OR/HR值进行Meta荟萃分析
-
案例数据下载 下载
与连续性数据或者二分类数据进行Meta分析类似,OR值(比值比)或者HR值(风险比)资料数据Meta分析是对OR或者HR资料数据进行综合评价。其分析与解读与连续性数据或者二分类数据类似。需要注意的是,OR值或者HR资料数据进行Meta分析时,需要提供对应值和95%置信区间值。如果说原始资料并未提供OR值(但其提供比如二元logitic回归的回归系数值),此时可对回归系数(或回归系数的95%置信区间)自行取其对数,得到OR值或OR值的置信区间后再分析。
OR值或HR值Meta分析荟萃分析案例
-
1、背景
当前有收集5篇文献均值数据资料如下:包括文献名称(Study)、资料数据如下,仅需要提供值及其对应的置信区间数据,并且在下述操作参数时标识当前提供的是OR值数据,如下图所示:
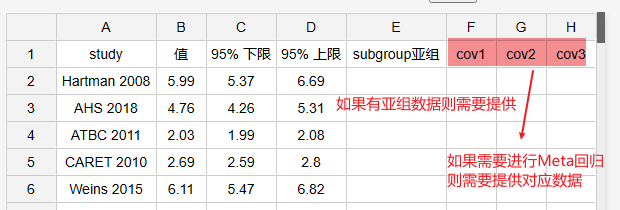
-
3、操作
本例子中操作截图如下:

需要注意的是,分析时需要标识当前提供的资料数据是OR值或HR值,一般来说,在二元logistic回归,有序logistic回归等研究资料中提供的是OR值数据。如果是Cox回归等生存数据,其提供的是HR值数据。
-
4、SPSSAU输出结果
Meta模型一共输出7个表格和5个图,说明如下:
表格/图名称 说明 基本信息表格 展示Meta模型的基本参数值信息等 效应量结果 展示核心的模型结果,包括合并效应及其置信区间,以及各研究文献的权重信息等 森林图 直观展示Meta分析结果 异质性检验 提供Q检验、tau2、I2、H及其置信区间、H2值等,用于异质性检验 发表偏倚检验 提供Egger检验和Begg检验 漏斗图 分析发表偏倚情况 Trim剪补法 展示基于Trim剪补法对应的‘校正合并效应’结果 漏斗图(Trim剪补法) 直观展示Trim剪补法后的漏斗图,用于分析发表偏倚情况 Meta敏感性检验 查看逐一剔除法后的合并效应情况 森林图(针对敏感性检验) 将敏感性检验结果使用森林图直观展示 累积Meta效应 展示累积Meta效应的结果汇总 森林图(针对累积Meta效应) 将累积Meta效应结果使用森林图直观展示 -
另需要提示的是:
-
如果有提供‘subgroup亚组’数据,那么系统自动会进行亚组分析,其会改变森林图/效应量表格结果等;
-
如果有提供协变量数据,并且要求进行Meta回归,那么系统还会提供Meta回归结果,以及Meta回归后的异质性指标信息等。
-
-
5、文字分析
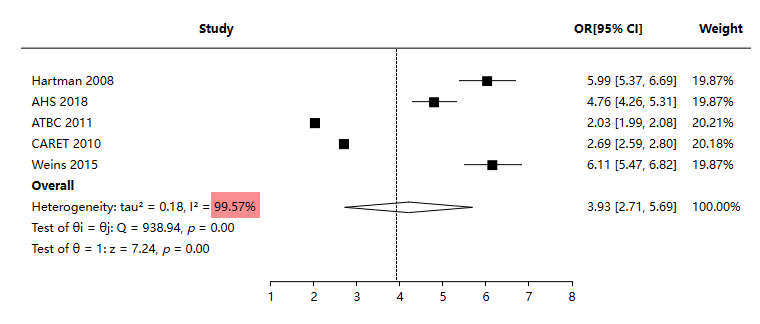
