似不相关SUR回归
-
案例数据下载 下载
通常情况下,研究X对于Y的影响时,Y只能为一个,如果有多个则重复进行多次,即每次都只考虑单一方程估计,如果有多个Y时,将多个Y同时进行联合估计有可能会提高估计效率,即模型的拟合能力更加接近于实际数据。如果有多个Y需要同时估计,当前有两种处理方式,第一种是使用联立方程组进行估计,第二种方式则是使用似不相关回归(seemingly unrelated regression estimation,sur)进行估计。当然对多个y进行联合估计也有其缺点,比如某个Y时其估计误差较大则会对其他的Y模型首先污染进而影响整个模型,因而在实际研究中,通常也需要分别进行每个Y的OLS回归并且进行对比选择,以做到综合权衡决择。
SUR回归时,其也可以考虑空间作用关系,如果传入空间权重矩阵,那么则考虑空间性问题,如果不放入空间权重,则不考虑空间作用关系。如果是传入空间权重矩阵,即进行空间SUR回归模型,SPSSAU当前提供普通SUR模型(此时提供LM检验用于判断应该使用空间滞后SUR模型,还是空间误差SUR模型),空间滞后SUR模型和空间误差SUR模型。
似不相关SUR回归案例
-
1、背景
当前有一份空间数据,其为美国哥伦布市49个社区的相关数据,包括犯罪率(crime)、房价(hoval)和家庭收入(income),当前希望研究犯罪率分别对于房价和家庭收入的影响(此处即X为1个,Y有2个),并且在研究这一影响关系时考虑空间性,研究时可分别使用空间OLS回归进行分析,由于有2个Y因而进行两次,当然也可以直接进行SUR回归以期许提高估计效率。部分数据如下图所示:
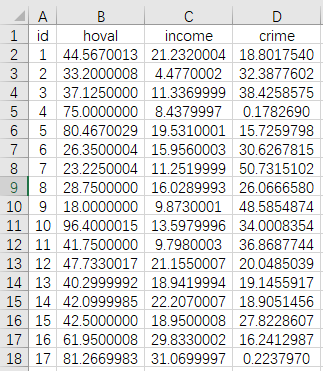
上面展示的是‘分析数据’,共有49个社区,该49个社区对应的‘空间权重矩阵’如下图所示:
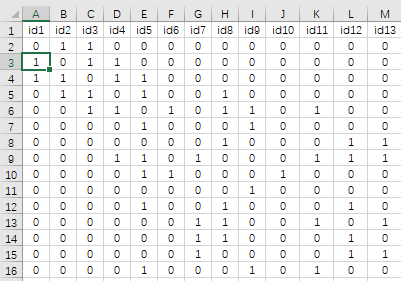
图中数字1表示两个空间点(社区)之间相邻,数字0表示两个社区不相邻。空间权重矩阵数据可点击此处下载。
-
2、理论
SPSSAU中,似不相关SUR回归时,如果不传入空间权重矩阵(即不选择空间权重矩阵文档),此时则为普通的似不相关SUR回归即不考虑空间作用的SUR回归;如果选择空间权重矩阵,则为空间SUR回归,如果是空间SUR回归,通常分析步骤如下:整理好数据(包括分析数据和空间权重矩阵)后,接着通过SUR模型提供的LM检验进行判断,判断应该使用空间滞后SUR回归模型,还是空间误差SUR回归模型等,然后选择对应的模型进行分析。
-
3、操作
本例子操作如下:
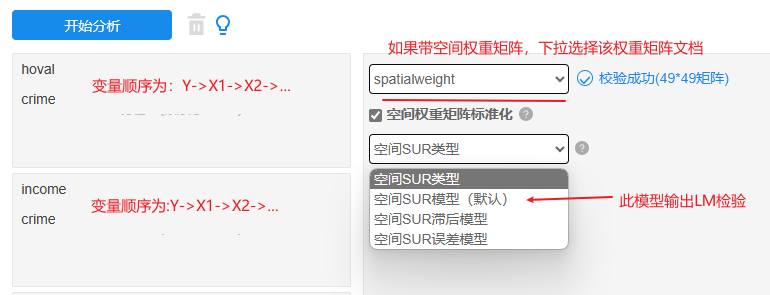
由于本文档案例时有两个方程,分别是犯罪率crime影响房价hoval,犯罪率crime影响家庭收入income,因而需要分别放入两个框中,框中放入的变量顺序为:Y-》X1-》X2-》…,即先放Y再放X。(另提示:SUR回归模型时很可能会使用到相同的标题放入不同框中,但一个标题只能放一个框里面,因而在EXCEL中复制整理好多个完全相同的标题然后上传即可)。
下拉选择‘空间权重矩阵’文档即spatialweight这份数据,默认对空间权重矩阵行标准化处理,需要注意的是,空间权重矩阵通常需要进行行标准化处理(如果不考虑空间性即不提供空间权重矩阵,那么直接不选择空间权重矩阵文档即可)。第1次分析时直接默认空间SUR模型即可,该模型会输出LM检验,用于判断最终应该使用空间SUR滞后模型或空间SUR误差模型等。
另需要提示的是,在使用空间计量相关的方法时,其均需要‘空间权重矩阵’和‘分析数据’两份数据,并且均需要单独上传到SPSSAU中,并且对‘分析数据’进行分析时,下拉选择对应的‘空间权重矩阵’,操作上分为以下3个步骤。
-
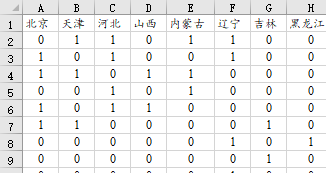
第1:上传‘空间权重矩阵’文档
此处需要注意:上传的数据需要为n*n阶格式,而且第1行为空间点的名称(比如31省市的名称)。类似下图格式:
-
第2:上传‘分析数据’文档
此处需要注意:比如31省市数据,‘空间权重矩阵’有着该31个空间点的顺序比如北京-》天津-》河北-》山西-》…,那么‘分析数据’的31行数据也需要按此顺序才可以。
-
第3:针对‘分析数据’进行分析,并且选择‘空间权重矩阵’文档
此处需要注意:进行某空间研究方法时需要下拉选择‘空间权重矩阵’,选择后,SPSSAU会自动判断其是否为‘空间权重矩阵’格式,包括是否为n*n阶结构,是否具有对称性等。如果不是则会进行信息提示,请勿必注意空间权重矩阵数据格式。
-
-
4、SPSSAU输出结果
SPSSAU共输出5个表格,分别是模型基本参数等、空间SUR模型LM检验汇总、空间SUR模型分析结果、回归系数是否相等Chow检验和空间SUR模型分析结果-简化格式,如下所述。
表格 说明 模型基本参数等 输出模型的基础参数值信息等 空间SUR模型LM检验汇总 输出LM检验,用于判断最终应该使用空间SUR滞后模型或空间SUR误差模型等 空间SUR模型分析结果 输出SUR模型分析结果 回归系数是否相等Chow检验 如果不同方程的X个数相同则提供,且需要研究者确认X是否完全相同,否则无意义 空间SUR模型分析结果-简化格式 输出模型结果的简化表格格式 -
5、文字分析

