
-
-
有时候,我们需要判断一些事情是否将要发生,是否愿意购买,候选人是否会当选,是否患病等。这类问题的特点是因变量(Y)是定类数据,并且只使用两个数字去表示,规定为1和0,并且只能是1或0,比如1代表愿意0代表不愿意;1代表会0代表不会;1代表可以0代表不可以;1代表喜欢0代表不喜欢。如果想研究某些因素(X)对于因变量(Y)的影响关系,并且因变量(Y)只有两个取值时(并且只能是0和1),此时则可以使用二元Probit回归模型(也可使用二元Logit回归模型)。
-
类似于二元Logit回归,二元Probit回归模型的使用场景于二元Logit回归保持一致。二者的区别在于连接函数的不同。在实际应用中,二元Logit回归的使用更为广泛,可能原因在于二元Logit回归可以计算OR,OR值代表X增加一个单位时,Y的对应变化幅度,具有很好的现实意义。但在相关学科比如医学或者经济学科,二元Probit回归模型会输出边际效应值(dy/dx),此值也可表示X增加一个单位时,Y的变化幅度情况。具体使用二元Logit或者二元Probit回归模型,通常情况下无法严格的进行区分,建议医学、经济金融类相关学科可以使用二元Probit模型;其它学科使用二元Logit回归模型。也可以需要对比二元Logit或者二元Probit模型结果时,可以对比使用查看结果情况。
-
如果说Y对应的数字不为0和1;可以使用SPSSAU的‘数据编码’功能进行设置
-
-
SPSSAU分析结果表格示例如下:
二元Probit回归分析基本汇总 名称 选项 频数 百分比 是否患肺癌 非肺癌 113 75.333% 肺癌 37 24.667% 总计 150 100.0% 汇总 有效 150 100.000% 缺失 0 0.000% 总计 150 100.0% 模型似然比检验汇总 似然比卡方值 df p AIC 值 BIC 值 13.157 3 0.004 162.436 174.478 -
二元Probit回归分析结果汇总 项 回归系数 标准误 z 值 p 值 95% CI(LL) 95% CI(UL) 边际效应 性别(男) 0.646 0.242 2.669 0.008 0.172 1.121 0.194 年龄 -0.004 0.009 -0.395 0.693 -0.022 0.015 -0.001 是否吸烟 0.715 0.272 2.635 0.008 0.183 1.248 0.215 截距 -1.400 0.448 -3.126 0.002 -2.278 -0.522 - 因变量Y: 是否患肺癌 McFadden R 方: 0.079 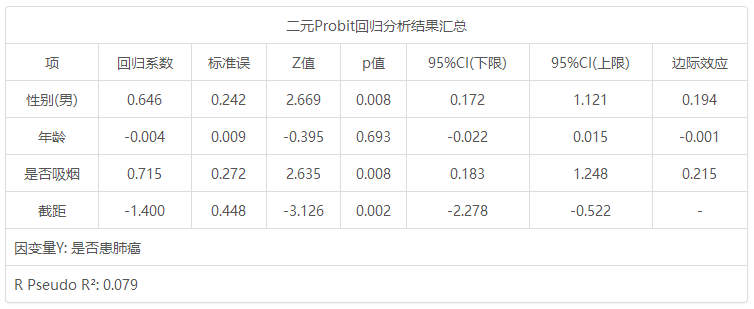
二元Probit回归案例
-
1、背景
当前有一份数据是用来研究影响患肺癌的因素,包括性别(男),年龄和是否吸烟共3个潜在的影响因素;以及被影响项为‘是否患肺癌’。由于Y为定类数据,并且只分为患肺癌和不患肺癌,因而适用于二元Probit回归分析。
-
2、理论
二元Probit回归分析用于研究X对于Y的影响关系,其中X通常为定量数据(如果X为定类数据,一般需要做虚拟(哑)变量设置),Y为二分类定类数据(Y的数字一定只能为0和1)。二元Probit回归分析时,首先分析p 值,如果此值小于0.05,说明具有影响关系,接着再具体研究影响关系情况即可,比如是正向影响还是负向影响关系等;除此之外,还可以写出二元Probit回归分析的模型构建公式,以及模型的预测准确率情况等。
-
特别提示
-
一定注意,Y对应的数字一定只能为0和1;如果不是,可以使用‘数据编码’功能进行设置
-
如果X为定类数据,通常情况下需要将X进行虚拟(哑)变量设置【SPSSAU中生成变量功能中有】。
-
如果X为定类数据,此时可以考虑使用卡方检验去研究X和Y的关系。
-
