新词发现
-
文本分析时,有些词是无法被词典识别到,比如‘元宇宙’这样的新词,以前的词典并没有它。因而可结合新词发现算法提供一些建议,新词发现具体算法可参考文章“基于信息熵和互信息的新词提取实现”,或者《互联网时代的社会语言学:基于SNS的文本数据挖掘》。
新词发现时涉及到两个关键指标,分别是:信息熵和互信息。信息熵的意义为衡量某词与其它词组合一起的容易度,比如‘宇宙’这个词与‘元’或者‘世界’组合一起变成‘元宇宙’或者‘宇宙世界’的容易度情况。信息熵越大即意味着某词越容易与其它词组合在一起形成一个词语,信息熵越小即意味着某词越不容易与其它词组合在一起。
互信息的意义为衡量文本组合的紧密程度,比如‘元’、‘宇宙’这两个词组合在一起的紧密程度情况。互信息值越大则意味着该两个词(或多个)组合在一起越牢固即越可能是一个新词,反之互信息值越小则意味着越不可能是新词。
-
提示:
-
结合信息熵和互信息的意义,一般情况下,新词更加可能为信息熵较高且互信息较高时出现。
-
信息熵越高意味着词更容易与其它词组合成新词,而且与其它词组合成新词的牢固度越高,即意义为‘信息熵’越高,‘互信息’越高时,越有可能是新词。
但具体情况还需要研究者结合新词发现和其实际意义进行综合决择,并无固定标准。而且通常还需要考虑词频情况,当一个‘可能新词’仅出现几次甚至更少时,加入新词的意义就很小。当判定为新词时,可批量将其加入到新词词库中,重新进行文本分析,以便得到更准备的文本分析结果。
在SPSSAU中,默认输入信息熵和互信息这两个指标,如下图所示:
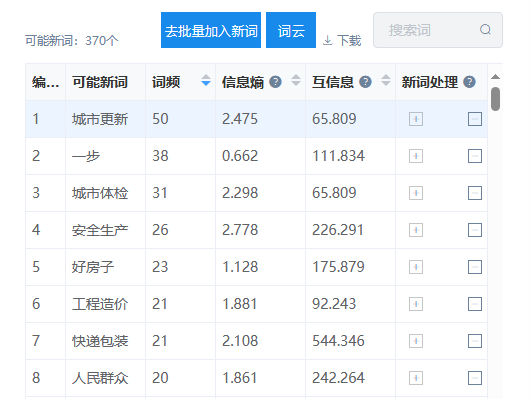
表格中输入‘可能新词’,其对应的词频信息,信息熵和互信息,当然如果判断为新词,可直接对该词加入新词词库(也或者移除出去),也可以‘批量加入新词’,通常是批量加入新词更加便捷。上表格时,可通过排序按钮查看可能新词的具体情况,当然也可以对其进行下载。
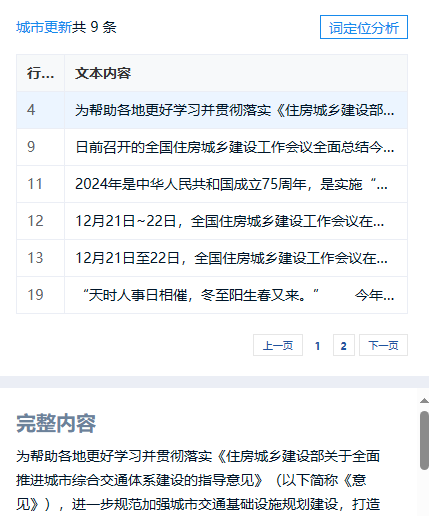
除此之外,还可点击某个‘可能新词’,查看其具体的词定位信息,比如点击‘城市更新’,右侧可查看其在文本数据中的具体位置和内容等,如下图所示:
为了更直观的查看各个‘可能新词’,也可点击‘词云’按钮直观展示,如下图所示:

-
特别提示:
-
信息熵和互信息的设定标准参考:在实际研究中一般取信息熵为0.5左右,互信息一般为50~200之间即可。
-
当然研究者可自行定义该两个指标值的标准,然后重新分析即可。操作如下图所示:
-

-