
阅读随机森林模型前,建议首先阅读 决策树模型手册,因为随机森林模型实质上是多个决策树模型的综合,决策树模型只构建一棵分类树,但是随机森林模型构建非常多棵决策树,相当于在重复决策树模型。随机森林模型基于随机样本进行构建,并且在每个树节点时,考虑到分裂随机特征性,因而一般意义上,随机森林模型优于决策树模型(但并不一定,实际研究中应该以数据为准)。
上述中提及随机森林模型是多个决策树模型的综合,但是数据本身就只有一份,其是如何做到多个决策树模型呢?此处涉及到随机抽样原理,比如有100个数据,第1次随机从其中随机抽取100个数据,就得到一份新数据,即可使用该新数据进行一次决策树模型构建,接着第2次重复随机抽取100个数据,又得到一份新数据,再次使用新数据进行一次决策树模型构建。不停地重复循环上述步骤,即得到多个决策树模型;至于应该是多少个决策树,这可由参数设置决定。在得到多个决策树后,利用投票方式(比如多份数据均指向应该为A类别,那么就为A类别)或者求解均值概率方式来统计最终的分类结果。
除此之外, 随机森林的其它参数和指标解读,与决策树基本一致,因为其实质性原理为多个决策树模型的综合而已。
随机森林模型案例
-
1、背景
随机森林时依旧使用经典的‘鸢尾花分类数据集’进行案例演示,共为150个样本,包括4个特征属性(4个自变量X),分别是花萼长度,花萼宽度,花瓣长度,花瓣宽度,标签为鸢尾花卉类别,共包括3个类别分别是刚毛鸢尾花、变色鸢尾花和弗吉尼亚鸢尾花(下称A、B、C三类)。
-
2、理论
随机森林模型的原理上,其可见下图。
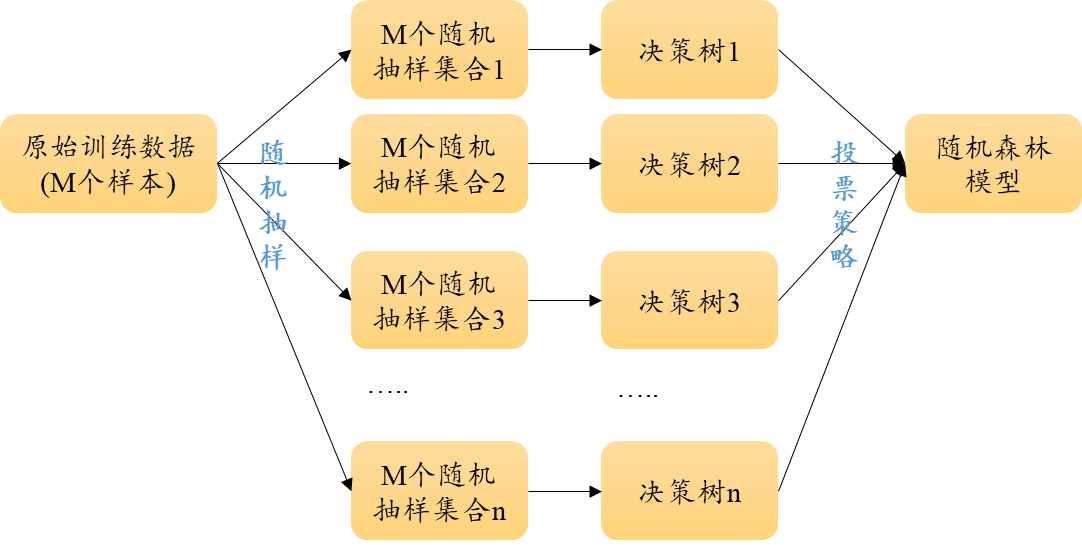
比如本案例有150个样本,使用80%即120个样本用于训练模型,并且训练3个决策树(此处3为决策树数量参数值,可自行设置),该3个决策树的数据是随机抽样得到,构建得到3个决策树后,使用投票策略进行最终决策,该述整个模型即为随机森林模型全貌。具体涉及相关参数信息,如下:
参数 说明 参数值设置 节点分裂标准 用于在构建决策树时产生分枝的依赖标准。与决策树完全一致。 gini: 默认,gini系数,计算速度快,一般用此选项。
entropy:信息熵,计算比gini系数大,效率低。最大特征数目限制 在构建每棵决策树时,能使用的最大特征数目。 auto:系统自动判断;
sqrt:特征总数的开平方;
log2:特征总数取2为底的对数。节点分列最小样本量 产生分支时,限制节点最小样本个数,用于决策树剪枝,防过拟合。与决策树完全一致。 大于等于2的整数,默认2。 叶节点最小样本量 限制叶节点最小样本个数,用于决策树剪枝,防止过拟合。与决策树完全一致。 大于等于1的整数,默认1。 树最大深度 限制决策树的最大深度,用于防止决策树规模过大。与决策树完全一致。 大于等于1的整数,默认不限制。 决策树数量 随机森林中,构建的决策树的数量。 大于等于3的整数,默认构建100棵。适当提高决策树的数量可增加稳定性和准确性。 是否有放回抽样 对样本进行采样时,是否有放回。 默认选中。 袋外数据测试(oobScore) 对于有放回采样,总会有一部分数据抽不到,称为袋外数据。选中此参数可以测试模型在这部分数据上的准确性。 默认选中。 上述参数中,节点分裂标准、节点分列最小样本、叶节点最小样本量和树最大深度共四个参数值,其与决策树模型完全一致,具体可参考决策树模型手册。
