
实际研究中,如果想研究两个定类数据之间的关系,那么可以使用交叉(卡方)分析。交叉(卡方)分析可以研究两个定类数据之间是否有着选择百分比差异性。但是如果希望使用图形直观展示关系情况,也或者想研究多个分类数据间的关系,并且使用图形直观展示,而且还需要看出类别间的具体关系情况。此时则可以使用对应分析。
对应分析(Correspondence analysis)也称关联分析、R-Q 型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。对应分析主要应用在市场细分、产品定位、地质研究以及计算机工程等领域相关中。
对应分析是一种视觉化的数据分析方法,它能够将几组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来。对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。对应分析最大的特点是具有直观性,而且它是一种直观、简单、方便的多元统计方法。
对应分析法整个处理过程由两部分组成:表格和对应图(也称关联图)。表格即为交叉表格,首先需要查看两个或多个定类数据之间是否真的具有关系(即具有差异性),确认定类数据具有关系之后,接着才需要查看对应图进一步分析关系情况。
-
特别提示:
-
对应分析分为两个步骤,第一步是查看交叉表,第二步是分析对应图;
-
对应分析可直观查看两个定类数据间的关系,并且使用图形直观展示;
-
对应分析可分析两个,或者多个定类数据之间的关系情况。
对应分析案例
-
1、背景
当前希望研究收入水平和手机品牌偏好之间的关系情况,比如收入水平低的人群更偏好A品牌,收入水平高的人群更偏好B品牌。并且使用图形直观展示出来。
-
2、理论
对应分析共包括两个步骤,第一步是分析交叉表;第二步是分析对应图。首先分析交叉表查看两两定类数据之间是否真的具有差异关系,如果有差异关系,那么对应分析才有意义,似想如果交叉分析显示没有差异关系,也即说明没有关系。那么图里面也看不出任何有意义信息。
对应分析的原理在于首先将数据降维,然后将具体数值点投影到维度空间中;维度只是个数学上的概念,并无实际名字意义,通俗理解为将‘关系’浓缩成‘几个维度’,比如将‘差异’关系浓缩成‘2个维度’。绝大多数情况下,对应分析只需要建立2个维度(SPSSAU默认值),因为这样只需要投影出一个对应图便于实际分析;如果维度个数超过2个,那么则会出现很多个对应图,这样会加大实际分析的难度。
-
特别提示:
-
如果仅分析两个定类数据时,此时也称作简单对应分析,此种情况在实际研究中使用非常广泛;如果超过2个定类数据时,此时也称作多元对应分析;
-
不论是简单对应还是多元对应分析,通常情况下,数据之间有着差异关系是对应分析的前置条件。如果是简单对应分析,SPSSAU默认会分析两个定类项间的差异关系;如果是多元对应分析,也可考虑进行两两项之间的交叉分析,查看是否具有差异性,再具有差异性后再进行对应分析。
-
-
3、操作
本例子使用加权数据格式,因此需要放置对应的加权项,维度个数默认为2个,操作如下图。
-
4、SPSSAU输出结果
SPSSAU共输出3个表格,分别是‘对应表’,‘模型汇总’,‘维度得分’,以及对应图。如下:
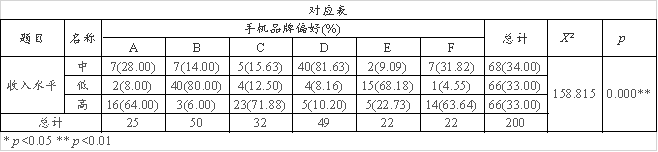
本次研究手机品牌偏好和收入水平共两项间的关联关系,因而使用简单对应分析进行研究。手机品牌偏好和收入水平进行交叉分析时呈现出0.05水平的显著性(χ2=158.815,p =0.000 <0.05),意味着二者有着差异关系,因此可继续进行简单对应分析。
-
特别提示:
-
具体差异关系情况当然也可以继续进行分析,但对应分析更关注于对应图,因此简要说明即可。
