
通常在综合评价后,比如计算得到准则层和指标层的分别权重之后(指标权重体系构建后),为了找到‘主要障碍因子’,此时可使用‘障碍度模型’(obstacle degree)进一步研究,以便进行障碍度情况对比(即影响程度)。比如某项关于‘城市公园综合表现’的研究,其目标是研究‘城市公园综合表现’,同时准则层包括3项,分别是‘公园规模’,‘公园配置’,‘公园服务’。并且3个准则层分别又包括对应的指标层。如下表格:
| 目标层 | 准则层(因素层) | 指标层 |
|---|---|---|
| 城市公园综合表现 | 公园规模 | 公园数量 |
| 公园面积 | ||
| 公园比率 | ||
| 公园配置 | 公园密度 | |
| 公园绿地面积占比 | ||
| 公园面积道路占比 | ||
| 公园服务 | 人均公园面积 | |
| 公园平均规模 | ||
| 公园服务人数 | ||
| 百万人均公园数 |
在计算好准则层和指标层权重后,希望进一步剖析‘障碍度’情况,此时即可使用‘障碍度模型’。如下述案例说明。
障碍度模型案例
-
1、背景
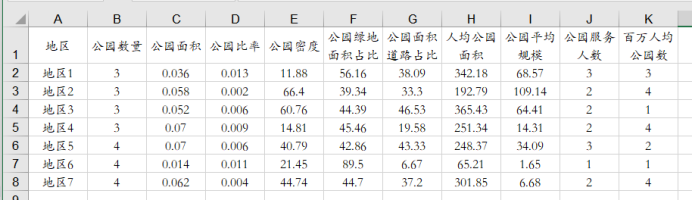
当前有7个公园,涉及3个准则层共计10个指标的数据,如下图所示:
并且在进行‘障碍度模型’分析前,已经计算各到3个准则层和10个指标层分别的权重数据,如下表格所示:
目标层 准则层/因素层(权重W) 指标层 指标层权重P 城市公园综合表现 公园规模(0.3345) 公园数量 0.3620 公园面积 0.3357 公园比率 0.3022 公园配置(0.2863) 公园密度 0.3426 公园绿地面积占比 0.3531 公园面积道路占比 0.3042 公园服务(0.3792) 人均公园面积 0.2086 公园平均规模 0.2587 公园服务人数 0.3457 百万人均公园数 0.1870 现在希望利用‘障碍度模型’,研究出影响‘城市公园综合表现’的重要因素情况。
-
2、理论
关于‘障碍度模型’的计算上,其通常分为以下几步:
-
第一步、计算F值,F值= W*P(W为准则层权重,P为指标层权重),且SPSSAU默认会对准则层对应的指标层权重进行归一化处理后计算;
-
第二步、计算R’标准化值,R’标准化值计算公式为:(X – min) / (max – min),即(某数据 – 该指标最小值) / (该指标最大值 – 该指标最小值);
-
第三步、计算I值,I值 = 1 – R’标准化值;
-
第四步、计算指标层O值,其计算公式如下:

-
第五步、计算准则层U值;其计算公式如下:

-
-
3、操作
本案例操作上共分为两步。第一步是将指标分别按‘准则层’情况放入对应分析框中,并且设置好准则层和指标层权重值,以及选择好参数。分别操作如下:
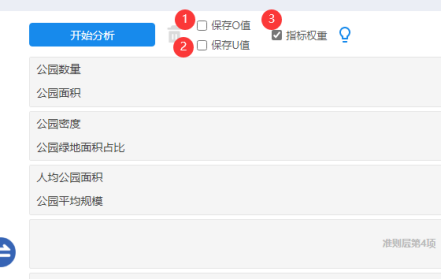
如上图所示:分别将10个指标层放入对应的3个‘准则层’框中。并且可以选择‘保存O值’或者‘保存U值’,如果选中‘保存O值’则会输出10个标题(每个指标一个O值),如果选中‘保存U值’则会输出3个标题(每个准则层一个U值)。另外关于‘指标权重’设置如下图所示:

上图展示准则层和指标层的权重设置,如果不进行设置直接‘确定’,则默认全部都是1。与此同时在SPSSAU算法上,会对每个‘准则层’下属的‘指标层’进行归一化处理后再进行计算。
-
4、SPSSAU输出结果
SPSSAU默认只会输出1个表格即F值计算表格,如下:

从上表格可以看到F值的计算过程,F值= W*P(W为准则层权重,P为指标层权重),且SPSSAU默认会对准则层对应的指标层权重进行归一化处理后计算。比如上表格中‘公园数量’对应的F值为0.1211=0.3345*0.3620。
-
特别提示:
-
如果说某个准则层下属的指标层权重加和不为1,此时SPSSAU会自动对其归一化处理,保证某个准则层下属的指标层权重加和为1,比如上表格中‘准则层第1项’时对应3个指标分别是:公园数量、公园面积和公园比率,该3项的权重(0.3620、0.3357和0.3022)如果加和不为1,系统会自动归一化处理让其加和为1。
-
除此之外,‘障碍度模型’最为关键的是计算得到O值和U值,指标个数即为O值个数,准则层数量即为U值数量。如果选中‘保存O值’或者‘保存U值’,SPSSAU系统会自动生成新标题用于标识,‘O值’的标题名称类似为‘标题_O值_****’,‘U值’的标题名称类似为‘准则层第1项_U值_****’,类似下图,研究者可通过‘我的数据’下载数据得到计算后的O值或U值等,用于进一步对比分析使用等。
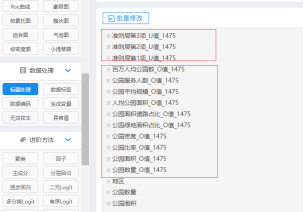

上图为本次案例计算得到的O值或U值,O值或者U值越大,即意味着‘某公园’在该项上的障碍度会越高,即影响程度越大。
-
-
5、文字分析
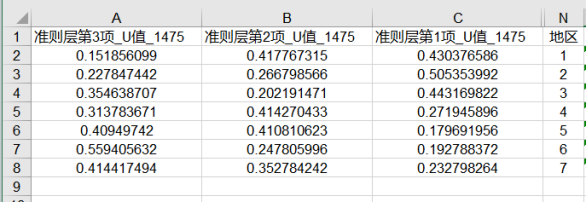
本案例针对U值进行分析,可将计算后的U值查看如下表格:
-
U值越大即意味着其‘障碍’越大,即影响程度越大。从上表格可以看见:
-
针对第1、2、3个地区来看,准则层第1项(公园规模)影响最大;
-
针对第4、5个地区来看,准则层第2项(公园配置)影响最大;
-
针对第6、7个地区来看,准则层第3项(公园服务)影响最大。
与此同时,还可针对具体10个指标进行类似的分析(或其它展示分析等),本案例不再赘述。
-
-
6、剖析
-
涉及以下几个关键点,分别如下:
-
如果选中‘保存O值’或者‘保存U值’,SPSSAU系统会自动生成新标题用于标识,‘O值’的标题名称类似为‘标题_O值_****’,‘U值’的标题名称类似为‘准则层第1项_U值_****’;
-
不论是是O值还是U值,该指标值越大,意味着其‘障碍’越大,即‘影响程度越大’;
-
在进行‘障碍度模型’分析时,通常需要确保分析指标数据均为‘正向化指标’(数字越大越优)。
-
疑难解惑
-
障碍度模型提示‘某标题数字恒定’?
-
如果某分析项(指标)完全是同一个数字,此时无法进行计算,建议使用通用方法里面的描述分析进行查看“最大值与最小值”相等的项,将该类项处理后重新上传分析即可。
-
障碍度模型使用的数据是什么?
-
障碍度模型使用的数据为计算权重时使用的数据,以计算权重时使用的数据为准即可(二者应该完全一致)。如果计算权重时的数据为正向/逆向化/标准化等数据,那则对应使用正向/逆向化/标准化的数据。
-
为什么障碍度模型出来结果少了一行?
-
如果某行数据对应的数字,均是其对应列数据的最大值时,可能在边界上就会出现null,因为障碍度模型算法公式上会先进行正向化处理,正向化处理后最大值则会为1,并且中间过程时还会进行1-该值处理,这样就会为0,如果某行全部均为最大值,对该行求和就为0,但是求和为0是不能作为被除数,但算法公式步骤中有该处理,因而就会出现null值。