Adaboost模型
-
案例数据下载 下载
AdaBoost(Adaptive Boosting)算法的核心思想是将多个弱分类器组合成一个强分类器。其算法步骤如下:
-
第一:初始化权重,为每个训练样本分配相等的初始权重;
-
第二:训练弱分类器,根据当前样本权重训练一个弱分类器,并计算其错误率;
-
第三:更新权重,增加错分类样本的权重,使后续弱分类器更关注这些样本,减少正确分类样本的权重;
-
第四:组合分类器,将所有弱分类器的加权结果组合起来,形成最终的强分类器;
-
最后:通过反复迭代以上步骤,AdaBoost 能够显著提高分类性能。
Adaboost模型案例
-
1、背景
当前有一项关于‘信用卡交易欺诈’的数据科学研究,已整理好数据共为1000条,其包括六项,分别是换设备次数,支付失败次数,换IP次数,换IP国家次数,交易金额和欺诈标签,欺诈标签时,数字1表示欺诈,数字0表示没有欺诈行为,现希望通过Adaboost进行模型构建,并且做一些预测工作,部分数据如下图所示:
-
2、理论
在进行Adaboost模型时,其涉及参数如下表所述:
参数 说明 参数值设置 损失函数 构建模型的算法方式,通常使用默认参数值即可。 其仅针对回归任务时使用。
linear: 使用预测误差的绝对值来衡量误差的大小。
square: 使用预测误差的平方来衡量误差的大小。
exponential: 使用预测误差的指数值来衡量误差的大小。学习器数量 用于构建的树的数量。 默认是50。 学习率 学习率即模型参数更新步长,越小收敛越快,但迭代次数越多。 范围(0.0, 1.0] 默认0.1。 任务类型 包括自动判断,分类和回归任务。 系统会结合Y的不同数字个数自动判断分类或回归任务,当然可自行选择分类或回归任务。 除此之外,与其它的机器学习算法类似,SPSSAU提供训练集比例参数(默认是训练集占0.8,测试集占0.2),数据归一化参数(默认不进行),以及保存预测值(Adaboost时会生成预测类别,但不会生成预测概率),保存训练测试标识(生成一个标题来标识训练集和测试集数据的标识)。
-
3、操作
本例子操作截图如下:
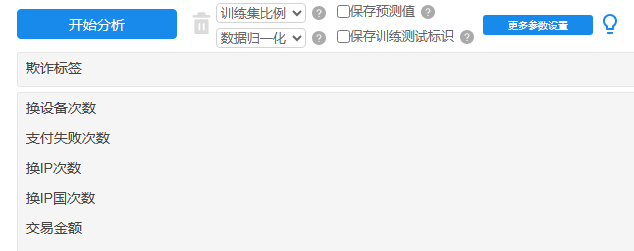
将欺诈标签放入Y框中,其余5个特征项作为自变量X。与此同时,训练集比例默认为0.8,暂不进行数据归一化,当然当前数据也可考虑做标准化处理,因为涉及数据的量纲不同。更多参数设置暂保持为默认值。
-
4、SPSSAU输出结果
SPSSAU共输出5项结果,依次为基本信息汇总,特征权重值,训练集或测试集模型评估结果,测试集结果混淆矩阵,模型汇总表和模型代码,如下说明:
