
-
在进行线性回归分析时,很容易出现自变量共线性问题,通常情况下VIF值大于10说明严重共线,VIF大于5则说明有共线性问题;当出现共线性问题时,可能导致回归系数的符号与实际情况完全相反,本应该显著的自变量不显著,本不显著的自变量却呈现出显著性;共线性问题会导致数据研究出来严重偏差甚至完全相反的结论,因而需要解决此问题。
针对共线性问题的解决方案上,可以有以下几种处理方法:
编号 分析方法 备注说明 1 逐步回归 技巧式处理,让算法移除掉不显著的自变量X 2 岭回归回归(Ridge回归) 改良最小二乘法,L2正则化 3 Lasso回归(套索回归) 改良最小二乘法,L1正则化 4 主成分分析 对数据降维后,得到成分得分去表示‘各主成分’,并且使用成分得分进行后续比如回归分析 5 PLS回归 仅针对小样本量进行(比如小于100个样本),同时利用了主成分降维和回归思想 如果是使用逐步回归解决多重共线性问题,其为‘技巧式’处理,其让算法自动找出显著的X,通常情况下,此种做法会避开共线性的变量,实质上其并没有直面共线性问题,只是很可能避开了共线性而已,在实际研究中使用较多;除此之外,岭回归和Lasso回归是直观共线性问题的两种处理方式,岭回归和lasso回归在于对损失函数进行改造,但此两种方法的具体损失函数改造上,岭回归是使用L2正则化,Lasso回归是使用L1正则化。相对来讲,岭回归用于解决共线性问题的时候较多,Lasso回归除了有解决共线性问题的功能外,其还可用于进行‘特征筛选’,即找出有意义的自变量X(特征项),一般在机器学习领域使用此功能较多。
除此之外,主成分分析是利用降维的思想去解释共线性问题,比如有10个X,其利用降维原理将10个X降维成比如3个主成分,然后后续再进行分析比如线性回归(此种做法称作主成分回归)。而PLS回归是同时利用主成分和回归混合在一起的处理方式,一般用于非常小的样本(比如小于100的样本时),经济领域中使用主成分相对较多,但在其它领域中可能使用PLS回归相对较多。
类似于Ridge Regression,Lasso回归的分析时也分为两个步骤:分别是结合轨迹图寻找最佳K值;输入K值进行回归建模。
-
第一步:Lasso回归分析前需要结合轨迹图确认K值;K值的选择原则是各个自变量的标准化回归系数趋于稳定时的最小K值。K值越小则偏差越小,K值为0时则为普通线性OLS回归;SPSSAU提供K值智能建议,也可通过主观识别判断选择K值;
-
第二步:对于K值,其越小越好,通常建议小于1;确定好K值后,即可主动输入K值,得出Lasso回归模型估计。
SPSSAU操作截图如下:
如果输入框中不输入值,此时SPSSAU默认是生成轨迹图,即识别最佳K值(当然SPSSAU会智能化建议最佳K值);如果输入K值,此时SPSSAU则输出Lasso回归模型结果。
-
Lasso回归分析案例
-
1、背景
现测得胎儿身高、头围、体重和胎儿受精周龄数据,希望建立胎儿身高、头围、体重去和胎儿受精周龄间的回归模型。根据医学常识情况(同时结合普通线性最小二乘法OLS回归测量),发现三个自变量之间有着很强的共线性,VIF值高于200;因为很明显的可知,胎儿身高、体重之间肯定有着很强的正相关关系。因而此类数据有着很强的共线性,不能使用常见的最小二乘法OLS回归分析。可使用Lasso回归模型处理共线性问题。
