
-
相关领域(比如医学研究)时,常常需要对同一观察单位重复进行多次测量,比如对病例在不同时间点进行多次测量,此类数据称为重复测量资料。由于此类数据同一对象多次测量之间存在相关性,因而不能简单的使用方差分析进行研究,而需要使用重复测量方差分析。
重复测量方差分析时涉及两个重要的术语名词,分别是组内和组间。比如有这样一项关于抑郁症的研究,共有12名患者,分别6名患者使用新药或者旧药;并且分别测试12名患者用药后分别第1周,第4周和第8周时的抑郁程度。因此数据中涉及到时间点的记录,和组别的记录。时间点则称之组内项;组别称为组间项;
组内项表示同一对象被测试多次的标识项(一个对象同时具有的特征);组间项表示不同对象组别的标识项(一个对象不能同时具有的特征)。组内项称为被试内,组间项也称作被试间。
-
特别提示
-
SPSSAU可研究0个,1个或者2个组间项的数据;
-
比如只测量12名患者3个时间点的抑郁程度,此类数据没有组间项;
-
比如测量12名患者3个时间点的抑郁程度,并且将12名患者分为两组,其中6名使用旧药,余下6名使用新药,此类数据有1个组间项;
-
比如测量12名患者3个时间点的抑郁程度,并且按照药物类型分为旧药和新药,并且按照是否高血压分为有和没有两类人群;此时则具有2个组间项。
-
重复测量方差案例
-
1、背景
当前有一项关于抑郁症的研究,实验共招募12名患者,分别6名患者使用新药或者旧药;并且分别测试12名患者用药后分别第1周,第4周和第8周时的抑郁程度。最终收集数据格式如下:
ID 药物类型 时间点 抑郁情况 1 新药 第1周 3 2 旧药 第1周 6 3 新药 第1周 4 4 旧药 第1周 3 5 新药 第1周 3 6 旧药 第1周 4 7 新药 第1周 4 8 旧药 第1周 3 9 新药 第1周 5 10 旧药 第1周 4 11 新药 第1周 5 12 旧药 第1周 4 ... ... ... ... -
特别提示
-
数据共分为四列,分别是ID号,药物类型,时间点和抑郁情况;
-
ID号标识患者的编号;药物类型标识某ID使用新药或旧药;时间点标识第1周,第4周或第8周;抑郁情况为测量值;
-
总共12名患者,每名患者测量3次,因此最终一定为12*3=36行数据;
-
ID号为1,3,5,7,9,11等奇数的患者使用新药;ID号为偶数的患者使用旧药;
-
重复测量方差对于数据格式要求非常严格,一定需要按照上述格式进行设置才可以;
-
重复测量方差需要为平衡数据,例子中12名患者,每名患者测量3次,则一定为12*3=36行数据,并且不能有缺失等;比如ID为5的患者在第8周没有测量数据,这会导致无法分析,有两种处理办法:第一种是直接将该ID为5的样本全部筛选掉,即相当于仅11个患者进行实验;第二种办法是将数据进行填补,可使用SPSSAU的异常值功能。
-
-
2、理论
重复测量分析共包括两大项,分别是组间项效应分析和组内项效应分析;比如本案例中两种药物疗效差异对比,即为组间项效应分析。如果希望对比不同时间点的疗效差异,即为组内项效应分析。组间项效应分析直接查看p 值即可;组内项效应分析需要进行球形度检验,并且结合检验选择适合的结果。
组内项差异分析步骤如下:
第一、首先进行球形度检验,p <0.05说明没有通过球形度检验,p >0.05说明通过球形度检验;
第二、如果没有通过球形度检验,并且球形度W值大于0.75,则使用HF校正结果;
