
倾向得分匹配(PSM),是一种将研究数据处理成‘随机对照实验数据’的方法,目的在于减少数据偏差和混杂因素的干扰。PSM一般在计量研究,医学领域等有着广泛的使用。
比如:当前想研究‘读研究生’对于收入的帮助,当前有收集1000个研究数据,有的已经读过研究生,有的没有读过研究生。一种简单的做法是直接对比‘读过’和‘没有读过’这两类群体的收入差异。但这种做法似乎‘不妥’,因为父母学历,父母是否做教育工作等因素都会干扰到研究。因此,PSM正是为了减少这种干扰。PSM可实现找到类似的两类人,他们的基本特征(比如父母学历,父母是否做教育工作等)都基本一样,但惟一的区别在于‘是否读过’研究生。这样可减少干扰因素差异带来的数据偏差和混杂干扰。
PSM一般用于计量研究里面,比如说某项‘政策’带来的效应研究。(比如是否开展‘禁塑令’,‘是否垃圾分类’,‘是否提供失业培训’,‘是否减免中小企业税收’等政策)。
除此之外,PSM在医学领域使用也较为广泛,比如临床研究做实验时对照组数据的寻找。比如想研究吸烟和心脏病之间的关系,是否吸烟两类群体个体匹配。‘为探讨某暴露或干预因素和结局之间的关系,因此需要与对照组进行比较,实验和对照组研究时会有因素的干扰,PSM的目的正是在于控制或减少非处理因素的干扰,突显处理因素效应情况’。研究因素是‘是否吸烟’,其它因素都叫做非处理因素(比如年龄,身高,体重等等),PSM可以减少这些非处理因素的干扰。
倾向得分匹配PSM案例
-
1、背景
当前有一项‘读研对于收入影响’的研究,共收集1000个研究对象(样本)。其中有的研究对象‘读研究生’,有的研究对象‘没有读研究生’,希望研究是否读过研究生,对于年收入的影响情况。数据最简单的处理是直接对比‘是否读研’两类群体的年收入差异。但这种做法有问题,因为之前研究显示,父母学历,父母是否从事教育相关职业,都会对‘是否读研’,以及‘年收入’有着干扰,即父母学历,父母是否从事教育相关职业这些因素为干扰因素,即使是都读研的两个人,父母的背景差异也会干扰到年收入情况。
正是基于此原因,因而使用PSM进行数据匹配,以期望父母背景尽可能一致的两个人前提下,分析是否读研时的年收入差异。
本次研究数据类似如下:‘父亲是否从事教育’和‘母亲是否从事教育’时,数字1表示从事教育相关行业,数字0表示没有从事教育相关行业。‘父亲学历’和‘母亲学历’上,数字1表示‘本科’,数字2表示‘硕士及以上’。是否读研上,数字1表示‘读过研究生’,数字0表示‘没有读研究生’。
-
2、理论
接下来阐述下PSM的算法原理,想要进行PSM,其算法步骤共分为3步如下:
第1步:进行Logit模型构建(得到Pscore)。
将研究因素比如‘是否读研’作为因变量,将其它因素(干扰因素,即不关注的因素但可能会有干扰的因素,比如父母学历,父母是否从事教育相关职业等)作为自变量X进行二元logit模型构建,并且得到预测值即PScore值,PScore值代表了干扰因素的整体水平情况。
PScore值如果越接近,那么说明两个样本(研究对象)的特征(即父母背景情况)越为接近,因此第2步进行match匹配时,直接是针对PScore值进行。
-
特别提示
-
此处的因变量Y(‘是否读研’)只能包括数字0和数字1,数字1表示实验组,数字0表示对照组。
第2步:Match匹配(得到Id,MatchId和Weight)。
第1步得到PScore值后,接着SPSSAU默认会对样本进行编号(即Id)。匹配时:针对研究因素Y为数字1时(即实验组数据,‘读过研究生’),去对应找到Y为数字0(即对照数据,‘没有读研究生’)中匹配的研究对象(样本)。
具体如何找到匹配对象,则是直接针对PScore值进行匹配,比如说PScore值完全相等,或者在可容忍的半径匹配范围内(阈值,卡钳值)。