最大特征数目限制:随机森林构建多棵决策树,每棵决策树不一定使用全部的特征(即自变量X),其可只使用部分特征,此参数值设置使用特征数量限制,通常情况下不需要对该参数设置,系统自动判断即可。
决策树数量:默认值为100,即构建100模决策树,该参数值可自行设置,通常不需要设置,决策树数量越多,模型构建越稳定,但模型运行时间越长。
是否有放回抽样:随机抽样原理上,比如100个样本中抽100个,第1次抽到编号5,第2次是否还可能继续抽到编号5,如果是放回抽样则可能,如果是不放回抽样则不可能再抽到编号5,正常情况下应该使用放回抽样,尤其是在样本数据集较少时。
袋外数据测试:比如100个样本随机抽100个,某些样本重复被抽到,可能余下一些编号无论如何也没有抽到,该类数据称为‘袋外数据’,此部分数据可在测试数据中进行使用。该参数不被选中时,即测试模型不使用袋外数据进行测试。
随机森林时,通常可以对“节点分列最小样本量”、“叶节点最小样本量”、“树最大深度”进行参数设置,该3个参数值与决策树模型完全一致,可参考决策树模型手册。
-
3、操作
本例子操作如下:
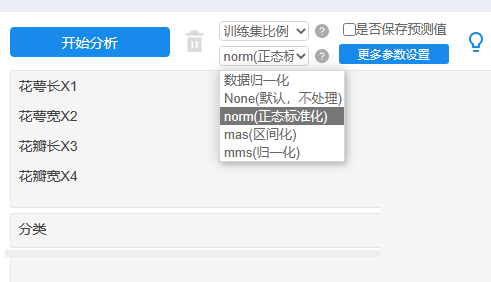
训练集比例默认选择为:0.8即80%(150*0.8=120个样本)进行训练随机森林模型,余下20%即30个样本(测试数据)用于模型的验证。需要注意的是,多数情况下,会首先对数据进行标准化处理,处理方式一般使用为正态标准化,此处理目的是让数据保持一致性量纲。当然也可使用其它的量纲方式,比如区间化,归一化等。
接着对参数设置如下:
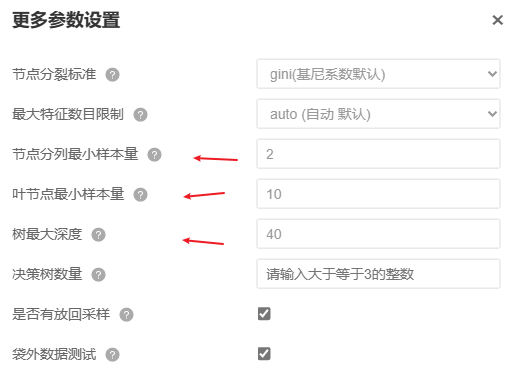
节点分裂标准默认为gini系数即可,不需要设置,最大特征数目限制默认自动进行即可,决策树数量SPSSAU默认为100,通常不需要设置,选中有放回采样和袋外数据测试。如果要进行参数设置,通过是对决策树模型已有的参数,包括“节点分列最小样本量”、“叶节点最小样本量”、“树最大深度”共3个参数进行设置,然后对比不同参数情况下模型的好坏,选择最优模型。本案例暂以默认值进行即可。
-
4、SPSSAU输出结果
SPSSAU共输出6项结果,依次为基本信息汇总,决策树结构图,特征模型图和特征权重图,训练集或测试集模型评估结果,测试集结果混淆矩阵,模型汇总表和模型代码,如下说明:
项 说明 基本信息汇总 因变量Y(标签项)分类数据分布情况等 特征模型图和特征权重图 用于特征的重要性情况分析 训练集或测试集模型评估结果 分析训练集和测试集数据的模型效果评估,非常重要 测试集结果混淆矩阵 测试集数据的进一步效果评估,非常重要 模型汇总表 模型参数及评估汇总表格 模型代码 模型构建的核心python代码 上述表格中,基本信息汇总仅展示出因变量Y(标签项)的分类分布情况,特征模型图和特征权重图可用于查看特征的相对重要性对比情况;模型评估结果(包括训练集或测试集),其用于对模型的拟合效果判断,尤其是测试集的拟合效果,非常重要,因而SPSSAU单独提供测试集结果混淆矩阵,用于进一步查看测试集数据的效果情况;模型汇总表格将各类参数值进行汇总,并且在最后附录随机森林模型构建的核心代码。
-
5、文字分析
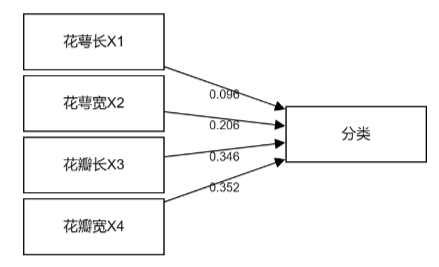
针对特征权重重要性对比上,X3和X4对于随机森林模型构建决策帮助较大,而X1的帮助相对最低(特别提示:此处与决策树模型结论差别较大,这在特征项较少且数据量较少时出现较为正常)。
接下来针对最重要的模型拟合情况进行说明,如下表格:
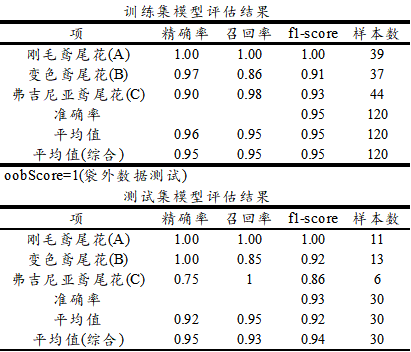
上表格中分别针对训练集和测试集,提供四个评估指标,分别是精确率、召回率、f1-scrore、准确率,以及平均指标和样本量指标等,如下表格说明:
项 说明 精确率 比如:预测为A类时,事实上是A类的比例,越大越好 召回率 比如:事实上是A类时,预测为A类的比例,越大越好 F1-score 精确率和召回率的调和平均数,越大越好,一般使用此指标较多 准确率 整体上全部数据预测准确的比例情况,越大越好,仅1个数字 平均值 对应指标的平均值,越大越好 平均值(综合) 对应指标的加权平均值(考虑样本量情况下) 样本量 各类别的样本量情况 具体上述具体指标的解读,可见决策树模型帮助手册,通常使用F1-score值进行评估即可,整体上,训练数据的F1-score值为0.95很高,而且测试数据时综合f1-score值为0.94,也很高(需要提示的是:在决策树模型时该值为0.906),意味着随机森林带来相对更优的预测结果。
接着可查看测试数据的‘混淆矩阵’,即模型预测和事实情况的交叉集合,如下图:

‘混淆矩阵’时,右下三角对角线的值越大越好,其表示预测值和真实值完全一致。上图中仅B类中2个样本被判断成C类,其余全部正确,意味着本次随机森林模型在测试数据上表现良好。最后SPSSAU输出模型参数信息值,如下表格:
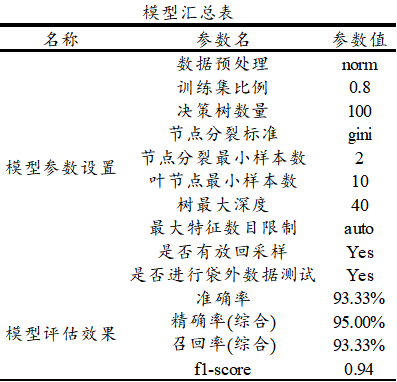
上述参数信息仅为再次输出汇总,并无其它目的,最后SPSSAU输出使用python中slearn包构建本次随机森林模型的核心代码如下:
model = RandomForestClassifier(criterion=gini, max_depth=40, min_samples_leaf=10, min_samples_split=2, n_estimators=100, bootstrap=True, oob_score=True, max_features=auto)
model.fit(x_train, y_train)
-
6、剖析
涉及以下几个关键点,分别如下:
-
随机森林模型时是否需要标准化处理?