第三、如果没有通过球形度检验,并且球形度W值小于0.75,则使用GG校正结果;
第四、如果通过球形度检验,组内效应分析结果时使用“满足球形度检验”结果即可;
-
特别提示
-
如果组内项仅2个水平,比如仅仅测量2个时间点的数据,那么不需要进行球形度检验。
-
-
3、操作
本例子中共有4例 ,分别包括测量数据‘抑郁情况’,组内项‘时间点’,患者编号‘ID’和组间项‘药物类型’,分别放置数据如下:
-
特别提示
-
绝大多数情况下,组间项仅为一个(有时甚至没有组间项)。SPSSAU支持组间项为0个,1个或者2个的情况。
-
-
4、SPSSAU 输出结果
SPSSAU共输出‘组间效应分析结果’,‘球形度检验’,‘组内效应分析结果’和组间项、组内项不同水平的均值对比表格,以及交互效应对比表格,并且输出图形(轮廓图)等。
5、文字分析
组间效应分析结果 项 平方和SS df 均方MS F p 偏Eta方(Partial η2) 截距 667.361 1 667.361 215.664 0.000 0.956 药物类型 0.694 1 0.694 0.224 0.646 0.022 误差 30.944 10 3.094 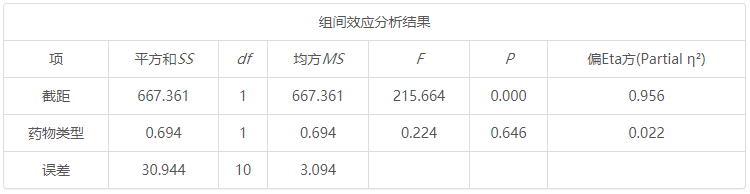
首先分析组间效应,即两种药物类型(新药和旧药)对于抑郁的差异性,上表可知:药物类型并没有呈现出显著性(F =0.224,p =0.646>0.05),说明新药和旧药对于抑郁症没有明显的差异,也即说明药物对于抑郁症治疗没有明显的帮助。
-
特别提示
-
如果呈现出显著性差异,具体可使用下述的表格和图形直接描述具体差异情况,当然也可以使用SPSSAU方差分析或事后多重比较进一步对比差异性等。
球形度检验 组内效应 球形度W值 球形度检验p 值 Greenhouse-Geisser(GG) Huynh-Feldt(HF) 时间点 0.463 0.031 0.651 0.708 在分析组内效应时,首先需要进行球形度检验,上表可知:研究数据没有通过球形度检验(p =0.031 <0.035),意味着需要进行校正处理。结合球形度W值可知,W值为0.463<0.75,意味着应该使用GG校正结果,如下表所述。
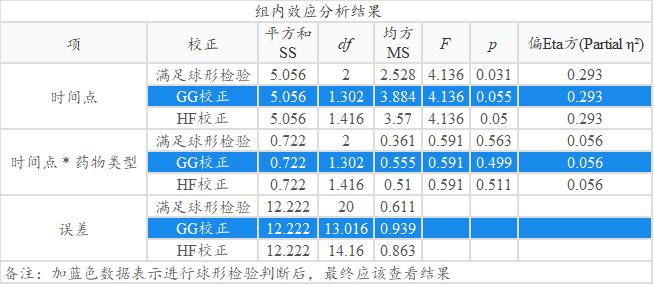
球形度检验显示最终应该使用GG校正结果,上表格中用蓝色标识出最终需要查看的结果值。对于时间点来看,其呈现出0.1水平的显著性(F =4.136,p =0.055 <0.1),即说明不同时间点时患者的抑郁症程度有着明显的差异性。同时对于时间与药物类型交互项上,其并没有呈现出显著性(F =0.591,p =0.499> 0.05),说明并不存在差异效应。
-
特别提示
-
当前时间项呈现出0.1水平的显著性,具体可使用下述的表格和图形直接描述具体差异情况,当然也可以使用SPSSAU方差分析或事后多重比较进一步对比差异性等。
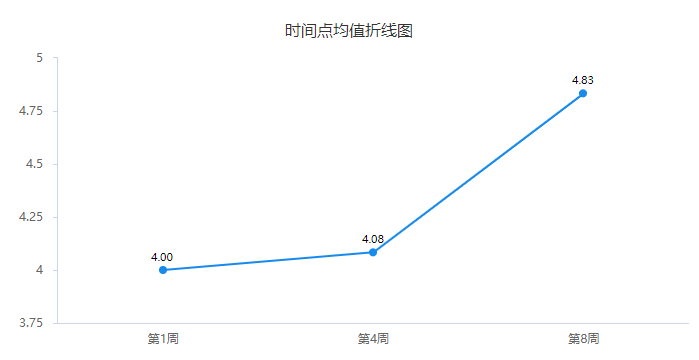
从上图可以看出:第1周时抑郁程度分值为4.00分,第4周时为4.08分,第8周明显上升为4.83分,说明随着时间的变化,患者抑郁情况有加重迹象,尤其从第4周到第8周变化时,抑郁程度分值由4.08分明显上升到4.83分。
6、剖析
涉及以下几个关键点,分别如下:
-
重复测量方差对于数据格式要求非常严格,组内项,组间项,样本ID和测量数据分别均需要占用一列。
-
重复测量方差需要为平衡数据,例子中12名患者,每名患者测量3次,则一定为12*3=36行数据,并且不能有缺失等;比如ID为5的患者在第8周没有测量数据,这会导致无法分析,有两种处理办法:第一种是直接将该ID为5的样本全部筛选掉,即相当于仅11个患者进行实验;第二种办法是将数据进行填补,可使用SPSSAU的异常值功能。
-
组内项分析时需要进行球形度检验,最终选择是否进行校正的方差分析结果,SPSSAU自动用蓝色标注出最终结果。
疑难解惑
-
数据格式应该是什么样的?
-
重复测量方差分析对数据格式要求严格,分别需要样本ID号,组内项,组间项(可选),和测量数据。建议查看SPSSAU案例的数据格式进行。
-
如果有缺失数据如何办?
-
重复测量方差要求为平衡数据,即不能有缺失数据,比如有12名被试,每名被试重复3次,则一定需要有12*3=36行数据;如果有某个被试数据缺失,那么可将该被试筛选出去;也可以先对数据进行填补(通常使用平均值)后再进行分析。
-
为什么没有呈现球形度检验值?
-
如果组内项仅2个水平(比如仅测量2个时间点的数据),此时不需要进行球形度检验。
-
如果呈现出有显著性差异,如何查看差异?
-
如果呈现出差异性,可通过图形,或者下面的平均值表格;也可以使用SPSSAU通用方法里面的方差,或者事后多重比较,进一步了解具体差异情况等。
-
自由度校正是什么意思?
-
如果没有通过球形度检验,则需要进行自由度校正,重新计算p 值;事实上F 值完全一样,仅自由度不一样,因而p 值可能并不一样。唯一的区别在于df 值不一样,比如满足球形检验时df 值为10,GG值为0.8,那么GG校正自由度为10*0.8=8。
-
如果对于分析使用的原始数据格式有疑问,请参考下面链接说明: https://www.spssau.com/helps/otherdocuments/methodsdataformat.html
-
事后多重比较的类型选择说明?
-
如果选中事后多重比较,SPSSAU默认会对组内项和组间项均地事后多重比较。具体多重比较类型上,通常建议使用Bonferroni校正法较优。如果各组别样本不同时可使用scheffe,如果各组别样本完全相同可使用tukey法等。具体可参考此页面: https://www.spssau.com/helps/advancedmethods/posthosmultiplecomparisons.html
-
事后多重比较与‘单独进行事后多重比较’结果不一致?
-
单独进行事后多重比较(进阶方法->事后多重比较法)时,模型实质上为单因素方差,仅考虑1个X的情况,标准误差的计算并不一致,因此结果会不一致,但通常情况下结论会保持一致;以及此处事后多重比较使用的是边际估计均值(偏最小二乘均值)与一般意义上的平均值有所区别,类似于SPSS软件的EMMEANS功能。SPSSAU默认针对组内项和组间项均进行事后多重比较。
-
简单效应是指什么?
-
简单效应指X1在某个水平时,X2不同水平的比较;SPSSAU进行简单效应时默认使用Bonferroni法进行计算p值。SPSSAU默认针对组内项(只针对组内项的第1项,若有多项,可互换位置)与组间项之间进行简单效应分析。
-
边际估计均值EMMEANS是什么?