模型汇总 维度 奇异值 特征根值(惯量Inertia) 解释率 累积解释率 维度 1 0.697 0.486 61.188% 61.188% 维度 2 0.555 0.308 38.812% 100.000% 上表格展示模型情况,手机品牌偏好和收入水平之间的‘关系’,共由2个维度进行表示。而且第1个维度可以提取出这种‘关系’61.188%的信息,第2个维度可以提取出这种‘关系’38.812%的信息。2个维度提取出100%的‘关系’信息,即从数学角度来看,2个维度可以把‘关系’这种信息全部提取出来,因此说明模型非常好(通常情况下累积解释率达80%以上即说明模型非常好)。因而可接着进行对应图分析。
维度得分 标题 项 维度1得分 维度2得分 手机品牌偏好 A -0.781 0.795 B 1.437 -0.119 C -0.654 1.244 D -0.723 -1.568 E 1.066 0.348 F -0.884 0.701 收入水平 中 -0.668 -1.223 低 1.424 0.04 高 -0.736 1.22 上表格为维度得分表格,该表格即为对应图的具体坐标值。如果用户希望自己在EXCEL软件里面作图,因而可以直接复制此表格数据即可。此表格暂无其它意义。
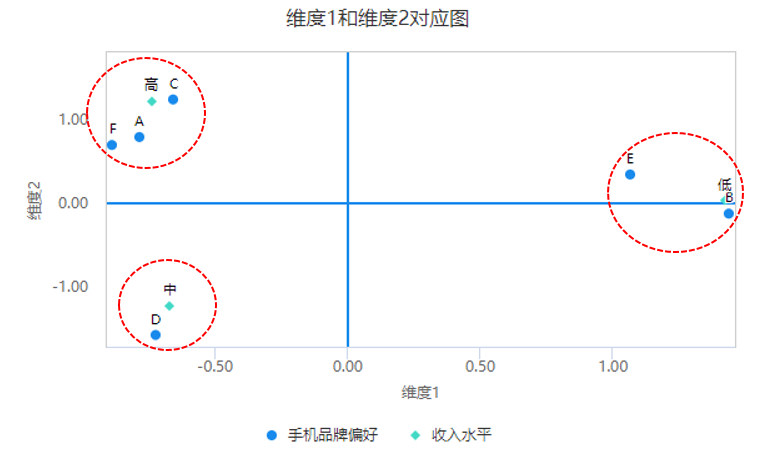
对应图是对应分析核心的结果,解读上共有以下几点。
-
第一、离原点越远,意味着该点对于‘关系幅度’的表达越强,即说明该点越能体现出‘关系’;
-
第二、点与点之间挨着越近,意味着它们之间关联关系越强;点与点之间挨着越远,意味着它们之间关联关系越弱;
-
第三、具体分析时,通常需要用‘圆圈’,圈出挨得较近的几点,同一‘圆圈’内的点,说明它们同属于一个范畴内。‘圆圈’通常是在PPT中自行绘制。
从上图可以看出,低收入群体与手机B、E品牌之间有着较强关系;同时中等收入群体与手机D品牌之间有着较强关系;高收入群体与A、C、F这3个手机品牌之间有着较强关系。通过分析可知:收入与手机品牌偏好之间,可细分出3个市场;低收入群体偏好于B、E品牌手机;中收入群体偏好于D品牌手机;高收入群体偏好于A、C、F三个手机品牌。
另外,低收入和B、E品牌,它们离原点的距离较远,意味着低收入与B、E品牌之间的关系非常明显。具体数字可通过对应表进行分析,对应表里面显示B品牌中有80%均为低收入群体。以及E品牌中68.18%均为低收入群体(相对来看,B品牌与低收入的关系更近,对应图也显示B与低收入挨得更近)。
-
-
5、文字分析
见上一部分。
-
6、剖析
涉及以下几个关键点,分别如下:
-
如果仅两个定数数据(简单对应分析时),SPSSAU支持非加权 (即普通格式)和加权格式。如果分析的定类数据超过两个(多元对应分析时),SPSSAU仅支持非加权数据格式(即普通格式);具体两种数据格式区别可参考页面: https://www.spssau.com/helps/otherdocuments/dataformat.html
-
对应分析的前提条件是两两定类数据之间具有关联关系,如果分析多个定类数据,建议先两两进行交叉分析(比如分析4个定类数据,则需要先确认此4个定类数据两两之间具有差异关系,需要进行6次交叉分析),确保数据确实具有差异关系后再进行对应分析。
-
对应图通常需要进一步手工加工,绘制‘圆圈’用于标识细分市场。此过程在PPT中进行处理即可。
-
疑难解惑
-
有多选题时如何组织数据格式?
-
如果涉及1个单选题与1个多选题的交叉,也或者1个多选题与1个多选题的交叉,SPSSAU在单选-多选,多选-多选这两个方法里面默认就有输出对应分析需要的数据格式,自己在EXCEL中整理下然后上传到SPSSAU中即可进行分析。
-
如果涉及多个单选题与多选题之间的交叉后想做对应分析,此时需要整理好数据格式然后上传进行分析,即将 多选题‘按行叠加’为单选题数据格式。