如果找到满足条件的项,那么就说明匹配成功,当然有可能会匹配到很多个成功项,因此使用Weight用于标识匹配成功的次数。如果最终无法匹配成功,此时Weight为0,即说明匹配成功次数为0。
Weight用于标识匹配成功的次数,Weight值为0表示没有匹配成功,Weight值大于0说明匹配成功,因此后续研究时,一般需要先‘筛选’出Weight大于0的数据再进行分析。
第3步:PSM效果剖析。
无论如何匹配,最终均需要针对PSM匹配效果进行判断,并且也是核心(甚至是惟一)的标准。SPSSAU默认提供‘PSM平行假设检验’,即对比匹配前和匹配后的变化,用于判断PSM匹配效果情况。
‘平行假设检验’是一种综合性判断(并非只看一个指标),通常可从以下4个角度进行综合判断和分析,而不只是看某1个指标。
-
第1:一般情况下‘匹配后标准化偏差’绝对值小于20%即说明匹配效果较好。
-
第2:如果说匹配后的‘标准化偏差’有着明显的下降,说明匹配效果较好。
-
第3:使用t 检验法判断,如果说匹配后,t 检验并没有呈现出显著性,则说明匹配后‘实验组’和‘对照组’的数据特征基本一致,则说明匹配效果好。
-
第4:使用t 检验法判断,如果‘匹配前’ t 检验有显著性(p <0.05),但‘匹配后’ t 检验没有显著性(p >0.05),则匹配效果较好;
-
特别提示
-
PSM具体可细分为1:1匹配和1:N匹配,绝大多数情况下使用1:1匹配(SPSSAU默认);
-
SPSSAU进行PSM构建模型时,默认使用logit模型。
-
进行PSM分析后,SPSSAU提供4个数据信息,分别是PScore,Id,MatchId和Weight。PScore标识PSM匹配分值,Id和MatchId用于展示Id之间的匹配关系,Weight用于标识匹配成功的次数。
-
SPSSAU默认会首先进行精确匹配,即完全相等作为首要匹配因素。
-
SPSSAU提供两种匹配方法,分别是‘最近临法’和‘半径匹配’,‘最近临法’指找到PScore最接近的意思,‘半径匹配’指找到PScore在可接受范围(阈值,卡钳值)内,阈值越小匹配越精确,一般阈值设置为0.01或者0.02就好。
-
抽样方法上,默认使用‘放回抽样’,即某个样本(或研究对象)会被重复匹配多次。‘不放回抽样’指某个样本永远最多被匹配成功1次。一般计量研究领域使用‘放回抽样’较多,如果是医学研究可能使用‘不放回抽样’相对较多。
-
-
3、操作
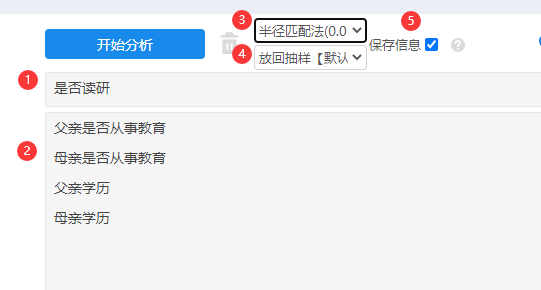
本例子使用PSM法进行数据匹配,研究‘是否读研’对于‘年收入’的影响,由于‘父亲是否从事教育’,‘母亲是否从事教育’,‘父亲学历’和‘母亲学历’这4项,会对研究起到干扰,因此进行PSM数据匹配,期望让‘是否读研’两类群体尽可能保持一致的父母背景特征。
PSM匹配时,使用半径匹配法,阈值(半径值)设置为0.01,并且使用放回抽样法进行分析。操作截图如下:
-
特别提示
-
SPSSAU中PSM算法包括‘最近临法’和‘半径匹配法’,二者并无固定区别,建议可对比使用,相对情况下‘半径匹配法’使用相对较多,‘半径匹配法’时需要设置阈值(半径值,卡钳值),该值越小越好,但越小意味着匹配精度要求越高,所以需要视情况而定,一般设置为0.01,0.02,0.05等均可接受。
-
放回抽样的效果一般会好于不放回抽样,但放回抽样的算法运行效率相对较低。
-
选中‘保存信息’后,SPSSAU会提供4个数据信息,分别是PScore,Id,MatchId和Weight。PScore标识PSM匹配分值,Id和MatchId用于展示Id之间的匹配关系,Weight用于标识匹配成功的次数。
-
-
4、SPSSAU输出结果
