单因素与多因素回归
-
案例数据下载 下载
-
在医学、社会科学、经济学等领域的量化研究中,研究者经常需要回答这样一类问题:哪些因素会影响某个结果?每个因素的影响有多大?比如:
-
医生想了解年龄、血压、BMI、吸烟史等因素是否会影响患者心梗发生风险;
-
探究家庭收入、父母学历、课外辅导时长对学生期末成绩的影响;
-
分析广告投放、价格折扣、季节因素对产品销量的影响。
上述研究问题都可以通过回归分析来解决。而单因素多因素回归是回归分析中一种经典的"两步走"分析策略:
-
单因素回归分析(Univariate Analysis):将每个自变量单独放入模型,考察它与因变量之间的关系——相当于"初筛",看看哪些因素"可能有影响";
-
多因素回归分析(Multivariate Analysis):将所有自变量同时放入模型,在控制其他变量影响的条件下,评估每个自变量的独立效应——相当于"互相校正后,看谁才是真正的影响因素"。
SPSSAU将单因素分析和多因素分析一键整合,用户只需选择因变量、自变量和回归类型,系统自动完成单因素初筛 + 多因素校正分析,并输出整齐可比的结果表格,简化操作。在SPSSAU中,
-
支持线性回归/二元Logit回归/Cox回归/有序Logit回归/Poisson回归和负二项回归共6种模型;
-
支持X设置为定类数据;
-
提供单因素回归和多因素回归时分别的森林图;
-
重要提示:
-
单因素与多因素回归的核心思路是:单因素是指分别每个X与Y进行回归,多因素是指所有X一并纳入与Y进行回归。单因素回归逐一分析各自变量与结局的粗关联(Crude),多因素回归同时纳入所有自变量,控制混杂后得到各变量的独立效应(Adjusted)。
-
亚组分析案例
-
1、背景
本次案例数据中包括7个自变量X,其中X1/X4/X5/X7均为定类数据。现在希望进行单因素回归和多因素回归,完成自变量X的初筛和独立效应情况分析。
-
2、理论
单因素回归分析时:其将每个X分别与Y进行回归,得到回归系数,以及粗效应Crude;多因素回归分析时:将所有X一并纳入模型与Y进行回归,得到回归系数,以及独立效应Adjusted。SPSSAU在输出结果和森林图中均有提供Crude和Adjusted,如下表所示:
模型 粗效应 独立效应 线性回归 Crude β(95% CI) Adjusted β(95% CI) 二元Logistic回归 Crude OR (95% CI) Adjusted OR (95% CI) 有序Logit回归 Crude OR (95% CI) Adjusted OR (95% CI) 多分类Logit回归 Crude RR (95% CI) Adjusted RR (95% CI) Poisson回归 Crude RR (95% CI) Adjusted RR (95% CI) 负二项回归 Crude RR (95% CI) Adjusted RR (95% CI) Cox回归 Crude HR (95% CI) Adjusted HR (95% CI) 如果是线性回归,直接提供回归系数β及其95%置信区间;二元logit回归和有序Logit回归,其为OR值,即回归系数β的指数次方,以及OR的95%置信区间;多分类Logit和Poisson回归,负二项回归为RR值,其也为回归系数β的指数次方,以及RR的95%置信区间。COX回归提供HR值及其95% CI值。无论是OR/RR/HR,它们数学计算上均为回归系数β的指数次方,但实际意义上一般分别称OR/RR/HR而已。
-
3、操作
本例子操作截图如下:
在SPSSAU‘单因素与多因素回归’方法中,其涉及因变量框,自变量X框,并且需要研究者自行选择回归模型,分别是:线性回归/二元Logit回归/Cox回归/有序Logit回归/Poisson回归和负二项回归共6种模型,本案例操作如下图所示:
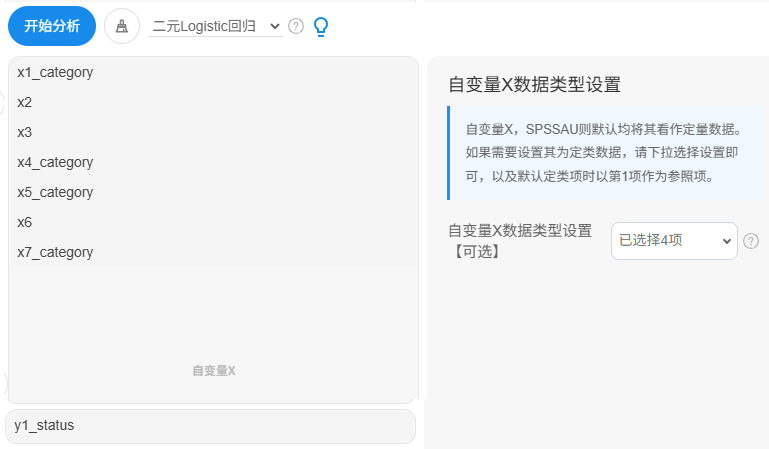
本次数据的因变量是01二分类数据,因此使用二元Logistic回归模型。上图中展示下拉选中了4项为定类(X1/X4/X5/X7)。
