亚组分析
-
案例数据下载 下载
-
亚组分析(Subgroup Analysis)是一种用于评估暴露因素(如治疗方式、风险因素)的效应在不同人群特征(如性别、年龄、疾病分期)中是否存在差异的统计方法。在实际研究中,同一治疗或干预措施对不同特征的人群可能产生不同的效果,亚组分析正是用于探索这种"效应异质性"的重要工具。比如:
-
某种降压药物剂量对年轻患者和老年患者的降压效果可能不同
-
某个风险因素(如BMI)对不同年龄段人群的疾病发生风险影响可能不同
传统回归分析通常假设暴露因素的效应在所有人群中固定不变,而亚组分析则通过按亚组变量的不同水平分层分析,并结合交互检验来判断效应差异是否具有统计学意义。SPSSAU支持三种主流回归框架下的亚组分析,分别是线性回归、二元Logit回归和Cox回归。
-
重要提示:
-
亚组分析的核心意义在于回答一个问题:"暴露因素的效应,在不同人群特征下是否一致?"。暴露变量是核心研究因素,亚组变量用于分层探索效应差异。
-
亚组分析案例
-
1、背景
本次案例研究dosage对于生存状态的影响,并且区分性别gender和是否抽烟smoking作为亚组变量,希望探讨dosage对于生存状态survival_status的效应作用,是否会有不同性别或者是否吸烟两类群体上有着一致性。并且将age和bmi这两面作为干扰因素纳入模型中,即放入协变量框中,该2项均为定量数据,因此不需要设置定类项。
-
2、理论
进行亚组分析时,其涉及的关键变量名词如下:
名称 说明 暴露变量(X) 核心研究因素,可以是二分类变量(如治疗组 vs 对照组)或连续变量(定量数据,如药物剂量)。
SPSSAU会自动检测:若为2个类别会自动进行0/1编码处理,反之则看作是定量数据处理结局变量(Y) 被影响的变量。线性回归时为连续变量;Logit回归时为二分类变量;Cox回归时为事件状态变量(0=删失,1=发生事件) 亚组变量 用于分层的变量,即在不同亚组中分别评估暴露的效应。
SPSSAU自动检测:数值型且类别数≤10时作为分类变量处理,类别数>10时作为连续变量(定量数据)处理协变量 需要控制的其他混杂因素,如年龄、BMI等。
可指定哪些协变量为定类(分类)变量,默认"第一个"类别作为参照项生存时间 Cox回归特有,即随访时间变量,与事件状态变量配合使用 哑变量参照组 定类协变量的参照组设置,默认"第一个"类别作为参照项 -
亚组分析的原理上:其核心思想是"分层回归 + 交互检验",其包括全体样本模型,亚组分层模型和交互检验共3项。比如亚组是性别(男和女2个组别)时:
-
1:全样本模型时:结局 = β0 + β1 × 暴露 + 协变量 + ε
-
2:亚组模型时:
男性亚组:结局 = β0M + β1M × 暴露 + 协变量 + ε
