DOE实验设计
DOE(Design of Experiments,实验设计)是一种系统化的实验方法,用于识别和量化影响过程或产品性能的因素。通过科学的实验设计,可以高效地获取数据,减少实验次数,同时获得可靠的结论。DOE设计时,SPSSAU提供包括析因设计、响应面设计、拉丁方设计共三类,其中析因设计包括4种,分别是:2水平全析因设计、全析因设计、2水平部分析因设计和PB设计(Plackett-Burman设计);响应面设计包括2种分别是Box-Behnken设计(BBD)和中心复合设计(CCD);拉丁方设计用于控制干扰因子的实验设计。
SPSSAU系统中,除DOE实验设计外,还提供正交设计和均匀设计这两种试验。
DOE实验设计案例
-
1、理论
关于析因设计、响应面设计和随机拉丁卡方这三种实验设计上,其阐述如下表格:
对比项 析因设计 响应面设计 拉丁卡方设计 主要目的 筛选重要因素,分析主效应和交互效应 建立数学模型,优化工艺参数 控制干扰因子,平衡实验顺序 适用阶段 因子筛选阶段 参数优化阶段 实验过程控制 实验次数 中等到高(随因子数指数增长) 中等(随因子数增加而增加) 用户指定 因子水平 通常2水平,也可多水平 通常3水平 连续水平 可估计效应 主效应、交互效应 主效应、交互效应、二次效应 主效应 综合对比来看:如果有考虑到后续的分析需要,比如响应面设计时,其需要使用到‘响应面分析’这种研究方法,那么可直接考虑响应面设计(包括BB设计或CCD设计),如果考虑控制干扰因子,那么应该使用拉丁卡方设计。除此之外,析因设计使用非常多,其更多用于复选和研究重要因素,分析因素的主效应(或交互效应等),并且使用2水平的情况相对较多。
以及从各种实验的优缺点对比来看:
设计类型 优点 缺点 析因设计 1. 能全面分析主效应和交互效应
2. 适用于因子筛选
3. 结果易于解释1. 实验次数多,成本高
2. 不适用于参数优化
3. 对于大量因子不实用响应面设计 1. 能建立完整数学模型
2. 可用于参数优化
3. 能分析二次效应1. 实验次数较多
2. 数据分析复杂
3. 需要更多专业知识拉丁卡方设计 1. 实验次数可控制
2. 有效控制干扰因子
3. 实验安排灵活1. 不能分析复杂效应
2. 不适用于建模
3. 优化能力有限析因设计更多关注于主效应(和交互效应),并且实验设计相对较好理解,但其通常竣次数较多。响应面设计时更多用于二次效应(非线性效应)的分析。拉丁卡方设计竣次数可自由设定,其更多目的在于控制干扰因子。
在应用场景的选择上:
应用场景 析因设计 响应面设计 拉丁卡方设计 初期因子筛选 ★★★★★ ★☆☆☆☆ ★★☆☆☆ 参数优化 ★★☆☆☆ ★★★★★ ★☆☆☆☆ 质量改进 ★★★★☆ ★★★★☆ ★★☆☆☆ 工艺开发 ★★★★☆ ★★★★★ ★★☆☆☆ 控制干扰因子 ★★☆☆☆ ★★☆☆☆ ★★★★★ 建立预测模型 ★★☆☆☆ ★★★★★ ★☆☆☆☆ 寻找最优条件 ★★☆☆☆ ★★★★★ ★☆☆☆☆ 析因设计主要在于初期因子复选使用,而响应面设计更多目的在于参数优化、质量改进或者工艺开发,并且可建立预测模型和寻找最优条件。拉下卡方设计化生于控制实验干扰因子。
如果是有详细的实验设计流程,建议参考下表格进行,即第1阶段因子复选时使用‘析因设计’,接着因子优化时使用响应面设计,最后也可结合拉丁卡方进行实验验证。但多数情况下仅使用因子复选或者因子优化。