-
4、SPSSAU输出结果
SPSSAU共输出6个表格,如下述:
SPSSAU单因素与多因素回归输出表格 说明 单因素多因素回归基本信息 包括各变量的数据类型汇总 单因素和多因素回归结果 核心的单因素与多因素回归分析表格,并且支持切换查看 单因素回归森林图 森林图直观展示单因素回归结果 多因素回归森林图 森林图直观展示单因素回归结果 样本缺失情况汇总 分析数据的缺失情况等 -
5、文字分析

本案例设置4个X定类数据,SPSSAU会自动对定类X进行哑变量处理,并且将第1项作为参照项。

为了排除变量间的共线性和混杂干扰,将所有自变量全部纳入多因素Logistic回归模型进行单因素与多因素分析。
单因素分析结果显示:X6对因变量具有显著的正向影响(β = 0.09,p = 0.002),其粗优势比(Crude OR)为1.10(95% CI: 1.03~1.17),表明该变量数值每增加一个单位,事件发生概率平均提升10%。分类变量x7_category表现出显著的负向影响(β = -0.37,p = 0.050),以状态0作为基准对照,状态1的事件发生风险降低了31%(OR = 0.69,95% CI: 0.47~1.00)。其余变量(包括x1_category、x2、x3、x4_category、x5_category)在单因素分析中均未达到统计学显著性水平(p > 0.05)。
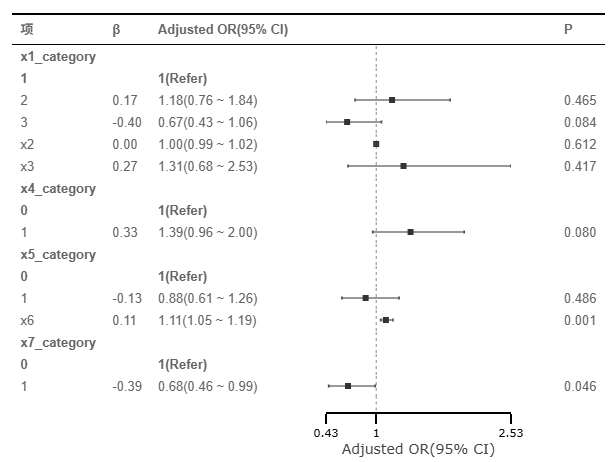
多因素分析在控制其他变量后,结果显示x6与x7_category依然具有独立的统计学意义,是因变量的独立影响因子。变量x6呈现出更为稳健的正向驱动效应(β = 0.11,p = 0.001),调整后优势比(Adjusted OR)为1.11(95% CI: 1.05~1.19),表明x6每升高一个单位,事件发生的独立风险将增加11%。变量x7_category呈现出显著的独立抑制效应(β = -0.39,p = 0.046),调整后优势比为0.68(95% CI: 0.46~0.99),表明在同等条件下,状态1发生事件的概率独立地比状态0降低了32%。
此外,变量x4_category在排除混杂后呈现出边缘显著趋势(β = 0.33,p = 0.080),状态1相比状态0的事件发生概率有上升趋势(OR = 1.39,95% CI: 0.96~2.00),值得在后续研究中持续关注。而x1_category、x2、x3以及x5_category在多因素调整后均不显著(p > 0.05),尚不能认为其对因变量具有独立解释作用。
与此同时,SPSSAU还输出单因素或多因素对应的森林图,分别如下:
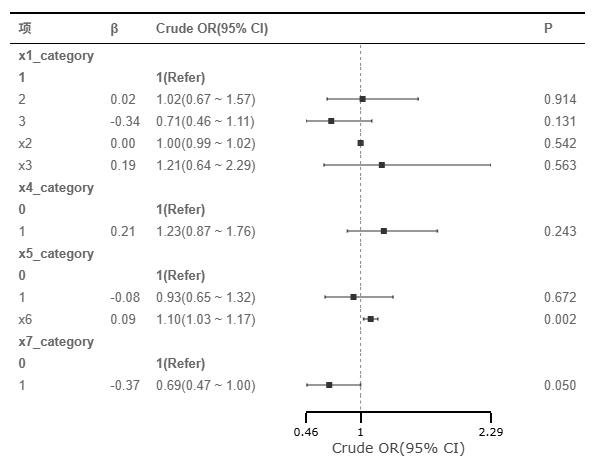
上图是单因素回归后得到的森林图,森林图的解读上,可以直接查看P值,也或者查看横线与小矩阵,如果横线穿越了虚线(即参照线),意味着并不会显著,如图中看到:仅X6和X7具有显著性即说明该两项是作用因素。下图是多因素回归对应的森林图。其考虑独立效应情况,单因素回归时显示X6和X7有着影响作用,而且多因素回归时,其也有着相同的效应,即排除干扰因素后,X6和X7依旧会有着作用影响关系。
疑难解惑
-
单因素与多因素回归的意义是什么?
-
单因素与多因素回归可用于‘变量筛选’,实际研究中,自变量可能非常多(几十个甚至上百个),全部纳入多因素模型会导致模型不稳定(自由度损失、多重共线性等问题)。单因素分析可以帮助研究者快速识别出潜在有意义的变量,再进行多因素分析。
-
粗效应Crude与调整效应Adjusted是什么?
-
粗效应Crude与调整效应Adjusted的对比:通过比较单因素(粗效应)和多因素(调整效应)的结果,可以判断变量间是否存在混杂效应。如果某变量在单因素中显著但在多因素中不显著,说明它的效应被其他变量"解释"掉了。
-
X为定类时进行哑变量处理是什么意思?
-
涉及到哑变量问题,其原理内容请参考,点击可查看。