项 说明 基本信息汇总 因变量Y(标签项)的数据分布情况等。 特征权重值 展示各个X(特征)对于模型的贡献力度。 训练集或测试集模型评估结果 分析训练集和测试集数据的模型效果评估,非常重要。 测试集结果混淆矩阵 测试集数据的进一步效果评估,非常重要。分类任务时提供,如果是回归任务则没有该矩阵。 模型汇总表 模型参数及评估汇总表格。 模型代码 模型构建的核心python代码。 上述表格中,基本信息汇总展示出因变量Y(标签项)的分类分布情况,模型评估结果(包括训练集或测试集)用于模型的拟合效果判断,尤其是测试集的拟合效果,以及提供测试集数据的混淆矩阵结果(如果是分类任务则提供,如果是回归任务则无该表格);模型汇总表格将各类参数值进行汇总,并且在最后附录模型构建的核心代码。
-
5、文字分析
首先针对特征的权重即重要性情况进行说明,如下图:
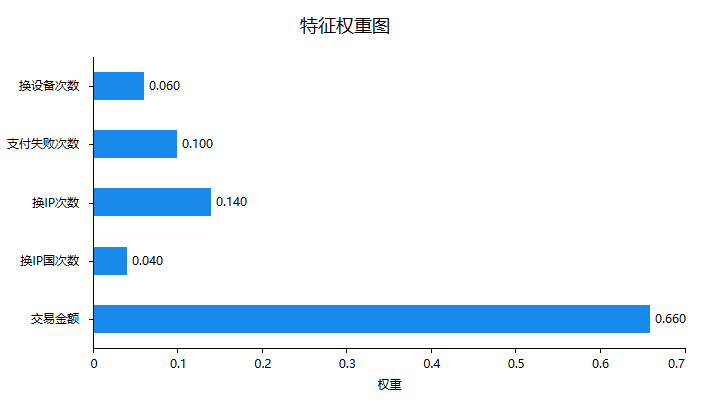
上图可以看到:交易金额对于是否欺诈行为有着非常重要的作用,明显高于其它几项。接下来针对最重要的模型拟合情况进行说明,如下表格:
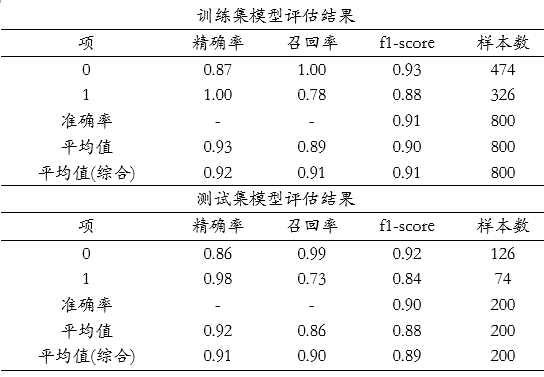
上表格中分别针对训练集和测试集,提供四个评估指标,分别是精确率、召回率、f1-scrore、准确率,以及平均指标和样本量指标等,整体来看,模型效果较好,因为无论是训练集还是测试集,F1-score值均高于0.9,其它指标比如精确率或者召回率指标,均接近或明显高于0.9,整体上意味着模型构建较优。
接着进一步查看测试数据的‘混淆矩阵’,即模型预测和事实情况的交叉集合,如下图:
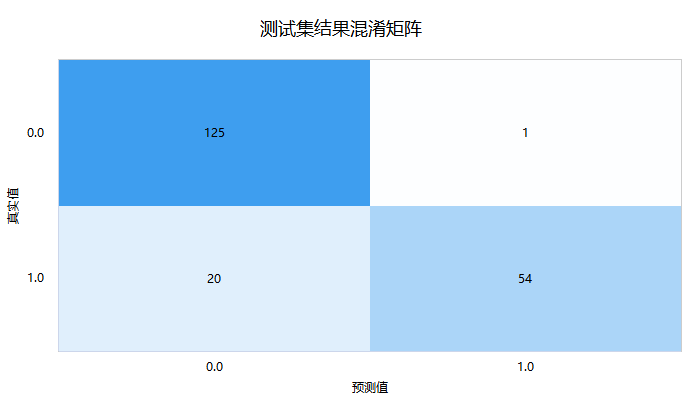
‘混淆矩阵’时,右下三角对角线的值越大越好,其表示预测值和真实值完全一致。上图中显示测试集时,真实值为1(即欺诈)但预测为0(即不欺诈)的数量为20,以及真实为0(即不欺诈)但预测为1(即欺诈)的数量为1,其余均预测正确,仅测试集共有200条,但预测出错为21条,出错率为10.5%。最后SPSSAU输出模型参数信息值,如下表格:
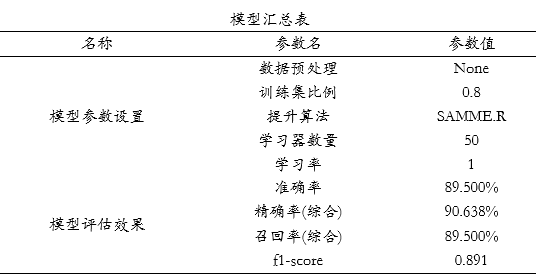
模型汇总表展示模型各项参数设置情况,最后SPSSAU输出使用python中slearn包构建本次Adaboost模型的核心代码如下:
model = AdaBoostClassifier(algorithm='SAMME.R', n_estimators=50, learning_rate=1.0')
model.fit(x_train, y_train)
-
6、剖析
涉及以下几个关键点,分别如下:
-
保存预测值
-
保存预测值时,SPSSAU会新生成一个标题用于存储模型预测的类别信息,其数字的意义与模型中标签项(因变量Y)的数字保持一致意义。但Adaboost不会生成类别的预测概率。
-
SPSSAU进行Adaboost模型构建时,自变量X(特征项)中包括定类数据如何处理?