如果X非常多(比如超过10个),此时可以先对定类的X与Y进行卡方分析,对定量的X与Y进行方差分析(或非参数检验),先看有没有差异关系,将最终有差异关系的X放入二元Probit回归模型中,这样X会较少,并且X与Y均有差异关系,也更可能有影响关系,此时二元Probit回归模型的预测准确率会更高。
-
-
3、操作
本例子中研究X对于Y的差异;X分别为性别(男),年龄和是否吸烟,Y为是否患肺癌。放置如下:
-
4、SPSSAU输出结果
二元Probit回归分析基本汇总 名称 选项 频数 百分比 是否患肺癌 非肺癌 113 75.333% 肺癌 37 24.667% 总计 150 100.0% 汇总 有效 150 100.000% 缺失 0 0.000% 总计 150 100.0% 第一个表格仅仅统计下分析的基本情况,分析的有效样本量情况,意义相对较小。
模型似然比检验汇总 似然比卡方值 df p AIC 值 BIC 值 13.157 3 0.004 162.436 174.478 第二个表格用于模型检验,模型检验的原定假设为“是否放入X模型质量均一样”,此处放入三个X分别是性别(男),年龄,是否吸烟。而且p 值为0.004 <0.05,意味着放入三个自变量后,模型质量有明显的提升,因而拒绝原定假设,本次模型构建有意义。卡方值和df 值均为中间过程值可忽略。
以及AIC和BIC这两个指标值,可用于多个模型对比(AIC和BIC越小越好),当前放入3个自变量可记录下AIC和BIC 值,如果少放一个自变量(即2个时),AIC和BIC 值有着明显的下降,则可以选择2个自变量时的模型作为最终模型。
-
二元Probit回归分析结果汇总 项 回归系数 标准误 z 值 p 值 95% CI(LL) 95% CI(UL) 边际效应 性别(男) 0.646 0.242 2.669 0.008 0.172 1.121 0.194 年龄 -0.004 0.009 -0.395 0.693 -0.022 0.015 -0.001 是否吸烟 0.715 0.272 2.635 0.008 0.183 1.248 0.215 截距 -1.400 0.448 -3.126 0.002 -2.278 -0.522 - 因变量Y: 是否患肺癌 McFadden R 方: 0.079
第三个表格用于研究X对于Y的影响关系情况,表格中有意义的指标信息包括:p 值,回归系数,边际效应值和R Pseudo R 2。其它指标包括标准误,z 值,95% CI值意义相对较小。
-
二元Probit回归预测准确率汇总: 预测值 预测准确率 预测错误率 非肺癌 肺癌 真实值 非肺癌 113 0 100.00% 0.00% 肺癌 37 0 0.00% 100.00% 汇总 75.33% 24.67% 第四个表格输出模型的预测准确率情况,显示出Y本身为0,或者Y本身为1的前提下,的预测准确率或者预测错误率。以及最终整体的预测准确率和预测错误率等指标。在现实研究中,该指标使用频率非常低,仅在二元Logit模型中会经常使用。
-
5、文字分析
二元Probit回归分析基本汇总 名称 选项 频数 百分比 是否患肺癌 非肺癌 113 75.333% 肺癌 37 24.667% 总计 150 100.0% 汇总 有效 150 100.000% 缺失 0 0.000% 总计 150 100.0% 将性别(男),年龄和是否吸烟共3项作为自变量,而将是否患肺癌作为因变量进行二元Probit回归分析,从上表可以看出,总共有150个样本参加分析,并且没有缺失数据。
-
特别提示
-
上述自变量中,性别,是否吸烟均为定类数据,需要首先进行虚拟变量处理。本处处理后,性别(男)的数字中1表示男,0表示女性;是否吸烟的数字中1表示吸烟,0表示不吸烟。【虚拟变量设置参考: https://www.spssau.com/helps/otherdocuments/dummy.html 】
模型似然比检验汇总 似然比卡方值 df p AIC 值 BIC 值 13.157 3 0.004 162.436 174.478 进行二元Probit模型构建时,首先对于模型检验进行分析,模型假假设为是否放入自变量时质量均一致。从上表可知,p 值为0.004 <0.05,意味着本次模型构建有意义。
