Firth惩罚Logit回归
-
案例数据下载 下载
-
Firth惩罚Logit回归可以理解为标准二元Logit回归的"稳定增强版"。标准二元Logit回归在样本量较小(比如不到100个样本)、数据出现"完全分离"(某个X取值下Y全是0或全是1)、或Y=1的比例特别极端时,会出现系数估计偏差大、标准误异常大甚至模型不收敛的问题
Firth回归通过在计算中引入一个"惩罚项",让系数不会因为数据稀缺而跑偏或趋于无穷,从而在小样本、分离数据、不平衡数据等"困难场景"下依然给出稳定可靠的估计。两者的关系可以这样类比:如果二元Logit是普通的杆秤,Firth回归就是给秤加了磁力底座——秤的灵敏度稍有降低,但读数更稳、更可靠。实际应用上,当样本量n<100、存在完全分离、或者标准Logit报错不收敛时,优先使用Firth回归;当样本量大(n>500)且数据正常时,两者结果通常几乎一致,用哪个都可以。
Firth惩罚Logit回归案例
-
1、背景
当前数据为某医学研究数据,共收集 100 条有效样本。研究人员希望分析 7 个自变量 对 某疾病结局(y) 的影响,探索哪些因素是该疾病的危险因素或保护因素。
-
2、理论
Firth惩罚Logit回归是研究X对于二分类Y的影响,其作用与二元Logit回归完全一致,那为什么要用Firth惩罚Logit回归?传统二元Logit回归在以下情况可能出现结果不稳定甚至无法收敛的问题:
样本量偏小:当前样本量 n = 100,属于小样本场景
事件比例偏低:比如y=1 的比例仅为5%,属于类别不平衡
可能存在分离问题:部分定类变量组合下可能存在完全分离或准完全分离(展示出来为比如奇异矩阵或不收敛等)。
Firth惩罚Logit回归通过在似然函数中引入 Jeffreys先验惩罚项,能够在小样本和分离数据下提供更稳定、更可靠的估计结果,是上述场景下的理想选择。因此建议,如果样本量较少(小于100)时可考虑使用Firth惩罚Logit回归,以及如果二元Logit回归后出现标准误特别小,p 值特别大,OR值特别大时,此时建议使用Firth惩罚Logit回归。从数学理论来看,标准二元Logit回归的对数似然函数为:
log L(β) = Σ [y · log(π) + (1 - y) · log(1 - π)]
Firth回归的惩罚对数似然为:
log L*(β) = log L(β) + 0.5 · log |I(β)|
其中 |I(β)| 是 Fisher 信息矩阵的行列式。惩罚项 0.5·log|I(β)| 等价于对回归系数施加 Jeffreys 不变先验。
-
3、操作
在SPSSAU进阶方法模块中有提供‘二元Logit回归’和‘Firth惩罚Logit回归’,操作截图如下:
SPSSAU进行‘Firth惩罚Logit回归’时,与二元Logit回归类似,SPSSAU提供两个参数,分别是‘保存残差和预测值’,其作用是将拟合得到的残差和预测值,分别以标题的形式存储在数据文档中,方便进一步使用。选中‘共线性诊断’时,SPSSAU会输出共线性检测表格。与此同时,SPSSAU中支持对X设置为定类,设置后,SPSSAU算法层面会自动对X进行哑变量处理(以第1项作为参照项),具体原理可点击查看。