女性亚组:结局 = β0F + β1F × 暴露 + 协变量 + ε
-
其中,β1F 和 β1M 分别为女性和男性亚组中暴露的效应估计值。
-
3:交互检验
-
分层回归可以得到各亚组的效应估计值,但仅凭数值差异不足以说明效应确实因亚组而异,还需通过交互检验来判断。交互检验构建包含交互项的完整模型如下:
-
结局 = β0 + β1 × 暴露 + β2 × 性别 + β3 × (暴露 × 性别) + 协变量 + ε
-
其中 β3 为交互项系数,β3 = 0 表示暴露效应在男女中无差异。通过比较含交互项模型和不含交互项模型,SPSSAU使用似然比LR检验(二元Logit/Cox回归)或F检验(线性回归)得出统一的 p for interaction 值。
-
重要提示:
-
暴露变量X、亚组变量Subgroup、协变量三者角色不同:暴露变量是核心研究因素,亚组变量用于分层探索效应差异,协变量为需要控制的混杂因素。
-
-
3、操作
本例子操作截图如下:
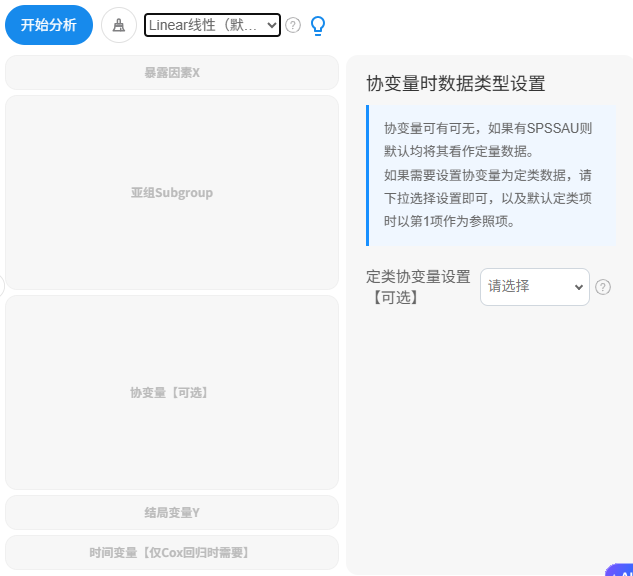
在SPSSAU的医学研究模块‘亚组分析’方法中,其涉及暴露因素X,亚组Subgroup,协变量,结局变量Y(另如果是Cox回归还涉及时间变量项),其中协变量可有可无;与此同时,模型可下拉选择分别是线性回归、二元Logit回归和Cox回归,本案例操作如下图所示:
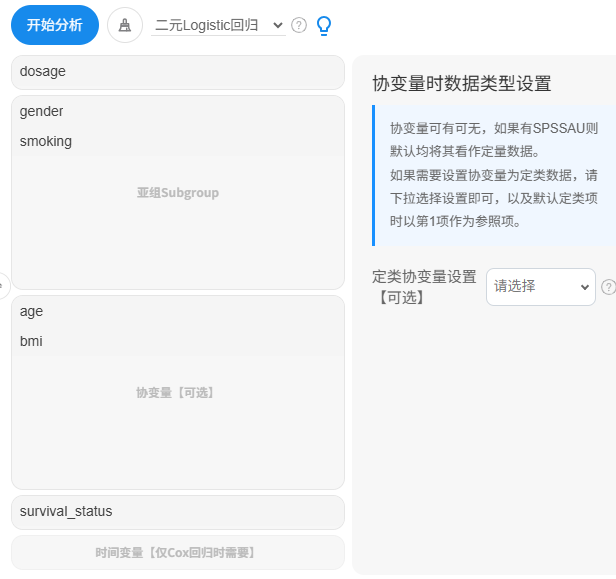
本次数据的因变量是01二分类数据,因此使用二元Logistic回归模型。研究dosage对于生存状态的影响,并且区分性别gender和是否抽烟smoking作为亚组变量,希望探讨dosage对于生存状态survival_status的效应作用,是否会有不同性别或者是否吸烟两类群体上有着一致性。并且将age和bmi这两面作为干扰因素纳入模型中,即放入协变量框中,该2项均为定量数据,因此不需要设置定类项。
-
4、SPSSAU输出结果
SPSSAU共输出6个表格,如下述:
SPSSAU亚组分析输出表格 说明 亚组分析数据类型汇总 包括各变量的数据类型汇总 亚组分析结果 核心的亚组分析分析表格,展示P for interaction等信息 森林图 森林图直观展示亚组分析回归结果 样本缺失情况汇总 分析数据的缺失情况等 -
5、文字分析
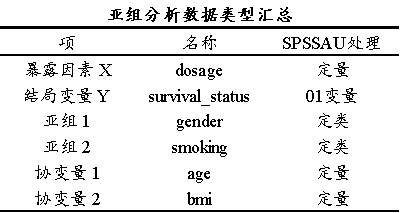
上表格展示各变量包括暴露因素X,结局变量Y,亚组和协变量信息,需要注意的是,暴露因素X和亚组,SPSSAU会自动进行数据类型识别和处理,说明如下:
-
重要提示:
-