-
-
二元Probit回归分析结果汇总 项 回归系数 标准误 z 值 p 值 95% CI(LL) 95% CI(UL) 边际效应 性别(男) 0.646 0.242 2.669 0.008 0.172 1.121 0.194 年龄 -0.004 0.009 -0.395 0.693 -0.022 0.015 -0.001 是否吸烟 0.715 0.272 2.635 0.008 0.183 1.248 0.215 截距 -1.400 0.448 -3.126 0.002 -2.278 -0.522 - 因变量Y: 是否患肺癌 McFadden R 方: 0.079
从上表可知,将性别, 年龄, 是否吸烟共3项为自变量,而将是否患肺癌作为因变量进行二元Probit回归分析,从上表可以看出,模型伪R 2值(Pseudo R 2)为0.079,意味着性别, 年龄, 是否吸烟可以解释是否患肺癌的7.9%变化原因。从上表可知:模型公式为:Probit(p)=-1.400 + 0.646*性别(男)-0.004*年龄 + 0.715*是否吸烟(其中p 代表是否患肺癌为肺癌 的概率)。最终具体分析可知:
性别(男)的回归系数值为0.646,并且呈现出0.01水平的显著性(p =0.008 <0.01),意味着性别(男)会对是否患肺癌产生显著的正向影响关系,也即说明相对于女性,男性样本人群更可能患肺癌。年龄的回归系数值为-0.004,但是并没有呈现出显著性( p =0.693> 0.05),意味着年龄并不会对是否患肺癌产生影响关系。是否吸烟的回归系数值为0.715,并且呈现出0.01水平的显著性(p =0.008 <0.01),意味着是否吸烟会对是否患肺癌产生显著的正向影响关系,相对于不吸烟人群,吸烟人群更可能患肺癌。以及边际效应值为0.215,意味着吸烟人群比不吸烟人群患肺癌的比例加大21.45%。
总结分析可知:相对女性,男性更可能患肺癌,同时相对于不吸烟人群,吸烟人群更可能患肺癌,以及边际效应值为0.215,意味着吸烟人群比不吸烟人群患肺癌的比例加大21.45%。但是年龄并不会对是否患肺癌产生影响关系。
-
6、剖析
二元Logit回归分析涉及以下几个关键点,分别如下:
-
Y对应的数字一定只能为0和1;如果不是,可以使用‘数据编码’功能设置;
-
如果模型预测准确率较低,需要多次进行分析对比,找出最优的模型结果;
-
如果X是定类数据,此时需要对X进行虚拟(哑)变量设置【虚拟变量设置参考: https://www.spssau.com/helps/otherdocuments/dummy.html 】。
-
如果X的个数非常多(比如超过10个),此时需要进行甄别选择出有意义的X(比如使用方差分析,非参数检验或者卡方分析,选出X与Y有显著差异的X放入二元Probit回归模型中)。
-
疑难解惑
-
McFadden R 方、Cox & Snell R 方和Nagelkerke R 方相关问题?
-
Logit回归时会提供此3个R 方值,此3个R 方均为伪R 方值(并非像线性回归的R 方值意义一样),其值越大越好,但其无法非常有效的表达模型的拟合程度,意义相对交小,而且多数情况此3个指标值均会特别小,研究人员不用过分关注于此3个指标值。
-
‘Hosmer-Lemeshow拟合度检验’问题
-
Hosmer-Lemeshow检验(HL检验)为模型拟合指标,其原理在于判断预测值与真实值之间的gap情况,如果p 值大于0.05,则说明通过HL检验,即说明预测值与真实值之间并无非常明显的差异。反之如果p 值小于0.05,则说明没有通过HL检验,预测值与真实值之间有着明显的差异,即说明模型拟合度较差。
-
SPSSAU计算的HL检验与R软件、Stata软件等保持一致,但与IBM SPSS软件的结果有一定出入,这是由于边界问题的处理方式不一致。