阶段 推荐设计 目标 第1阶段:因子筛选 析因设计(PB设计或部分析因设计) 从大量因子中筛选出关键因子 第2阶段:因子优化 响应面设计(BBD或CCD) 建立模型,寻找最优参数组合 第3阶段:验证实验 拉丁卡方设计或析因设计 验证模型预测结果的可靠性 上述内容更多倾向于析因设计、响应面设计和拉丁卡方设计这3种情况的阐述,接下来具体说明析因设计的4种类型对比,以及响应面设计的2种类型对比,如下述:
特征 因子水平个数 实验次数 适用因子数 2水平全析因设计 每个因子均为2水平 2^k (k为因子数) 通常≤5个因子 全析因设计 各因子可有不同水平个数 各因子水平个数的乘积 通常≤5个因子 2水平部分析因设计 每个因子均为2水平 2^(k-p) (k为因子数,p为减少因子数) 通常5-10个因子 PB设计(Plackett-Burman) 每个因子均为2水平 4的倍数(8≤n≤48) 通常>10个因子 2水平全析因设计时,其每个因子均为2个水平,其是2水平的全组合式设计,其适用于5个因子内的设计(原因在于实验次数过多),相对来看,2水平部分析因设计时会减少实验次数,并且其均为2水平。全析因子设计也是实验次数的组合,其仅适用于5个及以下因子的设计,PB设计的因子均为2水平,且其实验次数为4的倍数,通常适用于较多因子时使用。具体4种析因设计的选择和对比可见下表格说明:
情况 推荐设计 理由 因子数≤5,需要全面分析 2水平全析因设计 可全面分析所有主效应和交互效应 因子数≤5,因子水平个数不同 全析因设计 适用于不同水平个数的因子 因子数5-10,需要筛选 2水平部分析因设计 减少实验次数,快速筛选重要因素 因子数>10,快速筛选 PB设计 实验次数最少,高效筛选主要因子 特征 Box-Behnken设计(BBD) 中心复合设计(CCD) 因子水平个数 每个因子3个水平 2水平 + 中心点 + 轴点 实验次数 随因子数增加而增加 随因子数增加而增加 可估计效应 线性效应、二次效应、交互效应 线性效应、二次效应、交互效应 适用因子数 3-7个因子 2-9个因子 序贯性 无 有(前面试验后面还能用) 中心点支持 支持(可设置数量) 支持(可设置数量) 轴点支持 不适用 支持(可设置数量) 输入要求 因子个数、中心点数量 因子个数、中心点数量、轴点数量 针对2种响应面设计(BBD和CCD),其通常应用于连续性数据,比如温度、血压等类型的数据进行实验设计。以及响应面设计通常用于分析使用,用于比如建立二次响应面模型,以实现工艺优化和参数寻优。BBD和CCD时,其适用因子数量相对较少。CCD相对BBD的优点在于其‘序贯性’,‘序贯性’指实验设计具有按顺序进行的能力,前期实验的结果可以指导和用于后续实验的设计和分析,这一优点可节约成本,逐步地进行实验而非一次性完成所有实验,如果前期发现实验有问题可及时进行调整优化。
中心点是指所有因子都取中间值的实验点,比如温度介于50~90,那么中心点就是70度,其作用是作为实验基准点可提供稳定参考作用。以及CCD中轴点是指‘某因子取极值但其它因子保持中间值的实验点’,把‘某一个旋钮调到极限位置,其他旋钮保持在中间’,比如‘音量调到最大(+α),低音和高音保持在中间(0)’,轴点的作用在于帮助建立弯曲的响应面模型,并且提供模型精度更好的拟合非线性模型。
多数情况下BBD和CCD可通用,但具体对BBD和CCD的选择上,可参考下表所述:
情况 推荐设计 理由 3-7个因子,优化实验 BBD设计 实验点分布均匀,实验次数较少 2-9个因子,精确建模 CCD设计 可建立完整二次模型,具序贯性 需要序贯实验 CCD设计 前面试验结果可用于后续实验 避免极端条件 BBD设计 BBD设计不包含所有极端组合 -
2、操作
在SPSSAU中完成DOE实验设计时,其参数通常包括:因子个数、因子水平个数及具体值(或因子低水平或高水平值)、重复次数、区组和随机顺序等参数,具体如下表格所述。