-
4、SPSSAU输出结果
SPSSAU共输出7类表格和各类图形等。如下述:
项 说明 Firth惩罚Logit回归分析基本汇总 展示因变量Y的分类频数与百分比,用于检查标签分布是否均衡 Firth惩罚Logit回归模型似然比检验结果 评估整个回归模型整体是否具有统计学意义(是否比不放任何变量强) Firth惩罚Logit回归分析结果汇总 核心表格,展示各个自变量X对Y影响的显著性、方向以及影响幅度(OR值) Firth惩罚Logit回归预测准确率汇总 Firth惩罚Logit回归预测准确率汇总 Firth惩罚Logit回归分析结果-简化格式 汇总模型系数、拟合度(R方)及核心检验的“论文发表级”标准精简表 样本缺失情况汇总 统计和展示原始数据中有效样本与被排除无效样本的数量 共线性诊断 检验各独立自变量之间是否存在严重的信息重叠(多重共线性) 模型预测 输入自变量X时,得到预测值,其使用意义相对较少 森林图 图形化方式直观展示各个自变量的 OR 值(优势比)及其 95% 置信区间,用于快速锁定核心影响因素 模型结果图 展示X对于Y的影响作用图 OR值95% CI 聚焦于几率比(OR值)的区间估计区间,用以评估效应量的稳健性与波动范围 -
5、文字分析
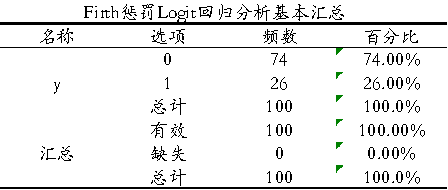
从上表格可知:数据没有缺失。虽然 Y=1的比例较低(26%),存在轻微的不均衡,但完全在 Firth 回归的优秀处理范围内(无需担心偏误)。

似然比检验(Likelihood Ratio Test)用于检验模型整体显著性。原假设 H0为"所有自变量的回归系数均为0"。p < 0.001,拒绝原假设,说明至少有一个自变量对y有显著影响,模型整体具有统计意义。-2LL(即-2倍对数似然值):模型从仅截距的 111.65 降至最终的 50.63,下降幅度较大,说明加入自变量后模型拟合显著改善。AIC / BIC:用于模型比较的指标,值越小越好(当前值可用于与其他候选模型的比较)
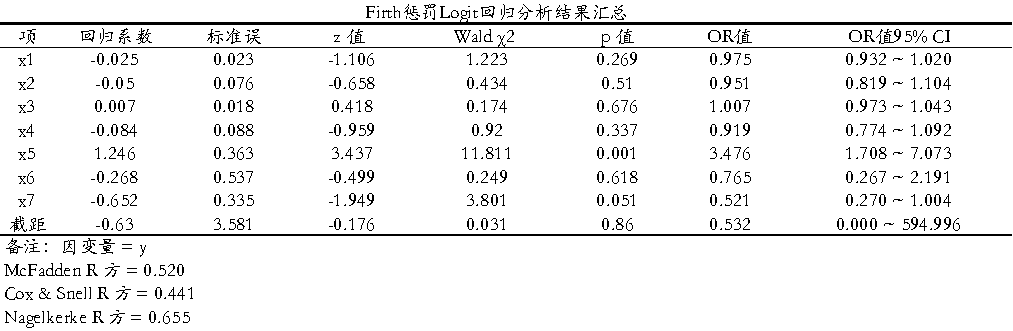
从上表格可知:
在参与建模的7个自变量中,只有x5对因变量y产生了真正的统计学显著影响(回归系数=1.246, p=0.001<0.01)。具体而言,x5的优势比(OR值)高达3.476(95%置信区间为1.708 ~ 7.073),这意味着x5每增加一个单位,发生目标事件(y=1)的几率就会暴涨至原来的3.476倍(即几率增加了2.476倍),表现出极强的正向促进效应,且其置信区间范围合理、没有虚高,结论极其稳健。相比之下,其余变量x1~x4、x6以及x7的p值均大于0.05(如x7的p值为0.051,刚好未达到0.05的显著性临界线),在统计学上均未表现出显著的独立影响。因此,在后续的研究结论、决策和论文撰写中,应当将全部核心精力聚焦在x5这一绝对主导的驱动因素上。