SPSSAU共输出2个表格和1个图形。分别是‘PSM基本信息汇总’,‘PSM平行假设检验’共2个表格,以及‘标准化偏差变化对比’图。分别如下:
PSM基本信息汇总表格:其包括匹配方式,抽样方法等基本信息,以及包括算法运行时,需要匹配个数,精确或者模糊匹配成功个数,匹配成功或者失败比例等过程信息。
PSM平行假设检验,此为PSM效果判断的核心(且惟一)表格,包括信息为,匹配前和匹配后时(不同实验组别,‘是否读研’两类群体)的干扰因素平均值,以及平均值对比的t 检验值,匹配前和匹配后的标准化偏差,和标准化偏差的减少幅度。
匹配前和匹配后时,Treated(实验组)和Control(控制组)的平均值为基本统计值,无实际意义,其用于计算标准化偏差,或者进行t检验的计算过程使用等。
‘标准化偏差’值用于衡量数据差异幅度,该值的绝对值才有意义,该值越小越好,一般小于20%即可(有时候小于30%),比如为20%则可简单理解为两组数据的差异幅度为20%。
‘标准化偏差减少幅度’用于衡量‘标准化偏差’值的减少幅度情况,该值大于0,说明匹配效果好于匹配前,该值小于0则说明匹配效果不如匹配前。该值越大越好,但并没有固定标准。
t 检验共输出t 值和p 值,只需要关于p 值就好。如果该值小于0.05,则说明实验组和控制组的平均值有着明显的差异,反之如果该值大于0.05则说明实验组和控制组的平均值没有明显的差异性。匹配前通常p 值都会小于0.05(说明匹配前干扰因素的特征不一致),而匹配后p 值希望是大于0.05(说明匹配后干扰因素的特征基本一致,即匹配成功了)。
标准化偏差变化对比图,直观展示‘标准化偏差’值的减少情况。
-
5、文字分析
PSM基本信息汇总 项 信息 匹配方式 半径匹配(精确匹配优先) 阈值(半径值或卡钳值) 0.01 抽样方法 放回抽样 需要匹配个数 233 精确匹配成功个数 233 模糊匹配成功个数 0 匹配成功个数(精确+模糊) 233 匹配成功比例 100.000% 匹配失败比例 0.000% 从上表可知:本次PSM分析使用半径匹配方式,并且精确匹配优先的算法,匹配半径值为0.01,且使用放回抽样方法。总共待匹配项(‘读过研究生’的样本数量)为233个,全部都实现精确匹配成功,匹配成功率为100%。
-
特别提示
-
此表格仅列出算法的过程信息等,具体匹配效果应以下表格即PSM平行假设检验表格为准。
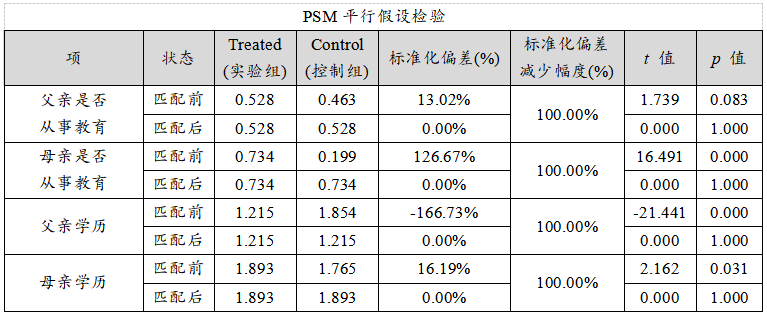
从上表可知:在匹配前,实验组和控制组(是否读研两类群体),他们的父母特征,包括母亲是否从事教育,父亲学历和母亲学历均有着显著性差异(p 值 <0.05),也即说明是否读研两类群体,他们的父母背景特征确实有着不一致性,父母背景特征属于干扰因素。
在匹配之后,‘父亲是否从事教育’,‘母亲是否从事教育’,‘父亲学历’和‘母亲学历’这4项干扰因素,在实验组(‘读过研究生’)和控制组(‘没有读研究生’)两组间并没有呈现出显著性(p 值>0.05),即说明匹配之后,实验组和控制组在父母背景特征上具有一致性。
同时针对标准化偏差值来看,在匹配之后,该值全部均为0,小于20%,即说明匹配之后,‘父亲是否从事教育’,‘母亲是否从事教育’,‘父亲学历’和‘母亲学历’这4项上,实验组和控制组的特征基本一致。(PS:本案例数据较好,因此匹配后标准化偏差完全为0%,实际研究中可能较少出现此类现象)
针对‘标准化偏差减少幅度’来看,该值为100%,也即说明PSM匹配后,实验组和控制组的个体特征差异性,得到了非常明显的改善。匹配前,实验组和控制组在干扰因素之间的平均值差异明显,但匹配之后,实验组和控制组在干扰因素之间的平均值差异不明显。