SPSSAU会自动检测暴露因素X的数据类型,若其为2个类别会自动进行0/1编码处理,反之则看作是定量数据处理。并且SPSSAU会自动检测亚组Subgroup的数据类型,如果类别数≤10时作为定类变量处理,类别数>10时作为定量连续变量处理。
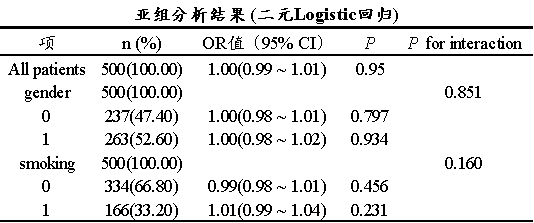
全人群基线(All patients)来看,OR = 1.00(95% CI: 0.99 ~ 1.01),P = 0.95,说明在总体人群中,该自变量每改变一个单位,结局事件的发生概率既不增加也不减少,完全没有表现出任何危险因子或保护因子的迹象。
并且区分性别这个亚组时,P for interaction = 0.851,远大于0.05,说明性别与核心自变量之间不存在交互效应。换句话说,该变量在男性和女性中的效应是完全同质的(都是毫无影响)。类似地,针对吸烟这个亚组时,P for interaction = 0.160,P 值为0.160 > 0.05,表明吸烟状态并不会调节该自变量对结局的影响,不需要进行异质性解释。总结来看即暴露因素对结局事件的影响在不同性别及吸烟状态的亚组人群中均保持一致的阴性结果,未发现明显的临床或统计学异质性。
除表格外,SPSSAU还输出森林图直观展示结果,如下图:
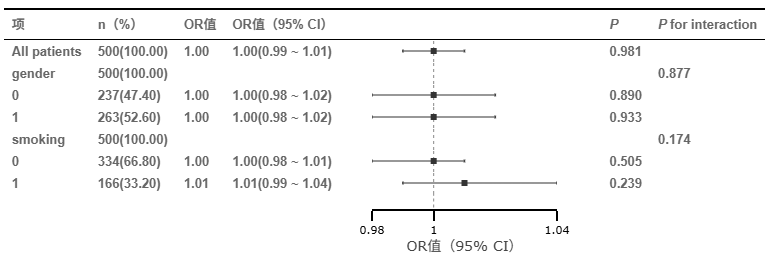
森林图直观展示出本次亚组分析的基本信息,OR值,P 值及P for interaction信息信息等,图里面可以看到置信区间都穿越参考线1,因而意味着暴露因素对结局没有统计影响。如果当前默认输出森林图不符合预期,研究者可使用'可视化'模块里面的森林图功能自主绘制森林图。
-
疑难解惑
-
亚组分析的意义是什么?
-
亚组分析的核心意义在于回答一个问题:"暴露因素的效应,在不同人群特征下是否一致?"。
-
p for interaction是如何计算得到的?
-
当二元Logit或者Cox回归时,同时拟合两个嵌套模型(无交互项 vs 有交互项),获取各自的对数似然值 LL0 和 LL1,然后进行LR检验,统计量LR = −2 × (LL0−LL1) ∼ χ2(df)。如果是线性回归,比较两个模型的残差平方和(RSS),然后计算统计量:
-
暴露因素X的数据类型自动处理?
-
SPSSAU会自动检测暴露因素X的数据类型,若其为2个类别会自动进行0/1编码处理,反之则看作是定量数据处理。
-
亚组Subgrouop的数据类型自动处理?
-
SPSSAU会自动检测亚组Subgroup的数据类型,如果类别数≤10时作为定类变量处理,类别数>10时作为定量连续变量处理。
-
协变量为定类时进行哑变量处理是什么意思?
-
涉及到哑变量问题,其原理内容请参考,点击可查看。