, 遥控器, 暖手宝, 望远镜, 显微镜。现希望分析出该10种功能/服务的需求态度和优先顺序等。问卷设计格式类似如下:
-
对一款拥有 “投影功能”的手机的态度?【正向题 】
-
A不喜欢 B能忍受 C无所谓 D理应如此 E喜欢
-
对一款不具有“投影功能”手机的态度?【反向题】
-
A不喜欢 B能忍受 C无所谓 D理应如此 E喜欢
总共有10个功能/服务,每项‘功能/服务’均由2个题表示,分别是正向题和反向题。正向题指用户对于‘拥有该项功能/服务’的偏好态度情况,负向题指用户对于‘不具有该项功能/服务’时的偏好的态度情况。共10个功能/服务,每项均2个题测量,总计共有20个题进行测量。
在收集完成数据后,切记使用数字标识出各项的意义,不论是正向还是负向,均为1分代表‘不喜欢’,2分代表‘能忍受’,3分代表‘无所谓’,4分代表‘理应如此’,5分代表‘喜欢’。即第1个选项为1分,第2个为2分,依次下去。
模型得到后即为后续的分析,KANO模型将功能/服务的态度属性分为六类,分别是如下:
| 属性名称 | 属性特征 |
|---|---|
| 魅力属性A | 超出用户预期的功能/服务,该功能/服务完善程度高,用户满意度会明显上升,如果没有该功能/服务时,用户满意度下降不明显 |
| 期望属性O | 有某功能/服务会提升满意度,没有会使满意度下降 |
| 必备属性M | 有某功能/服务不会提升满意度,但没有会使满意度下降 |
| 无差异属性I | 有和没有某功能/服务均不影响满意度 |
| 反向属性R | 没有某功能/服务满意度会更高 |
| 可疑结果Q | 用户没有很好理解某问项或误答 |
很明显,魅力属性,期望属性和必备属性应该优先满足用户。无差异属性可以忽略,反向属性不应该提供。
-
特别提示:
-
KANO模型的问卷设计有着严格的规范,一定需要按此规范进行;
-
KANO模型共分为六种属性,最终应结合功能/服务的属性特征划分优先级。
KANO模型案例
-
1、背景
当前有一项关于手机功能/服务的需求调研,共头脑风暴出10种功能/服务,分别是投影功能, 左右手模式, 超级快充, 取消SIM卡, 3D投影, 照片搜索, 自动美颜, 防盗加锁, 遥控器, 暖手宝, 望远镜, 显微镜。以及共收集有效数据为100份,现希望通过KANO模型分析出该10种功能/服务的态度情况,为企业产品研发提供建议。
-
2、理论
针对每个功能/服务点,KANO模型共分为正向题和负向题两个方向进行收集数据。并且在得到数据后,将功能/服务映射到六个属性上面,映射关系如下图:
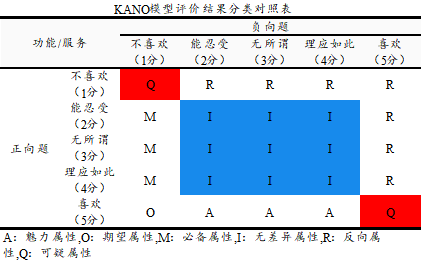
比如正向题选择喜欢,反向题选择无所谓,那么映射到中间I区域即‘无差异属性’。
-
特别提示:
-
上表格中分值一定要标好,即1分代表‘不喜欢’,2分代表‘能忍受’,3分代表‘无所谓’,4分代表‘理应如此’,5分代表‘喜欢’。因为SPSSAU完全按照此分值进行映射。
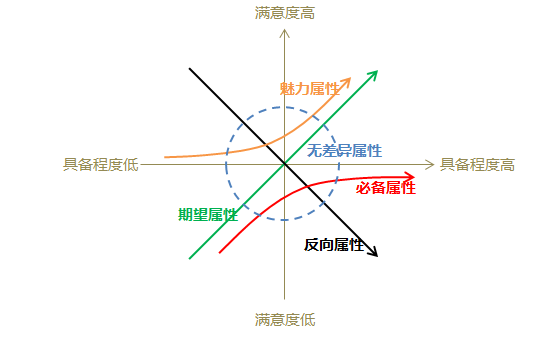
以及六种属性的特征情况,即具备程度与用户满意度之间的关系情况如下图:
-
第一:魅力属性时,某功能/服务完善程度高,用户满意度会明显上升,如果没有该功能/服务时,用户满意度下降不明显;
-
