关联规则apriori
-
案例数据下载 下载
Apriori关联规则算法是一种用于数据挖掘的经典算法,其作用是找出数据中频繁出现的集合(频繁集),进而辅助进行有效决策。比如商场里面购买商品,有1000个人购买了可能1万种商品,那么那些商品出现频率更高呢,也或者哪两两商品重复出现的频率更高呢。当某两种或者三种商品同时出现,即消费者更容易同时购买某两种或者三种商品时,此时商场分析人员是否应该考虑将该两种或三种商品摆放在一起(或者捆绑销售呢),这样可以提供消费者的购物体验满意度,同时也可能带来更高的销售额,也可减少商品的占用空间等多种好处。这就是Apriori算法的核心应用。
上述中提及一个关键指标为频繁集,其是指研究项(例子里面为商品名称)及其组合的高频出现情况,通常情况下有几个指标可以对其进行衡量,分别是支持度,置信度和提升度,该三个指标均是用于衡量频繁集的指标,但具体意义不完全相同,下述理论部分会进一步说明。
关联规则apriori案例
-
1、背景
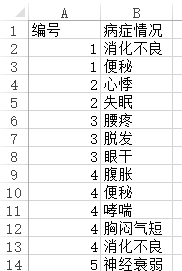
Apriori关联规则最为经典的案例是商场商品购物篮分析,但Apriori关联规则的应用远不于此,其也在医疗、金融等多个领域得到广泛应用,只要是用于研究类似于数据集一起出现情况,用于挖掘数据潜在特征组合时均可使用。本案例为某中医疾病探索分析,首先共收集1000名病人的病休特征,每名病人通常都有多种病状,比如心悸和神经衰弱容易同时出现,失眠与月经不调也容易同时出现等。最终整理出1000名病人共计3184种病症数据,部分数据如下图所示:
-
特别提示
-
Apriori关联规则分析时,上传到SPSSAU的数据格式较为特殊,比如本案例时共计1000名病人,每名病人可能有不同的病症,比如上图可以看到,编号为1的病人共有2种病症(分别是消化不良和便秘),编号为2的病人共有2种病症分别是心性和失眠。最终整理后共计1000名病人共有3184种病症。数据包括2列,分别是编号和病症情况(如果是比如商场购物,则为订单和具体商品名称)。
-
上述数据格式是SPSSAU中支持的格式,但很多时候整理的数据格式并非这样,比如很可能是下图所示的格式,编号为1的病人共有2种病症,该2种病症使用逗号隔开(而不是1种病症1行数据),如果是类似此类数据,可下载SPSSAU提供的‘apriori_spssau_dataformat_trans.xlsm’这个EXCEL宏文件(有代码的EXCEL文件)进行处理,一键整理成SPSSAU支持的数据格式。
关于‘apriori_spssau_dataformat_trans.xlsm’这个EXCEL宏文件(有代码的EXCEL文件)的使用说明如下:
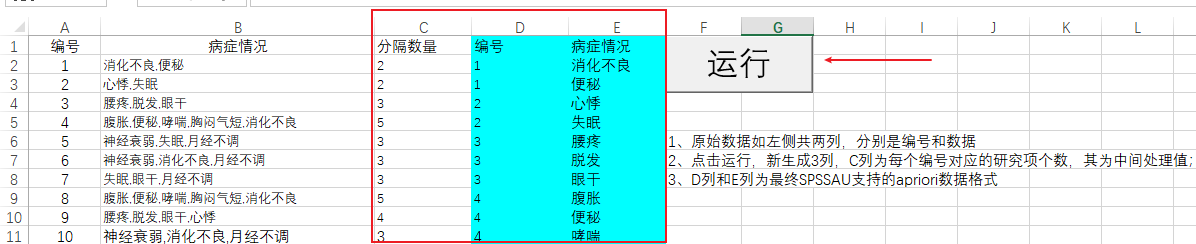
首先下载‘apriori_spssau_dataformat_trans.xlsm’这个EXCEL宏文件,如果打开后EXCEL提示有代码运行则需要同意它。接着将数据A和B列整理好,此时点击‘运行’按钮,并且输入B列涉及的分隔符(本案例为英文逗号,当然也可以是其它的分隔符号比如斜杠等),即可得到C、D和E共3列数据。C列标识分隔数量,即比如编号为1的病人共有2种病症,编号为2的病人也有2种病症,其用于检验数据使用。D列和E列为最终有效的数据格式,将该2列复制放到新的EXCEL文件中,然后上传到SPSSAU中进行分析即可。
-
-
2、理论
Apriori关联规则时,其涉及到3个关键指标分别是支持度,置信度和提升度,另外还有一个重要参数叫‘最大项集长度’,如下表所述:
指标 说明 参数值设置 支持度 数据集出现频次 除以 总数据集。比如啤酒和花生这一数据集合占总数据集的比例。
支持度越大说明该数据集出现概率越高。最小支持度默认为0.2,数据量较大时可考虑设置为更高比如0.3及以上。通常需要对此指标进行设置。 置信度 当B出现后,A出现的概率。比如购买了啤酒前提时,然后购买花生的比例。