-
一般建议是进行标准化处理,通常使用正态标准化处理方式即可。
-
训练集比例应该选择多少?
-
如果数据量很大,比如1万,那么训练集比例可以较高比如0.9,如果数据量较小,此时训练集比例选择较小预留出较多数据进行测试即可。
-
保存预测值
-
保存预测值时,SPSSAU会新生成一个标题用于存储模型预测的类别信息,其数字的意义与模型中标签项(因变量Y)的数字保持一致意义。
-
参数如何设置?
-
如果要进行参数设置,建议可将节点分列最小样本量往上调,叶节点最小样本量往上调,树最大深度可考虑设置相对较小值。设置后,分别将训练拟合效果,测试拟合效果进行汇总和对比,调整参数,找出相对最优模型。另建议保障训练集和测试集数据的f1-score值在0.9以上。
-
SPSSAU进行随机森林模型构建时,自变量X(特征项)中包括定类数据如何处理?
-
随机森林模型时本身并不单独针对定类数据处理,如果有定类数据,建议对其哑变量处理后放入,关于哑变量可 点击查看。
-
SPSSAU中随机模型合格的判断标准是什么?
-
机器学习模型中,通常均为先使用训练数据训练模型,然后使用测试数据测试模型效果。通常判断标准为训练模型具有良好的拟合效果,同时测试模型也有良好的拟合效果。机器学习模型中很容易出现‘过拟合’现象即假的好结果,因而一定需要重点关注测试数据的拟合效果。针对单一模型,可通过变换参数调优,与此同时,可使用多种机器学习模型,比如使用决策树、支持向量机SVM、神经网络等,综合对比选择最优模型。
-
随机森林更多参考资料?
-
更多关于随机森林的资料,可通过sklearn官方手册查看, 点击查看。
-
疑难解惑
-
拟合指标出现R方值小于0等异常?
-
机器学习时当出现指标异常比如R 方小于0,其从计算公式上是正常的,此时意味着该模型非常糟糕无法使用。除此之外可解释方差分EVS指标也会出现负数(在模型糟糕时)。
-
SPSSAU机器学习如何进行预测?
-
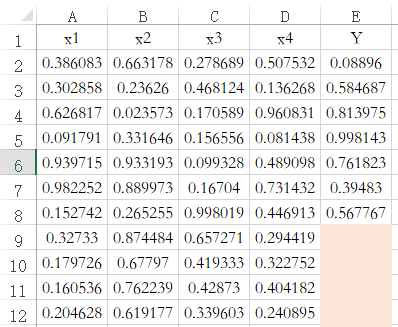
SPSSAU中默认带有数据预测功能,当特征项X有完整数据,但标签项(因变量Y)没有数据时,此时‘保存预测值’,SPSSAU会默认对此种情况进行预测。如下图中的编号9到12共4行数据,其只有X没有Y,那么保存预测值时,默认对该4行数据进行预测。机器学习的各方法(包括决策树/随机森林/KNN/贝叶斯/支持向量机和神经网络等)均遵从此规则。
-
SPSSAU机器学习中量纲归一化处理的具体规则情况?
-
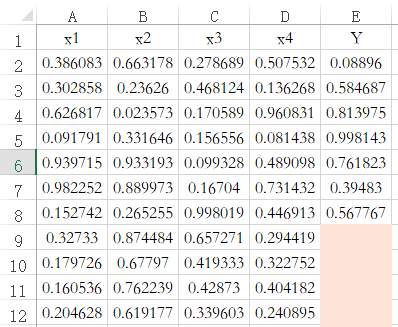
SPSSAU中,机器学习时均具有归一化参数值,并提供正态标准化/区间化/归一化等方式。其原理是针对具有完整数据的特征项X分别进行处理。比如下图中是针对编号为2~12共计11项的4个X分别进行处理。
-
机器学习中分类任务和回归任务的区别是什么?