参数类型 说明 注意事项 因子个数 必须项 结合专业知识和资源考虑 因子水平项 水平个数为必须项,具体水平值(或者高低水平值)由实际专业知识决定 水平值(或者高低水平值)建议结合实际专业知识设置 重复次数 即将实验重复,比如本身是6次实验,重复2次即为6*2=12次 试情况而定,多数情况下不需要重复 区组数 将实验随机分成几个独立的组(区组) 多数情况下不需要设置 随机顺序 随机打乱算法计算出的实验设计顺序 是否选中均可 析因设计(比如2水平全析因设计、2水平部分析因设计)时,其固定好为2个水平,因而只需要设置该2个水平的‘标签’即水平值即可。当然SPSSAU默认会标识为-1或者1等。全析因设计也类型,其因子水平个数由研究者自行决定。PB、BB、CCD、拉丁方设计这4个设计时,仅需要设置高和低水平对应的数值,比如最低温度是20度最高为60度,此时分别输入低水平为20,高水平为60即可。
重复次数是指将算法得到的实验完全性的‘复制’,比如本身算法得到是10次试验,那重复次数为3,即为10*3=30行实验,且是绝对的重复,通常不需要设置重复次数。区组数是指对实验随机分组,比如得到20次,区组为5,那就每个区组为4次实验,SPSSAU会自动输出随机区组的编号,多数情况下不需要设置区组。随机顺序是指打乱实验的顺序,是否设置均可。
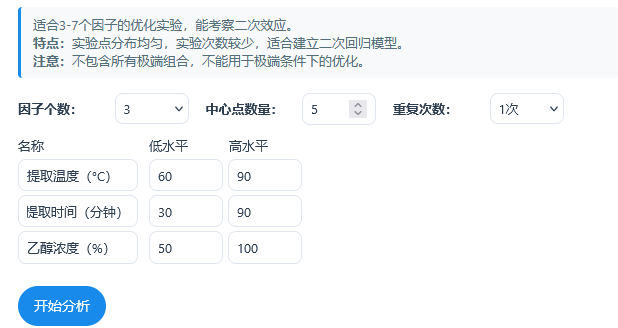
以BB设计为例:某制药公司需要优化一种药物的提取工艺,以提高有效成分的收率。经过初步研究,确定了三个关键因子,分别是提取温度,提取时间和乙醇浓度,3个因子均包括3个水平,分别的水平值如下:
因子 低水平(-1) 中心水平(0) 高水平(+1) 单位 提取温度(A) 60°C 75°C 90°C °C 提取时间(B) 30分钟 60分钟 90分钟 分钟 乙醇浓度(C) 50% 75% 100% % 并且希望实验时有5个中心点,即‘提取温度为75度/提取时间为60分钟/乙醇浓度为75%’的实验至少有5次(此处提示:基于算法判断,最终结果的中心点个数会大于等于设置个数,并非绝对相等)。操作截图如下:
SPSSAU输出‘实际值’和‘编码值’两个表格结果,分别如下:
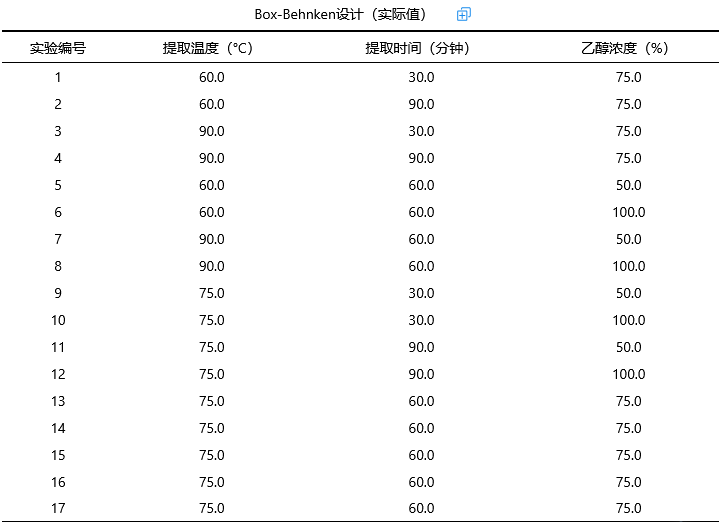
上表格展示了实验人员使用的‘实际值’结果,展示了共需要17次实验,每次实验对应的提取温度、提取时间和乙醇浓度信息,比如第5次实验时,提取温度为60度,提取时间为60分钟,乙醇浓度为50%。
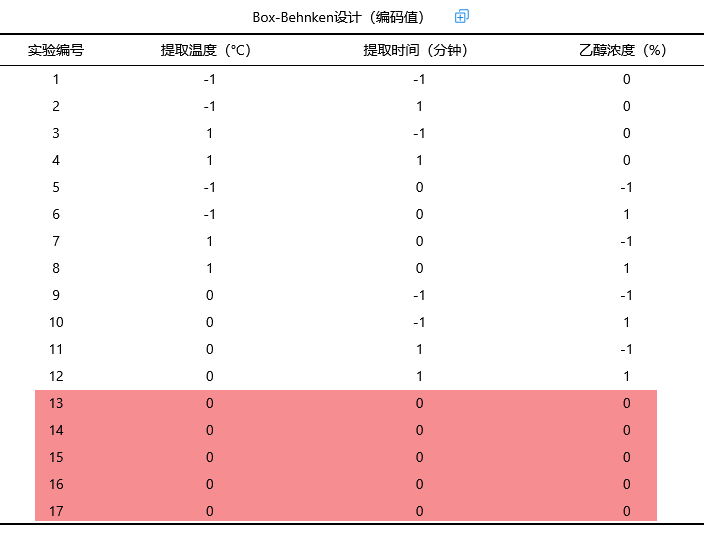
上表格展示分析时需要的编码值表格,比如提取温度时:数字-1表示60度,1表示90度,数字0表示其中间值即75度。具体‘实际值’和‘编码值’的换算映射关系可见接下来的内容。与此同时,本次中心点数量设置为5,如上表格所示,中心点即最中间状态的实验设计,编码从13到17共5次实验均为中心点。
-
3、SPSSAU输出结果
SPSSAU中进行DOE实验设计时,其会输出2个表格,分别是‘实验值’表格和‘编码值’表格,说明如下:
实际值表格显示的是每个实验运行中各因子在实际操作中的具体数值,比如使用实际物理单位(如°C、分钟、%等),其可方便实验人员直接按照表格设置参数和记录数据等。编码值表格显示的是每个实验运行中各因子的标准化数值,通常用-1、0、+1等代码表示,编码值表格是用于建立数据模型进行分析使用的表格,其可消除量纲影响便于比较各因子效应等。如果是做分析使用则应该使用‘编码值’表格,如果是实验记录使用则可使用‘实际值’表格。如果研究人员设置过具体水平值,此时‘实际值’表格才有实际意义,否则其和‘编码值’表格应该完全一致。
