多期数据DID操作
-
0、案例背景描述
多期DID常用于政策评估效应研究,比如研究‘鼓励上市政策’,‘开通沪港通’,‘开通高铁’,‘引入新教育模式’等效应时,分析效应带来的影响情况。
比如有50个地区分别11年(2010~2020)的数据(共计50*11=550行)。50个地区可分为两类地区A和B(分别均为25个),在2016年A类地区没有开通高铁,B类地区开通高铁。那么开通高铁对于GDP的影响情况如何呢?涉及两个关键数据,分别是Treated和Time,此处Treated为地区(A和B两个地区),以及时间项Time(高铁开通前和开通后)。同时研究‘开通高铁’参于gdp的影响,那么被解释变量Y即为gdp,与此同时还涉及可选的控制变量(控制变量为可选项,多数情况下并不需要),比如教育投入,人口或对外投资情况等,如下表说明。
项 说明 Treated 地区(0代表A类地区即控制组,1代表B类地区即实验组) Time 开通高铁前后(0代表开通前, 1代表开通后) Y gdp 控制变量 教育投入,人口,对外投资等 -
Treated只能为数字0或1,且一定包括此2个数字。其用于标识研究‘效应’对应的组别,数字0标识‘控制组’,数字1标识‘实验组’,一定需要这样处理。
-
Time只能为数字0或1,且一定包括此2个数字。其用于标识研究‘时间’对应的组别,数字0标识‘before’(实验前),数字1标识‘after(实验后),一定需要这样处理。
特别提示:
-
-
1、数据格式
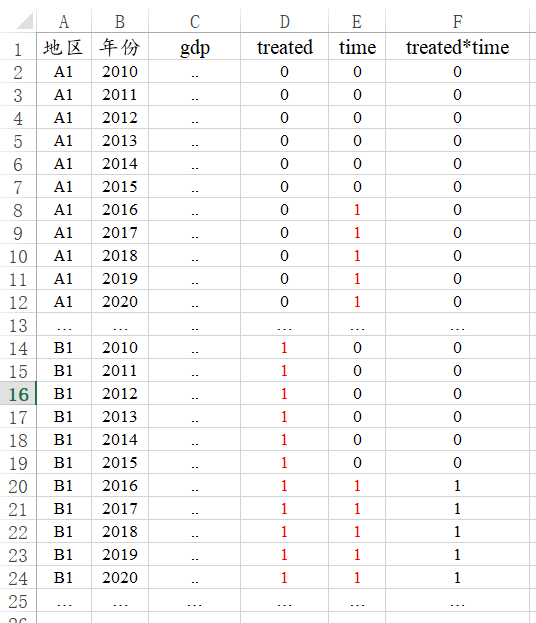
多期面板数据进行DID分析时,数据格式类似如下图:共计50个地区分别11年的数据,那么就应该为50*11=550行数据,加上第1行为标题即最终为551行数据。多期DID分析时共需要多出3列数据,分别是time,treated,treated*time,说明如下:
项 说明 Treated 地区(0代表A类地区即控制组,1代表B类地区即实验组) Time 开通高铁前后(0代表开通前, 1代表开通后) treated*time treated与time的交互项,即乘积项 针对treated:A地区全部为数字0,B地区全部为数字1;
针对time:2020~2015全部是数字0代表高铁开通前,2016~2020全部是数字1代表高铁开通后;
针对tretaed*time,其为treated与time的乘积项,即交互项。
-
2、数据处理
如果说数据已经是面板格式,但是没有treated,time,treated*time这三项数据,此时可使用SPSSAU->数据处理模块里面的‘数据编码’和‘生成变量’功能。使用数据编码功能时,将地区编码为01格式的treated,将年份编码为01格式的time,并且使用生成变量得到treated与time的交互项。操作分别如下各图:
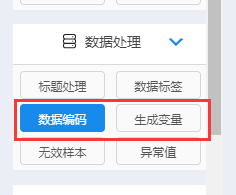
以年份为例进行数字编码如下图(当然也可使用范围编码),
数据编码完成后,分别得到treated和time数据;
-
当然数字0和1代表的意义需要自己进行标识(便于画图时使用),可使用数据处理里面的数据标签功能标识下即可。
-
如果需要修改标题的名称,可使用数据处理里面的标题处理功能。
-
接着使用生成变量功能的‘乘积(交互项)’得到treated和time的交互项,操作如下图:
-
-
3、SPSSAU分析多期DID
由于是面板数据,因而使用SPSSAU计量研究模块里面的‘面板模型’进行具体分析,操作如下图:
-
面板模型时打勾‘双向固定’模型(即输出结果中最终使用‘双向固定’模型对应的结果;
-
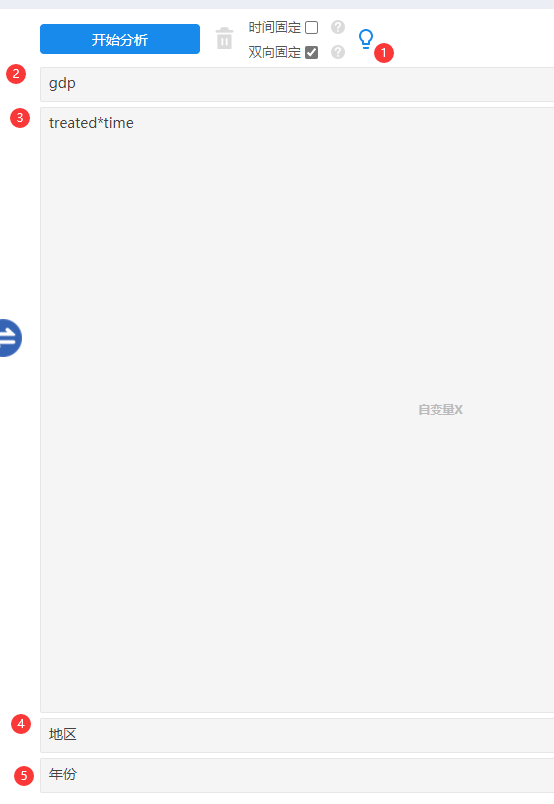
分别放入被解释变量(或因变量,此处为gdp),解释变量(或自变量,即交互项treated*time),以及将地区和年份放入对应的框中(以告诉系统此处为面板模型);
-
关于treated和time这两项,一般并不需要放入模型中,如果模型中有控制变量可直接放入对应解释变量(自变量X)框中就好。
-