-
机器学习包括分类任务和回归任务,当标签项(因变量Y)为类别数据时,其为分类任务,比如研究X对于“贷款是否逾期”的预测作用,“是否逾期”这个分类数据,因而此时此为分类任务。如果因变量Y为定量数据,比如研究X对于“贷款金额”的预测作用,“贷款金额”为定量数据,因而为回归任务。决策树/随机森林/支持向量机和神经网络等时,SPSSAU默认会对因变量Y进行识别,并且自动选择分类任务或者回归任务。当然研究者可以在“更多参数设置”处进行选择设置。另外,KNN和贝叶斯这两项仅提供分类任务。
-
机器学习时提示‘分类数据必须为整数’?
-
机器学习包括分类任务和回归任务,如果是定量数据Y进行分类任务,此时系统会提示“分类数据必须为整数”。决策树/随机森林/支持向量机和神经网络等时,可通过“更多参数设置”处进行选择设置,以及KNN和贝叶斯这两项仅提供分类任务。
-
分类任务和回归任务,输出拟合指标不同?
-
如果是分类任务(即Y为类别数据),此时会输出比如准确率、精确率、召回率、F1-score等评估指标,但当Y为定量数据(此时为回归任务),那么则会输出比如R方值,RMSE均方误差根,MSE均方误差等指标用于评估模型质量。分类数据可计算其是否预测正确,但定量数据只能计算预测值与真实值的接近程度,因而二者输出指标并不相同。另提示:SPSSAU会自动结合Y的数据情况自动选择分类或回归任务,当然研究者可自行通过参数设置。
-
如何将多个模型绘制ROC曲线对比优劣?
-
如果涉及多个模型预测能力绘制ROC曲线,用于多个模型预测能力对比。建议按以下步骤进行:
-
第1步是得到各个模型(比如神经网络模型、随机森林模型、logistic回归、Xgboost等)的预测值标题,该预测值可通过SPSSAU中‘保存预测值’参数选中后得到;
-
第2步是将得到的预测类别作为ROC曲线时的‘检验变量X’。此时绘制出来的ROC曲线则会有多条,分别表示各模型的预测值。与此同时,ROC曲线时的‘状态变量Y’为实际真实情况上的Y数据,并且该数据正常情况下为二分类(即仅包括2个数字即两个类别)。
-
【提示:比如决策树/随机森林/xgboost没有预测概率只有预测类别,此时则纳入预测类别。但比如神经网络/logistic回归可纳入预测概率或者预测类别均可】
-
机器学习算法时保存数据集标识的意思是什么?
-
选择‘保存数据集标识’后,SPSSAU会新生成一个标题,用于标识模型构建时训练集或测试集,使用数字1表示训练集,数字2表示测试集。如果后续分析时(比如绘制ROC曲线)只针对训练集,那么使用筛选样本功能,筛选出训练集后分析即可。
-
机器学习算法中保存预测信息具体是什么意思?
-
如果选中保存预测信息,并且为分类任务时,SPSSAU会新生成预测类别,预测类别是指最终预测出来Y的类别,预测类别标题名称类似为‘xgboost_Prediction_probability_****’,以及xgboost(以及决策树和随机森林)不会得到每个类别的预测概率。
-
为什么没有输出AUC指标及ROC曲线?
-
如果是分类任务并且为二分类(Y为分类数据且为二分类,且参数上默认或者选择为分类任务),此时SPSSAU默认会输出ROC曲线及AUC指标等。如果是多分类(Y为分类数据且大于两类,且为分类任务),此时AUC指标的意义较小暂未输出,如果有需要,可按下述步骤进行。
-
第1步:构建模型时先‘保存预测信息’,得到多个标题,每个标题对应1个类别时的预测概率;
-
第2步:将某个类别(即1个标题)的预测概率作为X,Y为模型构建时的Y,并且ROC曲线时分割点设置为放入的类别项对应的数字;
-
第3步:多个类别则重复进行多次,即得到每个Y类别标签的ROC曲线和AUC值等。
-
【提示:决策树、随机森林和Xgboost进行分类任务时只会得到预测类别,并不会得到预测概率,因而均不输出AUC或ROC曲线,当然研究者也可利用预测类别进行绘制ROC曲线,研究者自行处理即可】