‘实际值’表格和‘编码值’表格有着绝对的映射关系(即换算关系),见下表格说明:
设计类型 编码值 实际值 说明 2水平全析因 -1和1 水平值 水平值映射 全析因设计 0,1,2等 水平值 水平值映射 2水平部分析因 -1和1 无 无 PB设计 -1和1 (高水平-低水平)/ 2 * 编码值 + (高水平+低水平)/ 2 共2个编码值 Box-Behnken -1, 0和1 (高水平-低水平)/ 2 * 编码值 + (高水平+低水平)/ 2 共3个编码值 中心复合设计 -α, -1, 0, +1, +α (高水平-低水平)/ 2 * 编码值 + (高水平+低水平)/ 2 共5个编码值 拉丁方设计 0到1之间 低水平+编码值*(高水平-低水平) 线性映射 2水平全析因和2水平部分析因时,编码值均为-1和1,实际值即对-1或1对应的水平值。全析因设计时不需要设置水平值因而仅提供编码值表格。PB/BB/CCD这3个设计时,其实际值和编码值的映射公式完全一致,均为‘(高水平-低水平)/ 2 * 编码值 + (高水平+低水平)/ 2’,但该3个设计时的编码值并不相同。拉丁方设计时,编码值介于0到1之间,实际值是编码值与水平值线性映射。
综述:如果是进行分析使用,那应该使用‘编码值‘表格,如果是实际记录使用,则使用’实际值‘表格,当然实验人员理解编码值的数字意义,也可直接使用编码值表格均可。
-
4、剖析
涉及以下几个关键点,分别如下:
-
DOE试验时,中心点是什么意思?
-
中心点是指所有因子都取中间值的实验点,比如温度介于50~90,那么中心点就是70度,其作用是作为实验基准点可提供稳定参考作用。
-
DOE试验时,轴点是什么意思?
-
CCD中轴点是指‘某因子取极值但其它因子保持中间值的实验点’,把‘某一个旋钮调到极限位置,其他旋钮保持在中间’,比如‘音量调到最大(+α),低音和高音保持在中间(0)’,轴点的作用在于帮助建立弯曲的响应面模型,并且提供模型精度更好的拟合非线性模型。
-
SPSSAU进行DOE试验时,重复次数是什么意思?
-
复次数是指将算法得到的实验完全性的‘复制’,比如本身算法得到是10次试验,那重复次数为3,即为10*3=30行实验,且是绝对的重复,通常不需要设置重复次数。
-
SPSSAU进行DOE试验时,区组是什么意思?
-
区组数是指对实验随机分组,比如得到20次,区组为5,那就每个区组为4次实验,SPSSAU会自动输出随机区组的编号,多数情况下不需要设置区组。
-
SPSSAU进行DOE试验时,随机顺序是什么意思?
-
随机顺序是指打乱实验的顺序,是否设置均可。
-
SPSSAU进行DOE试验时,输出结果包括实验值和编码值,分别是什么意思?
-
实际值表格显示的是每个实验运行中各因子在实际操作中的具体数值,比如使用实际物理单位(如°C、分钟、%等),其可方便实验人员直接按照表格设置参数和记录数据等。编码值表格显示的是每个实验运行中各因子的标准化数值,通常用-1、0、+1等代码表示,编码值表格是用于建立数据模型进行分析使用的表格,其可消除量纲影响便于比较各因子效应等。如果是做分析使用则应该使用‘编码值’表格,如果是实验记录使用则可使用‘实际值’表格。
-
SPSSAU进行DOE试验时,设置轴点数量/中心点数量与结果不一致?
-
算法可能会强制增加中心点数量或者轴点数量,此种情况的产出主要是出现在因子数量较多时(例如 ≥4),其出于更好的实验设计具有更好误差估计和统计功效考虑。
-