-
在进行事后多重比较,或者简单效应时计算的‘均值差值’是基于‘边际估计均值’进行计算,实验研究中,如果为平衡数据,则‘边际估计均值’与平均值完全一样,如果为非平衡数据,‘边际估计均值’为平均值的‘矫正’,其更为科学和准确;通常来看,‘边际估计均值’和平均值应该非常接近,因为它们的测量意义完全一致。
-
提示类别数目过多!
-
针对组内项或组间项,最多支持20个类别。比如组内项为时间时,最多20个时间点。
-
事后多重比较,简单效应表格说明?
-
SPSSAU对事后多重比较,简单效应的表格输出说明如下:
-
第一、事后多重比较规则为:针对组内项和组间项(如果有)均输出事后多重比较;
-
第二、简单效应输出规则为:仅针对第1个组内项,分别与组间项(如果有)进行简单效应表格输出,如果组内项超过1个,可通过互换组内项的位置输出其余组内项与组间项的简单效应表格。
-
重复测量方差的ID值是什么意思?
-
重复测量方差时的ID指研究对象的ID,比如有100个病人,重复测量了4次,那么数据一共为400行,但是ID是从1到100,而且每个ID均需要重复4次。
-
如果重复测量方差是不平衡数据如何分析?
-
如果在进行重复测量方差分析时,数据不平衡,那么可选择其余两种分析方法进行研究,分别是HLM模型(医学研究里面的HLM)和广义估计矩阵GEE(医学研究里面的广义估计方程)。特别提示,需要注意对应的数据格式,数据格式可 点击查看
-
SPSSAU进行重复测量方差的简单效应输出逻辑顺序是什么?
-
重复测量方差分析的事后多重比较时,SPSSAU输出逻辑顺序为:组内&组间,组内&组内,组间&组内,组间&组间。如果没有组内项或组间项,则没有对应的简单效应表格,并且如果有多个组内项或多个组间项时,默认只对比第1项,研究者可通过改变组内项或组间项的放置顺序来获得结果。
-
针对简单效应输出具体说明如下:比如有2个组内项和2个组间项,名称分别为within1、within2、between1、between2,那么进行简单效应结果分别如下:within1 & between1、between2;within1 & within2;between1 & within1、within2;between1 & between2。
-
SPSSAU进行重复测量方差时提示‘数据格式不对’?
-
如果使用SPSSAU中出现数据格式不对的提示,可查看研究方法数据格式说明, 请点击查看
-
重复测量方差如何进行重测信度分析?
-
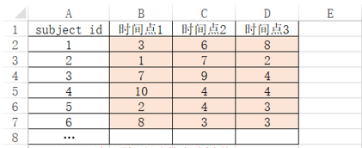
-
Sujbect_id表示被试ID号,但该项并不用放入分析框中。使用SPSSAU进行分析时,将时间点1,时间点2和时间点3放入分析框中。操作类似下图:
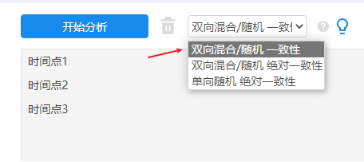
通常情况下选择‘双向混合/随机 一致性’即可,如果考虑测量误差,也可以选择‘双向混合/随机 绝对一致性’,一般不选择‘单向随机 绝对一致性’因此其是用于测量数据是否相等。 最后,在输出结果中,如果说重复测量分析数据是原始数据,那么使用‘单一度量’结果,如果重量测量分析数据是加工过的(比如求过平均值得到),那么使用‘平均度量’结果即可。
-
重复测量方差分析时输出组间效应表格和组内效应表格?
-
SPSSAU进行重复测量方差时,输出方差效应分析结果(其表格中包括组内效应和组间效应结果),并且分别单独输出组间效应表格结果,以及组内效应表格结果(包括横向和纵向两种样式)。与此同时,如果组内效应项仅2项(比如两个时间点时),其并不需要进行自由度校正,则可能不会输出组内效应表格结果。