-
logistic回归模型时通常不会关注于数据类型本身,如果一定要处理,建议可对定类数据进行哑变量转化后放入,关于哑变量可点击查看。
-
SPSSAU中Adaboost模型合格的判断标准是什么?
-
机器学习模型中,通常均为先使用训练数据训练模型,然后使用测试数据测试模型效果。通常判断标准为训练模型具有良好的拟合效果,同时测试模型也有良好的拟合效果。机器学习模型中很容易出现‘过拟合’现象即假的好结果,因而一定需要重点关注测试数据的拟合效果。针对单一模型,可通过变换参数调优,与此同时,可使用多种机器学习模型,比如使用决策树、随机森林、支持向量机、神经网络等,综合对比选择最优模型。
-
SPSSAU机器学习如何进行预测?
-
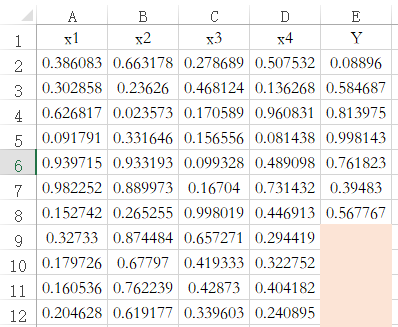
SPSSAU中默认带有数据预测功能,当特征项X有完整数据,但标签项(因变量Y)没有数据时,此时‘保存预测值’,SPSSAU会默认对此种情况进行预测。如下图中的编号9到12共4行数据,其只有X没有Y,那么保存预测值时,默认对该4行数据进行预测。机器学习的各方法均遵从此规则。
-
-
如何将多个模型绘制ROC曲线对比优劣?
-
如果涉及多个模型预测能力绘制ROC曲线,用于多个模型预测能力对比。建议按以下步骤进行:
-
第1步是得到各个模型(比如神经网络模型、随机森林模型、logistic回归、Adaboost等)的预测值标题,该预测值可通过SPSSAU中‘保存预测值’参数选中后得到;
-
第2步是将得到的预测类别作为ROC曲线时的‘检验变量X’。此时绘制出来的ROC曲线则会有多条,分别表示各模型的预测值。与此同时,ROC曲线时的‘状态变量Y’为实际真实情况上的Y数据,并且该数据正常情况下为二分类(即仅包括2个数字即两个类别)。
-
【提示:比如决策树/随机森林/Xgboost/GBDT/Adaboost/极端随机树/ LightGBM/CatBoost等均没有预测概率只有预测类别,此时则纳入预测类别。但比如神经网络/logistic回归可纳入预测概率或者预测类别均可】
-
机器学习算法时保存数据集标识的意思是什么?
-
选择‘保存数据集标识’后,SPSSAU会新生成一个标题,用于标识模型构建时训练集或测试集,使用数字1表示训练集,数字2表示测试集。如果后续分析时(比如绘制ROC曲线)只针对训练集,那么使用筛选样本功能,筛选出训练集后分析即可。
-
机器学习算法中保存预测信息具体是什么意思?
-
如果选中保存预测信息,并且为分类任务时,SPSSAU会新生成预测类别,预测类别是指最终预测出来Y的类别,预测类别标题名称类似为‘Adaboost _Prediction_****’,以及Adaboost不会得到每个类别的预测概率。
-
为什么没有输出AUC指标及ROC曲线?
-
如果是分类任务并且为二分类(Y为分类数据且为二分类,且参数上默认或者选择为分类任务),此时SPSSAU默认会输出ROC曲线及AUC指标等。如果是多分类(Y为分类数据且大于两类,且为分类任务),此时AUC指标的意义较小暂未输出,如果有需要,可按下述步骤进行。
-
第1步:构建模型时先‘保存预测信息’,得到多个标题,每个标题对应1个类别时的预测概率;
-
第2步:将某个类别(即1个标题)的预测概率作为X,Y为模型构建时的Y,并且ROC曲线时分割点设置为放入的类别项对应的数字;
-
第3步:多个类别则重复进行多次,即得到每个Y类别标签的ROC曲线和AUC值等。
-
【提示:决策树/随机森林/Xgboost/GBDT/Adaboost/极端随机树/LightGBM/CatBoost等进行分类任务时只会得到预测类别,并不会得到预测概率,因而均不输出AUC或ROC曲线,当然研究者也可利用预测类别进行绘制ROC曲线,研究者自行处理即可】
-