上表格模型的基本参数信息,包括具体的空间计量模型名称,空间权重矩阵名称及是否对其进行标准化处理等。

上表格展示LM检验结果,首先结合LM检验等判断应该使用空间SUR滞后模型还是空间SUR误差模型,也或者不考虑空间性的普通SUR回归模型;具体判断上:
针对LM-error和LM-lag进行分析,如果二者均不显著,则应该使用普通SUR模型即可(即不考虑空间性),如果仅其中一个显著,比如仅LM-error显著则使用空间SUR误差模型,如果仅LM-lag显著则使用空间SUR滞后模型;如果二者(LM-error和LM-lag)均显著,此时可使用二者中对应卡方值更大(此时p 值更小)时对应的模型,比如LM-lag检验的卡方值比LM-error检验时的卡方值更大,那么可使用空间SUR滞后模型。
本案例数据时:LM-error检验没有呈现出显著性(p =0.374>0.05),并且LM-lag检验没有呈现出显著性(p =0.750>0.05),建议使用普通SUR回归模型即可(此时不考虑空间性),即接下来输出的表格即为普通SUR回归模型结果。
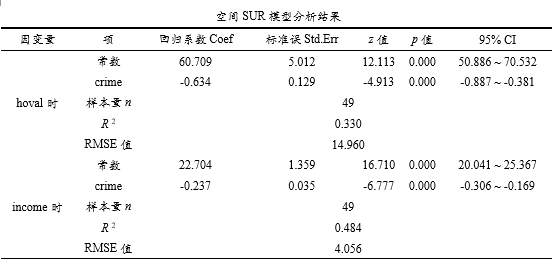
上表格展示似不相关SUR回归回归结果,并且为不考虑空间性时的结果。表格列出两个方程的结果信息,从表格可知,犯罪率crime会对hoval房价产生显著的负向影响关系,并且犯罪率crime也会对家庭收入income产生显著的负向影响关系。
-
提示:如果直接选中使用比如空间滞后SUR回归模型,或者空间误差SUR回归模型,那么系统会输出对应结果,本案例LM检验显示不需要考虑空间性,因而直接使用普通SUR回归结果即可(或者不选择空间权重矩阵文档参数即可)。

如果每个方程的X个数一致,则会对应输出回归系数是否相等Chow检验结果,比如本案例时2个方程的X均只有1个则输出,但需要注意的是,每个方程的X一致但是其意义可能不一致,通常情况下只有X变量一样时才有对比意义,此处需要研究者自行判断和识别。建议是X完全一致的前提时才使用上表格结果。比如上表格中显示两个方程时犯罪率Crime的回归系数有着显著的差异(p =0.002<0.01)。

上表格展示模型的简化表格格式,不再重复分析。
-
-
6、剖析
-
涉及以下几个关键点,分别如下:
-
如果不选择空间权重矩阵,则为普通的SUR回归,如果选择空间权重矩阵,则使用SUR回归模型时建议第一步是使用LM检验识别应该使用空间滞后SUR回归模型或者是空间误差SUR回归模型,并且使用Hausman检验判断应该使用FE模型或者RE模型。
-
疑难解惑
-
似不相关SUR回归时空间权重矩阵的数据格式如何?
-
空间SUR回归模型时,其空间权重矩阵格式为n*n阶,且沿对角线完全对称,主对角线数字为0表示空间点自己之间距离为0,且权重矩阵的顺序与分析数据的顺序需要保持一致性,比如权重矩阵是北京-》上海-》广东.这样的顺序,那么分析数据从上往下的顺序也应该如此。