综合上述说明可知:此次PSM有着良好的效果,PSM匹配后数据可用于进一步科学研究使用。SPSSAU系统返回的weight信息数据,weight为0表示匹配成功次数为0,weight大于0说明肯定匹配成功(至少匹配成功1次),因此后续研究时,先筛选出weight大于0,然后再进行分析。比如本研究‘是否读研究生’对于‘年收入’的差异,因此可先筛选出weight大于0的数据,然后再进行t检验分析,对比‘是否读研究生’两类群体‘年收入’的差异性。
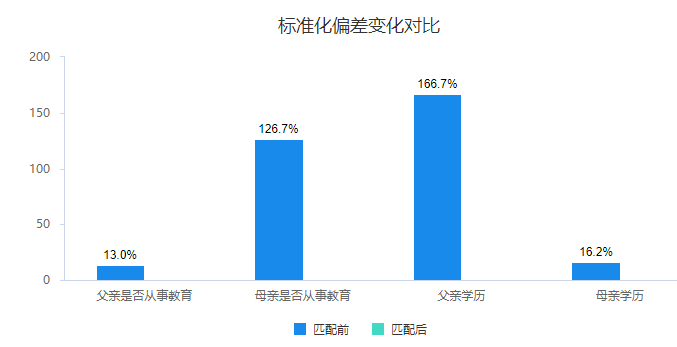
标准化偏差变化对比图,用于展示‘标准化偏差’绝对值的变化情况。上图可以看出,匹配后‘标准化偏差值’均为0%,说明匹配会让实验组和对照组数据时干扰因素特征的不一致得到明显的改善,意味着匹配效果良好。
-
-
6、剖析
涉及以下几个关键点,分别如下:
-
SPSSAU中PSM算法包括‘最近临法’和‘半径匹配法’,二者并无固定区别,建议可对比使用,相对情况下‘半径匹配法’使用相对较多,‘半径匹配法’时需要设置阈值(半径值,卡钳值),该值越小越好,但越小意味着匹配精度要求越高,所以需要视情况而定,一般设置为0.01,0.02,0.05等均可接受。
-
放回抽样的效果一般会好于不放回抽样,但放回抽样的算法运行效率相对较低。
-
选中‘保存信息’后,SPSSAU会提供4个数据信息,分别是PScore,Id,MatchId和Weight。PScore标识PSM匹配分值,Id和MatchId用于展示Id之间的匹配关系,Weight用于标识匹配成功的次数。
-
SPSSAU系统返回的weight信息数据,weight为0表示匹配成功次数为0,weight大于0说明肯定匹配成功(至少匹配成功1次),因此后续研究时,先筛选出weight大于0,然后再进行分析。
-
PSM具体可细分为1:1匹配和1:N匹配,绝大多数情况下使用1:1匹配(SPSSAU默认);
-
SPSSAU进行PSM构建模型时,默认使用logit模型。
-
SPSSAU默认会首先进行精确匹配,即完全相等作为首要匹配考虑因素。
-
疑难解惑
-
匹配效果较好如何办?
-
PSM平行假设检验用于判断匹配效果,而且匹配效果是综合各项指标判断。如果各项指标均‘很差’,可以考虑以下几种做法,分别是:修改匹配方式,修改半径匹配的阈值,修改抽样方式,以及更换干扰因素项等,多次尝试对比找出最优结果即可。同时,PSM匹配并无完美的匹配效果,通常综合各项指标分析,在可接受范围内即可。
-
匹配之后如何进行后续研究?
-
选中‘保存信息’后,SPSSAU系统返回的weight信息数据,weight为0表示匹配成功次数为0,weight大于0说明肯定匹配成功(至少匹配成功1次),因此后续研究时,先筛选出weight大于0,然后再进行分析。
-
倾向得分匹配PSM如何选择阈值(半径值,卡钳值)?
-
半径匹配法时时需要设置阈值(半径值,卡钳值),该值越小越好,但越小意味着匹配精度要求越高,所以需要视情况而定,一般设置为0.01,0.02,0.05等均可接受。当然也可以先设置较高的阈值(比如0.2),然后再逐步对比设置较低阈值,直到效果满意为止。
-
ATT效应表格是什么意思?
-
SPSSAU进行倾向得分匹配时,SPSSAU默认提供未配对前的研究变量与结果变量独立t 检验结果,并且提供ATT效应值。另提示,stata计量软件的psmatch2包中提供的t 检验是假定数据等方差得到,spssau默认判断数据是等方差(方差齐)或方差不齐时两种情况,并智能提供两种不同情况下时的t 值,因而二者结果中的t 者可能不同。
-
SPSSAU 进行PSM分析时没有提供ATT值?
-
如果没有放入结果变量则不会输出ATT值,将结果变量放入对应框中再次分析则会输出ATT值。
-
倾向得分匹配PSM时使用核密度图判断匹配效果?