首先第1步关注异质性问题,从森林图可以看到,I2值为99.57%非常高,意味着异质性非常严重。当然处理异质性问题的方式很多,包括使用随机效应(当前即是默认使用随机效应默认),除此之外,还可自主分析异质性来源,使用亚组分析或者Meta回归分析等,并进一步决择等。从森林图上看,看上云是由于‘ATBC 2011’和‘CARET 2010’这两项导致了严重的异质性,因为该两项与另外三项有着明显差异。但如果将该2项移除,此时数据资料仅为3项过少,本案例尝试移除该2项后再次分析,得到森林图如下:
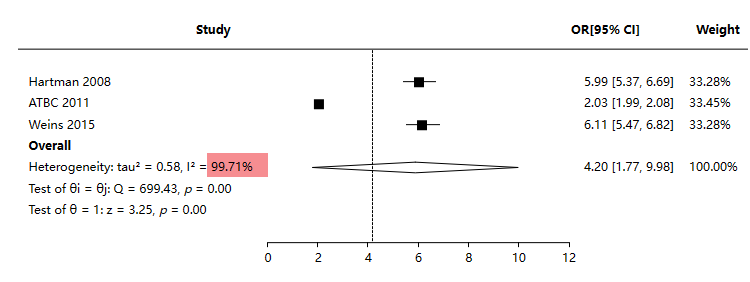
如上图所示,余下3项资料进行分析时,异质性问题并没有得到解决,原因在于余下3项之间的数据资料又具有严重的异质性问题。而且得到的合并效应,其置信区间非常宽,意味着数据集中度严重不够。这在实际研究中较为尴尬,建议研究者尽量收集齐全同类研究话题数据,并且结合实际情况,分别处理异质性问题严重的资料数据后再次分析。就当前案例数据而言是相对失败的资料数据,因为当前异质性问题非常严重,即使使用随机效应处理异质性问题,也有理由认为当前的资料数据质量较差。
至于其它的SPSSAU输出结果,包括发表偏倚结果,敏感性检验结果和累积Meta效应结果等,具体可见连续性数据或者二分类数据帮助手册,本文档暂不赘述。
-
6、剖析
Meta分析涉及以下几个关键点,分别如下:
-
Meta分析通常关注三项内容,分别是异质性问题,发表偏倚问题和稳健性问题;异质性问题具有多个检验指标,有时候可能出现不一致结论,建议综合进行决择判断,类似地,发表偏倚也有多种检验和查看方式,通常使用漏斗图查看和分析即可,Meta敏感性检验常用逐一剔除法。
-
疑难解惑
-
如果不满足异质性检验时如何办?
-
如果基本没有异质性问题,那么建议使用固定效应即可,当然此时使用随机效应也可以;如果说异质性问题不太严重,那么直接使用随机效应模型即可;如果说异质性问题非常严重,建议进一步查看导致异质性问题的原因并且处理后分析使用,包括使用亚组分析,Meta回归进一步查看原因,森林图直观查看并且移除异质性问题资料等。
-
如果不满足发表偏倚怎么办?
-
如果漏斗图发表散点不在漏斗内侧并且明显不对称,那么建议使用剪补法,并且最终使用修正后的合并效应结果。当然也可找出导致不对称的文献,并且移除该文献后再次分析。
-
如果没有通过敏感性检验怎么办?
-
SPSSAU中,敏感性检验使用逐一剔除法,综合对比和分析结论上的变化等。当然还可以有其它处理方法,比如一次性剔除两篇文献等,建议综合对比决择等。如果剔除某一文献后合并效应发表非常明显的变化,可考虑将该文献不纳入分析范围。
-
subgroup亚组的数据格式是什么样的?
-
亚组subgroup的原理是指比如10个Study,其为分为比如中文文献和英文文献共2组的意思,直接在对应subgroup数据列上加入对应Study的标签比如‘第1组/第2组’也或者‘中文文献/英文文献’即可。