置信度越高说明B出现后A出现的概率越高。最小置信度默认为0.1,可考虑设置更高的值 提升度 当B出现时再出现A的频次,除以A出现频次。其体现A和B的关联关系情况,如果提升度大于1则说明AB有强关联性,反之小于等于1说明是无效的强关联规则。 默认为2可考虑设置为更大的数字 最大项集长度 数据集合的最大长度,比如AB则为2,ABC则为3。 默认为3,建议可调整数字(比如为2/4/5) 通常情况下,可结合样本数据条数使用优化算法,以及默认是使用L2正则化,如果更多目的为特征选择,可考虑使用L1正则化。其余3项参数建议保留默认即可。Logistic回归当前进行分类或者预测的使用相对较少,但其用于研究计量影响关系的情况较多。研究者可结合实际情况,选择使用其它的机器学习算法比如xgboost、神经网络等。
支持度、置信度和提升度的公式分别如上,从数学上看,支持度即为AB同时出现的次数除以数据集总共次数,置信度表示AB同时出现的支持度除以B的支持度,提升度为置信度基础上进一步除以A的支持度。
支持度指标的实际意义为:数据集合的出现概率情况,默认是0.2,通常需要对其进行设置,因为在分析时通常需要首先关注哪些是高频,然后再对高频的进一步深入分析,所以需要重视该指标参数值。如果数据集较为分散则可设置较小的值比如0.2,如果数据集较为集中则可设置较大的值比如0.3及以上。
置信度和提升度这两个指标,其均是基于支持度较高的前提下进行,当有着较高的支持度时,进一步设置数据集合之间的关联情况。
最大项集长度参数:通常建议设置较小的数字,便于聚焦性分析,否则可能出现分析结果中数据集合长度过长无法有效的聚焦到具体数据集中。
-
3、操作
本例子操作截图如下:
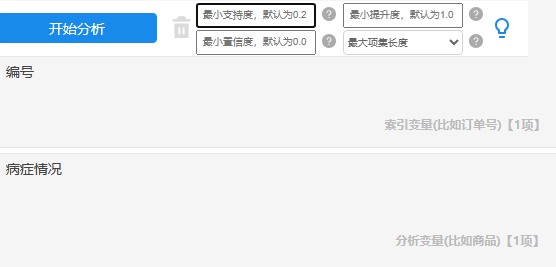
索引变量放入编号,分析变量放入病症情况。以及4个参数值均为默认值,先试探性地进行分析。
-
4、SPSSAU输出结果
SPSSAU共输出‘频繁项集汇总’和‘关联规则汇总’表格,下述会具体说明。
-
5、文字分析
接下来针对表格结果进行说明,如下:

上表格展示满足‘最小支持度’参数的数据集合,本案例设置为默认值0.2,即当数据集出现概率大于20%时即进行展示。上表格展示了8种数据集,其中眼干,消化不良,失眠,心悸和月经不调这5项是单一集,其余3个是AB两种集组合。相对来看,月经不调,心悸这两种病症的支持度均大于0.4,即意味着该两项的出现概率均大于40%,应该重点关注。当然其余几项的出现概率均大于20%,也应该重视。
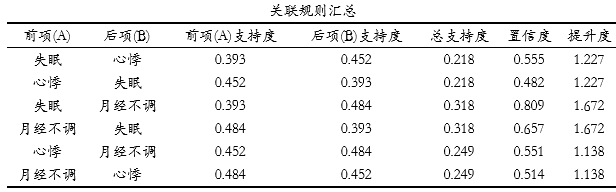
上表格展示满频繁集时超过2个数据时的关联规则情况,比如心悸和失眠这两项形成集合时,其分别的支持度,总支持度情况,置信度和提升度情况。便于整体分析关联情况。比如失眠和心悸,其展示二者分别的支持度,以及二者在一起时的总支持度。上表格来看,失眠和心悸均有着很高的出现概率(支持度分别是0.393和0.452),与此同时,二者的置信度为0.555,意味着出现失眠前提下再出现心悸的概率是55.5%,并且提升度为1.227>1,进一步说明二者有着强关联关系。
-
6、剖析
涉及以下几个关键点,分别如下:
-
SPSSAU中进行Apriori关联规则的数据格式?
-
SPSSAU中对Apriori关联规则的数据格式较为特殊,建议阅读本文档的‘背景’部分进行设置等。
-
关联规则汇总表格为空?
-
如果关联规则汇总表格没有出现结果,通常是由于数据格式不正确导致,建议确保数据格式的正确性,除此之外,如果出现结果非常多不便于查看,此时建议将支持度设置为更高数字,以减少输出结果。
-
上传Apriori关联规则数据时,超过500个不同的名称,上传时解析成null值?
-
如果是名称,比如Apriori中可能为购买的商品名称等,如果不同的名称数量大于500个,在上传到SPSSAU时会被处理成null值 (如果小于500个则不会),此种情况时,建议将商品名称使用一个编号(比如商品编号)进行标识,并且对其进行打标签设置(或者上传数据的时候在EXCEL中设置好标签再上传)即可。
-