-
SPSSAU在‘可视化’模块中单独提供核密度图功能,可单独使用,用于判断匹配前和匹配后效果情况对比【分别查看匹配前,匹配后,不同组别的Pscore值的核密度分布情况】。
-
SPSSAU如何进行common support check(共同支撑检验)?
-
共同支撑检验可通过SPSSAU中的核密度图进行检验,其原理在于对比匹配前和匹配后的倾向得分值pscore分布情况变化。共分为4步。
-
第1步:得到pscore值,在SPSSAU倾向得分匹配时选中‘输出信息’可得到;
-
第2步:针对匹配前的pscore绘制核密度图,查看控制组和实验组的核密度图(即X放入实验组别项),控制组和实验组分布应该差异较大;
-
第3步:针对匹配后的pscore绘制核密度图(筛选出匹配成功次数weight>0后再分析),查看控制组和实验组的核密度图,控制组和实验组分布应该差异较小。
-
第4步:如果匹配前控制组和实验组分布差别较大,但匹配后控制组和实验组分布差别较小,则说明满足‘共同支撑检验’。
-
倾向得分匹配PSM分析后,手工计算ATT检验与输出结果不同?
-
SPSSAU进行分析PSM时,如果有提供结果变量,系统默认会提供ATT效应结果值,该效应值的计算时会将‘weight(匹配成功的次数)’作为权重考虑进去。如果直接筛选出匹配成功后的数据进行t 检验分析,此种情况并没有将权重weight纳入考虑。与此同时,二者的不同仅会在出现weight>1这一前提下才会出现,即通常情况下放回抽样时才会有着不同,因为放回抽样时weight容易大于1,而不放回抽样时则weight全部均为1。
-
SPSSAU中倾向得分匹配时半径匹配的原理?
-
SPSSAU提供倾向得分匹配时,半径匹配具体为最近临半径匹配,即满足半径范围内的最近匹配。而单独的‘最近临’匹配方式是匹配方式为挨的最近时进行匹配,其并不要求在半径范围内。
-
SPSSAU中1:N匹配时输出多个MatchId?
-
MatchId表示Id去匹配成功的编号。如果是1:1匹配,那么就只会有一个MatchId,如果是1:N匹配,那么就会有N个MatchId标题。当Y=1时MatchId标题里面记录的是被匹配成功的Id,当Y=0时其全部为null值,因为Y=0时其意义消失。
-
SPSSAU倾向得分匹配时Weight的意义?
-
SPSSAU中Weight表示匹配成功个数。具体关于Weight的说明如下:比如1:N时,当Y=1时,其表示匹配成功的次数,计算上Weight为对应的Weight表示MatchId中不为空的个数(Weight值最大为N)。当Y=0时,如果是不放回抽样,那么Weight为Id出现在各MatchId中的次数(Weight值最大为N);如果是放回抽样,其可能会大于匹配次数N,因为放回抽样时会中间重复匹配多次。
-
1:N匹配与1:1匹配有什么区别?
-
如果是进行1:N匹配(此处N>1)比如N=3,那么matchId会有3个即matchId1、matchId2和matchId3,用该3项来记录匹配Id。但需要注意的是,有时候可能匹配不上,也或者要求1:3匹配,但仅匹配成功1个或者2个。
-
1:N匹配时weight的意义?
-
如果是进行1:N匹配(此处N>1),在SPSSAU系统中,weight表示匹配成功的次数,比如某id与其它Id成功匹配了10次就为10,(此定义与其它软件比如Stata中不同,Stata中表示平均匹配成功次数,比如1:3匹配,那么匹配成功10次时,Stata为10/3)。与此同时,在进行ATT效应值计算时,SPSSAU与Stata软件一致,使用‘平均匹配成功次数’进行ATT效应的t 检验计算。
-
什么时候使用1:N匹配?
-
倾向得分匹配时,多数情况下是使用1:1匹配,1:1匹配时相对匹配精准度会更高,如果数据希望得到更广泛的匹配则可使用更高的匹配数量。
-
SPSSAU进行分析时提示‘超时’或‘请求超时’?
-
在某些分析时,比如malquist/dea/rdd断点回归/零膨胀负二项回归等时,其计算量可能较大导致系统无法在非常快的时间内计算出结果,因而会提示‘超时’。此种情况下建议稍等5分钟,然后刷新页面,即可看见‘分析结果列表’中出现新的分析结果,点击打开即可。如果5分钟后还是没有结果,最简单的处理是在EXCEL中对数据进行删减(比如5万行数据变成2万行)后重新上传分析,以及也可以页面右上角反馈人工客服辅助查看处理(提问时,需要提供数据和操作截图共两项)。