第二:期望属性时,某功能/服务完善程度高,用户满意度会上升,如果没有该功能/服务时,用户满意度会下降;
-
第三:必备属性时,某功能/服务完善程度高,用户满意度上升不明显,如果没有该功能/服务时,用户满意度会明显下降;
-
第四:无差异属性时,某功能/服务与满意度之间无明显关系;
-
第五:反向属性时,某功能/服务完善程度高,用户满意度反而会下降。
-
-
3、操作
本例子中共有10项功能/服务,操作如下图:
-
4、SPSSAU输出结果
SPSSAU共输出3个表格和2个图。3个表格分别是: KANO模型评价结果分类对照表, KANO模型分析结果汇总,KANO模型分析结果汇总-数字结果,KANO模型属性特征图,和Better-Worse系数图。
-
KANO模型评价结果分类对照表:正向和负向题选项交叉,与属性之间的映射关系。切记数字分值一定需要参照表格进行,即1分代表‘不喜欢’,2分代表‘能忍受’,3分代表‘无所谓’,4分代表‘理应如此’,5分代表‘喜欢’。因为SPSSAU完全按照此分值进行映射。
-
KANO模型分析结果汇总:此表格为核心输出表格,即得出各功能/服务对应的属性占比,分类结果,Better和Worse值;
-
KANO模型分析结果汇总-数字结果:该表格展示出各功能/服务对应属性的数量,分类结果,Better和Worse值;
-
KANO模型属性特征图:该图展示属性的特征情况,即某功能/服务具备程度与满意度之间的关系特征情况;
-
Better-Worse系数图:可通过该图查看Better(满意影响力)和Worse(不满意影响力)之间的关系特征情况,并且按照平均的worse值和平均的better值为界该图可分为四个象限。其横坐标为Worse的绝对值,纵坐标为Better值,因而无论横向还是纵向,均是越大越好。第一象限为期望属性,Better值高,Worse值绝对值高。该象限的功能/服务应优先满足;第二象限为魅力属性,Better值高,Worse值绝对值低。该象限的功能/服务应优先满足;第三象限为无差异属性,Better值低,Worse值绝对值低。该象限的功能/服务通常不提供;第四象限为必备属性,Better值低,Worse值绝对值高。该象限的功能/服务一定需要满足。
-
-
5、文字分析
本次案例结果解读如下:
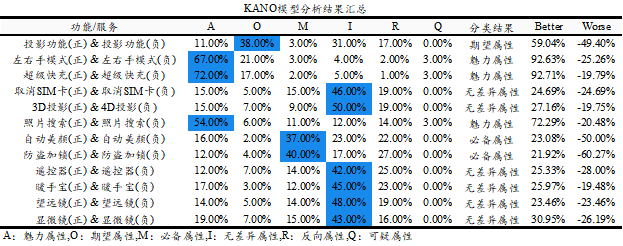
从上表可以看出,10个功能/服务的属性情况,按某属性占比最高作为划分界限,最终结果为期望属性包括:投影功能共1项;魅力属性包括:左右手模式,超级快充和照片搜索共3项;必备属性包括自动美颜和防盗加锁共2项;其余6项为无差异属性。
通常情况下产品开发的优先级为:必备属性>期望属性>魅力属性>无差异属性。因而手机厂商应该首先开发必备属性即自动美颜和防盗加锁共2项功能;并且应当抓紧开发期望属性即投影功能,而且应该对魅力属性进行开发并且越完善越好,分别包括左右手模式,超级快充和照片搜索共3项。
除此之外,Better(满意影响力)= (A+O)/(A+O+M+I),该指标介于0 ~ 1之间,值越大说明敏感性越大,优先级越高;Worse(不满意影响力)= -1 * (O+M)/(A+O+M+I),该指标介于-1 ~ 0之间,值越小说明敏感性越大,优先级越高。也可结合Better-Worse系数图直观查看10项功能/服务的特征情况。Better-Worse系数图是从10项功能的对比角度来分析属性分布情况,本次分析Better-Worse系数图如下图:
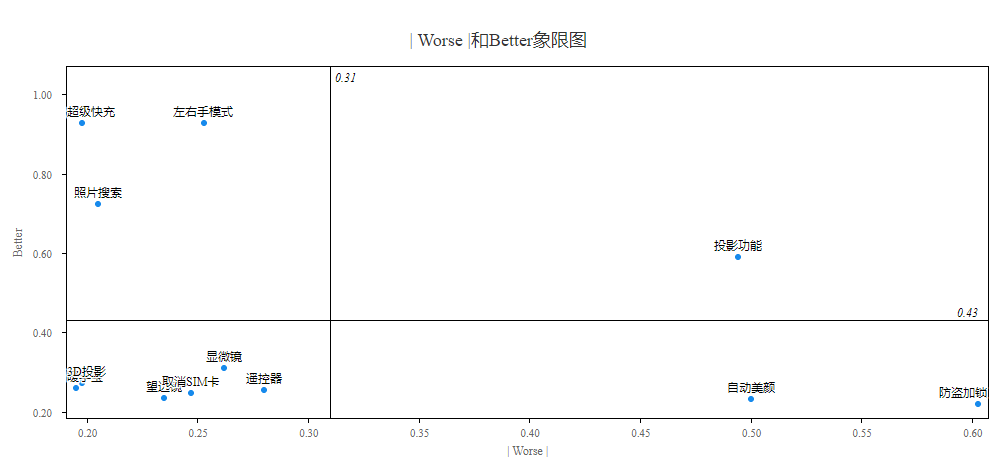
Better-Worse系数图的横坐标为Worse的绝对值,纵坐标为Better值,因而无论横向还是纵向,均是越大越好。
-
第一象限为期望属性,Better值高,Worse值绝对值高。该象限的功能/服务应优先满足,本次研究对应为‘投影功能’;
-
第二象限为魅力属性,Better值高,Worse值绝对值低。该象限的功能/服务应优先满足,本次研究对应着‘超级快充’,‘左右手模式’和‘照片搜索’;
-
第三象限为无差异属性,Better值低,Worse值绝对值低。该象限的功能/服务通常不提供;
-
第四象限为必备属性,Better值低,Worse值绝对值高。该象限的功能/服务一定需要满足,本次研究对应着‘自动美颜’和‘防盗加锁’这两项。
-
-
6、剖析
涉及以下几个关键点,分别如下:
-
KANO模型的问卷设计有着严格的规范,一定需要有正向和负向题分别测试某‘功能/服务’的态度,并且分值一定要标好,即1分代表‘不喜欢’,2分代表‘能忍受’,3分代表‘无所谓’,4分代表‘理应如此’,5分代表‘喜欢’。因为SPSSAU完全按照此分值进行映射。
-
KANO模型共分为六种属性,最终应结合功能/服务的属性特征划分优先级。包括使用属性特征占比分布表格和Better-Worse系数图。
-
疑难解惑
-
提示数据必须是1-5!
-
KANO模型时,针对每个功能/服务,均由正向和负向题测量,而且只有5个选项,因此只能使用1,2,3,4,5分别标识5个选项。建议使用频数分析进行查看数据是否有异常值。
-
KANO模型数据格式应该如何?
-
KANO模型时,SPSSAU潜在的数据格式要求,数字越大代表越认可的意思,不论是正向题还是反向题,均要求数字越大代表越认可。请一定注意数据格式是否正确,如果不是这样,可使用数据处理->数据编码进行处理后,然后再进行分析。
-
Kano模型表格和图(better-worse图)出现小许不一致性?
-
KANO模型时可使用表格查看功能/服务对应的属性,同时也可使用better-worse图查看。二者目的相同都是查看功能/服务对应的属性,但计算的角度并不相同因而偶尔会出现属性归类不一致的情况(此类情况非常正常),建议研究者综合对比选择其中一个角度分析使用即可。
-
SPSSAU进行KANO模型输出的图标签无法修改如何办?
-
SPSSAU进行KANO模型时默认会按照标题名词生成象限图,可通过修改标题后再次分析(也或者下载数据整理好格式后上传进行‘可视化’里面的象限图),得到希望的象限图。
-
SPSSAU进行KANO模型时没有显示出名称?
-
如果进行KANO模型时没有显示出完整的名称,其原因通常是名称过长或者数字非常接近导致重叠导致无法在图中显示。建议按下述几个办法处理。1是点击图下面的‘修改名称’按钮对名称进行简化;2是对图进行放大缩小功能操作通常放大后会展示;3是设置坐标值大小尝试调整;4是使用更大屏幕或更高分辨率的电脑。如果上述操作依旧不可以,建议下载绘图数据后在EXCEL中手工绘制图并手工对图进行调整,也或者下载图片放入PPT中手工标注名称等。