另外,McFadden R方= 0.520:通常McFadden R方在0.2~0.4即视为拟合良好,当前值0.520说明模型拟合效果较好而且Cox & Snell R 方为0.441较高。Nagelkerke R方 = 0.655:即修正后的伪R方,取值范围 [0, 1],接近0.68说明自变量对结局变量有较强的解释力。
-
提示:通常情况下Firth惩罚Logit回归对于R方值的关注度较小。

在模型预测效能方面,通过对真实值与预测值的交叉比对,该Firth惩罚Logit回归模型展现出了较好的整体分类精度与应用价值。在总计100例样本中,模型正确预测了79例,总体预测准确率达到了79.00%,分类错误率控制在21.00%。

上表格是SPSSAU单独输出的简化格式表格,通常用于发表期刊时直接使用。
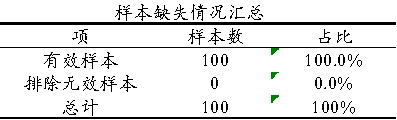
上表格展示真实进入算法模型时有效样本和排除在外的无效样本情况等。上表格中‘有效样本’指所有分析项均有数据的样本总数,‘排除无效样本’指任意一个分析项出现缺失的样本总数;如果某样本在任意一个分析项上出现缺失数据(即排除无效样本),该类样本无法进入模型分析,模型只能针对有效样本进行分析;可通过‘通用方法’里面的描述分析检查各分析项样本情况,也可在右上角‘查看数据’查看具体数据。
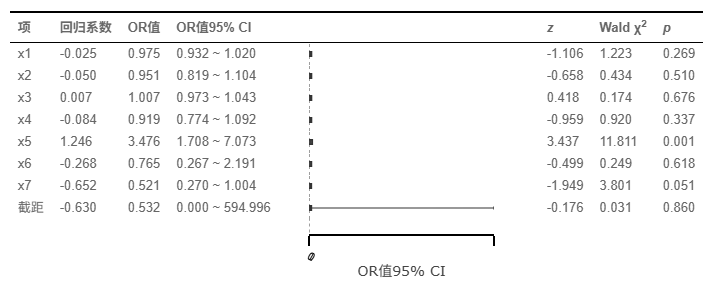
上图为SPSSAU输出的森林图,SPSSAU默认提供森林图,如果不符合预期,可使用'可视化'模块里面的森林图自主绘制森林图。
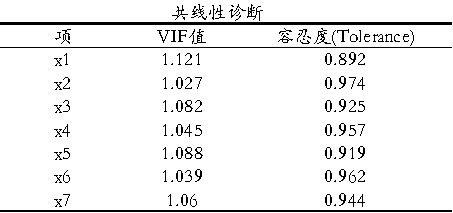
进行共线性诊断时,其原理是使用线性回归进行计算,结合VIF值等判断共线性问题程度等,上表格展示来看,当前七个X均没有共线性问题。
-
-
6、剖析
Firth惩罚Logit回归分析涉及以下几个关键点,分别如下:
-
Firth回归与标准二元Logit回归结果差异很大怎么办?
-
如果差异很大,说明数据存在明显的分离问题或小样本偏差。Firth的结果在这种情况下更可靠。建议进行敏感性分析:同时报告两种方法的结果,并说明差异原因。
-
为什么伪R方不叫R方?
-
McFadden R方、Cox&Snell R方、Nagelkerke R方 都称为"伪R方",它们不解释方差比例(不像线性回归的R方),而是基于似然比的拟合优度指标。McFadden R方 在 0.2~0.4 即视为拟合良好。
-
定类自变量的参照项怎么选?
-
参照项的选择不影响模型整体拟合,只影响系数的解读。一般选择有实际意义的组作为参照(默认是第1组)。
-
模型中能不能加入交互项?
-
交互项作为新的自变量加入即可,但需注意:加入交互项会增加参数数量,在小样本下可能导致模型的稳定性下降。使用SPSSAU数据处理-》生成变量功能进行处理得到交互项后,将其放入自变量X框中即可。
-
Firth回归能处理多分类因变量吗?
-
当前实现仅支持二分类因变量(y=0/1)。多分类问题需要使用多分类Logit回归。
-