
-
聚类分析用于将样本进行分类处理,通常是以定量数据作为分类标准;用户可自行设置聚类数量,如果不进行设置,系统会提供默认建议;通常情况下,建议用户设置聚类数量介于3~6个之间。
-
-
第一步:进行聚类分析设置
-
第二步:结合不同聚类类别人群特征进行类别命名
分析项 聚类分析说明 网购满意度20个题项 根据网购满意度情况判定,当前市场上共有几类人群?比如满意度差,一般,满意度高三类人群 -
-
分析结果表格示例如下(SPSSAU同时会生成饼图/圆环图/柱形图/条形图/折线图等):
聚类类别 频数 百分比(%) 聚类类别_1 82 41.4 聚类类别_2 61 30.8 聚类类别_3 55 27.8 合计 198 100.0 -
聚类类别(平均值±标准差) F p 类别1(n=82) 类别2(n=61) 类别3(n=55) 分析项1 3.23±1.33 2.88±0.73 2.63±0.81 3.73 0.03* 分析项2 2.62±1.48 2.57±1.21 2.32±0.76 0.56 0.58 分析项3 2.14±1.10 2.16±0.76 2.25±0.9 0.13 0.88 分析项4 0.88±0.91 3.32±1.02 3.82±0.85 2.67 0.07 分析项5 3.75±1.06 3.56±0.80 3.82±0.76 0.97 0.38 分析项6 4.56±0.72 4.42±0.61 4.57±0.68 0.72 0.49 分析项7 4.45±0.84 4.46±0.66 4.55±0.83 0.19 0.83 分析项8 4.18±0.96 4.24±0.67 4.36±0.74 0.46 0.63 * p <0.05 ** p <0.01 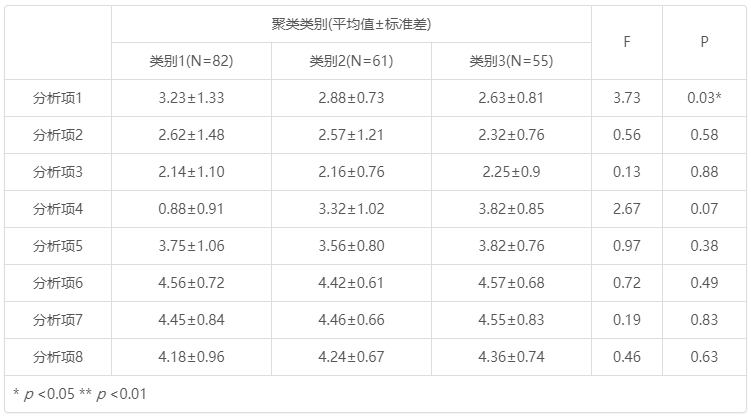
-
特别提示
-
聚类分析的具体聚类方法为K均值聚类;SPSSAU默认将聚类生成的类别保存起来,命名格式为:聚类类别_K均值聚类_******,并且结合聚类类别与聚类分析项进行方差分析,并且输出表格。
-
同时SPSSAU会输出聚类项的重要性对比图;在上表格中p 值越小时,说明类别间的差异越大,也即说明对应的该聚类项对于聚类的贡献会越大。正是基于此原理,SPSSAU对于聚类项的p 值进行处理成重要性指标,并且以图形输出。具体聚类项的重要性指标计算公式如下:-log10(p ) / max[-log10(p )];其中p 即为方差分析表格中的p 值,max[-log10(p )]代表-log10(p )的最大值。
-
-
-
疑难解惑
-
聚类分析与其它软件结果不一致?
-
Kmeans聚类(K均值聚类)算法的第一步是:“预将数据分为K组,则随机选取K个对象作为初始的聚类中心”,此第一步骤带有一定的随机性,但聚类算法的后续步骤会不停的迭代,最终得到最佳结果;不同的软件第一步随机种子选取会有不同,算法后续迭代会让第一步的‘随机性’不停的减弱,最终基本趋于一致。正是由于第一步的‘随机性’,因而任何不同的软件使用一样的算法,但聚类结果均有可能不同(但聚类结果中的类别划分绝大多数应该完全一致),这是正常合理且是由于算法决定的。
-
聚类分析前是否需要进行标准化?
-
聚类算法是根据距离进行判断类别,因此一般需要在聚类之前进行标准化处理,SPSSAU默认是选中进行标准化处理。数据标准化之后,数据的相对大小意义还在(比如数字越大GDP越高),但是实际意义消失了。
-
聚类中心是什么?
-
聚类中心是聚类类别的中心点情况,比如某类别时年龄对应的聚类中心为20,意味着该类别群体年龄基本在20岁左右。初始聚类中心基本无意义,它是聚类算法随机选择的聚类点,如果需要查看聚类中心情况,需要关注于最终聚类中心。实际分析时聚类中心的意义相对较小,其仅为聚类算法的计算值而已。
-
k-prototype聚类是什么?
-
如果说聚类项中包括定类项,那么SPSSAU默认会进行K-prototype聚类算法(而不是kmeans算法)。定类数据不能通过数字大小直接分析距离,因而需要使用K-prototype聚类算法。
-
聚类分析时‘标准化’选项对定类数据有效吗?
-
定类数据是不能进行标准化处理的,即SPSSAU选项中‘标准化’选中时只针对放入定量框中的数据有效。
-
聚类分析时SSE是什么意思?
-
在进行Kmeans聚类分析时SPSSAU默认输出误差平方和SSE值,该值可用于测量各点与中心点的距离情况,理论上是希望越小越好,而且如果同样的数据,聚类类别越多则SSE值会越小(但聚类类别过多则不便于分析)。SSE指标可用于辅助判断聚类类别个数,建议在不同聚类类别数量情况下记录下SSE值,然后分析SSE值的减少幅度情况,如果发现比如从3个聚类到4个类别时SSE值减少幅度明显很大,那么此时选择4个聚类类别较好。
-
SPSSAU聚类分析时,聚类效果的图示化?
-
可通过散点图直观展示聚类效果,使用任意两个聚类指标进行散点图绘制(可视化模块里面的散点图),并且在‘颜色区分(定类)[可选]框中放入‘聚类类别’项,以查看不同类别时,两两指标的散点效果。
-
k-prototype聚类时如何选择聚类个数?
-
k-prototype聚类时可结合平均轮廓系数值判断聚类个数,轮廓系数值介于[-1,1]之间,该值越大意味着越优(类似地,Kmeans聚类时也可使用该指标),各聚类类别的特征是否与实际相符,各聚类类别的样本量是否均匀,以及分析结果中方差分析和卡方检验的结果综合判断聚类个数。
-
k-prototype聚类时定类数据如何计算SSE值?
-
k-prototype聚类时包括定类数据,此时计算SSE值无实际意义,暂无文献提及k-prototype聚类时SSE值的计算,因而SPSSAU暂未提供。如果希望进行聚类个数优劣判断,可使用平均轮廓系数值,该值越大越好。
-
聚类分析时提示‘聚类达不到目标数量’?
-
出现此提示时,说明内部算法计算时发现某个聚类类别无法得到样本划分,此时建议减少聚类类别个数后再次分析即可。