最终输出结果中,直接分析交互项(treated*time)的显著性即可,如此其显著,则说明具有‘某效应’(此处为高铁效应),显著后如果回归系数大于0则为正向效应,反之则为负向效应。如果不显著,则说明没有‘某效应’。
-
-
4、关于平行趋势检验
多期数据进行DID模型研究时,针对共同趋势检验,通常有两种处理思路,分别是图示法和回归模型检验法。
4.1 图示法
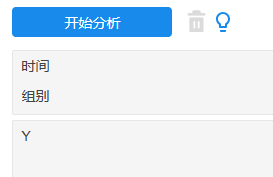
对比不同组别因变量均值的时间趋势;使用SPSSAU可视化中的误差线图或簇状图均可;图示法只需要观察‘效应’时间点前即before时的各时间点时,treated和control组别因变量数据是否均有平行性(两条线基本平行)即可;
具体做法如下:在簇状图绘制时,X放时间点和组别,Y放Y,绘制后横坐标是时间点,纵坐标为Y,并且按组别分拆出两条折线(分别是treated和control)。可通过该折线查看是否具有平行趋势,如果时间点前即Before时整体上treated和control组别数据平行即说明武汉的平行趋势。操作类似如下图所示。
4.2回归模型检验法
回归中加入各时点虚拟变量与treated的交互项(本例中年份虚拟变量乘以treated数据);如果说before时,各交互项系数不显著,则表明的确有着平行趋势。操作上分为3步如下:
-
第一步为使用SPSSAU数据处理里面的生成变量->‘虚拟变量’功能,得到‘时间项’的虚拟变量后(本例为年份);
-
第二步为将‘第一步’的虚拟变量项分别与treated进行相乘(目的是得到交互项)。
-
第三步是进行回归,通常可使用面板模型的个体固定效应或普通的ols回归均可。
最后进行平行趋势检验时,本案例中2010~2015共6年为‘效应前’,如果此6个年份对应的6个交互项基本上不显著(通常不太可能全部不显著),此时则说明具有平行趋势,即通过检验。
-
-
5、剖析
涉及以下几个关键点,分别如下:
-
Treated只能为数字0或1,且一定包括此2个数字。其用于标识研究‘效应’对应的组别,数字0标识‘控制组’,数字1标识‘实验组’,一定需要这样处理。
-
Time只能为数字0或1,且一定包括此2个数字。其用于标识研究‘时间’对应的组别,数字0标识‘before’(实验前),数字1标识‘after(实验后),一定需要这样处理。
-
多期面板数据时,一般使用‘双向固定’模型进行分析,具体分析时,只需要分析交互项‘treated*time’的显著性即可,如果显著就说明具有‘效应’,显著后回归系数大于0则说明为正向效应反之为负向效应。
-
treated和time均不需要放入模型中。
-
除使用‘双向固定’模型进行多期DID分析外,也可直接使用比如OLS模型,或个体固定效应模型进行分析,其结论基本上均会保持一致。
-
疑难解惑
-
多期面板数据DID如何进行平行趋势检验?
-
多期面板数据进行平行趋势检验通常有两种做法,一是图示法(使用SPSSAU的簇状图),二是事件研究法。
-
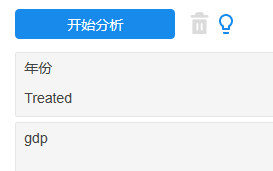
第1种图示法,其原理在于查看政策时间点前,实验组和控制组在不同时间点上的整体走势是否大体一致,使用SPSSAU簇状图即可,操作类似如下图:
-
-
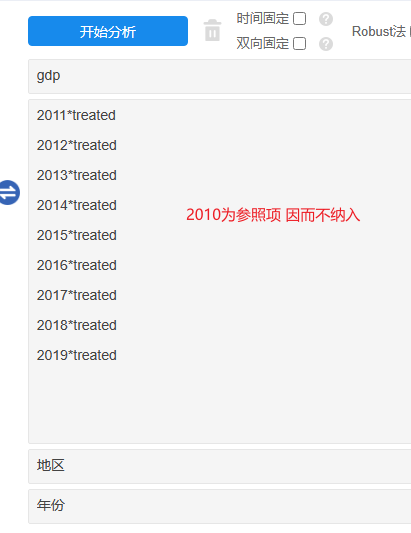
第2种事件研究法。其分为以下几步:第1步生成年份虚拟变量(比如10年则有10个虚拟变量),并且将其与组别Treated的交互项(共得到10个交互项);第2步是将其中9个交互项作为解释变量进行回归(通常是留下第1个交互项作为参照项);第3步是查看交互项系数,交互项系数反映的就是特定年份实验组和控制组之间的差异,通常希望政策时间点前的交互项系数不显著,如果政策时间点前的交互项系数基本均不显著则意味着平行趋势性良好。针对SPSSAU系统中操作如下图所示:
-
-
事件研究法的原理是查看政策时间点前交互项系数的显著性(希望其不显著),当然还可将回归系数及其95%区间数据取出,整理好数据后绘制coefplot图更直观展示显著性情况。