-
2、理论
Lasso回归分析(Lasso Regression)是一种用于解决线性回归分析中自变量共线性的研究算法。针对Lasso回归:其研究步骤共为2步,分别是结合轨迹图寻找最佳K值;输入K值进行回归建模。
-
第一步:Lasso回归分析前需要结合轨迹图确认K值;K值的选择原则是各个自变量的标准化回归系数趋于稳定时的最小K值。K值越小则偏差越小,K值为0时则为普通线性OLS回归;SPSSAU提供K值智能建议,也可通过主观识别判断选择K值;
-
第二步:对于K值,其越小越好,通常建议小于1;确定好K值后,即可主动输入K值,得出Lasso回归模型估计。
对于Lasso回归研究,如果不输入K值,此时SPSSAU默认是生成轨迹图,即识别最佳K值(当然SPSSAU会智能化建议最佳K值);如果输入K值,此时SPSSAU则输出Lasso回归模型结果。
-
-
3、操作
使用SPSSAU进行Lasso回归研究时:首先不输入K值,则得到轨迹图用于判断最佳K值(SPSSAU也会智能建议最佳K值);得到最佳K值后,输入具体值,最终SPSSAU会输出模型结果。本案例时SPSSAU建议K值为0.3。
-
4、SPSSAU输出结果
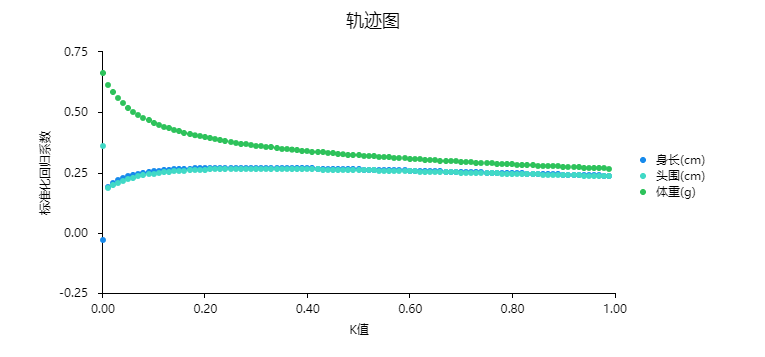
轨迹图描述不同K值时,自变量进行Lasso回归时标准化回归系数的变化情况。如果说标准化回归系数趋于稳定,此时对应的最小K值,即为最佳K值。此过程的判断带有一定的主观性,比如上图中,K值看上去选择为0.3,也或者0.4均可。建议以更小的K值作为标准;同时,可直接使用SPSSAU提供的建议最佳K值。
本案例中SPSSAU建议最佳K值为0.3,因而重新进行分析时输入0.3,得到最终Lasso回归模型结果如下表:
-
5、文字分析
具体文字分析例子如下:
本次研究胎儿身高、头围、体重对于胎儿受精周龄数据的影响;使用线性回归分析时发现VIF值出现大于200,即存在着严重的共线性问题。因而使用性能更好的Lasso回归模型进行研究。Lasso回归模型研究共分为两步,第一步是通过轨迹图识别最佳K值;第二步是利用确定好的最佳K值进行建立模型,得到最终模型。使用SPSSAU进行研究时,SPSSAU建议使用最佳K值为0.3,而且对比轨迹图判断可知,K值从0.3逐步增大时,自变量的标准化回归系数趋于稳定,因而最终K值取为0.3,最终得到Lasso回归模型。
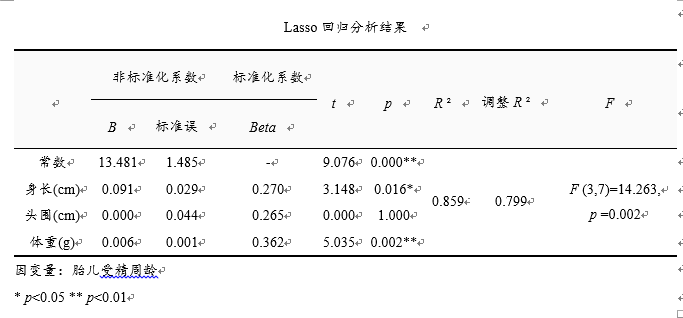
将身长(cm), 头围(cm), 体重(g)作为自变量,而将胎儿受精周龄作为因变量进行Ridge回归分析,K值取为0.3,模型R平方值为0.859,意味着身长(cm), 头围(cm), 体重(g)可以解释胎儿受精周龄的85.9%变化原因。对模型进行F 检验时发现模型通过F 检验(F (3,7)=14.263, p =0.002<0.05),也即说明身长(cm), 头围(cm), 体重(g)中至少一项会对胎儿受精周龄产生影响关系。
模型公式为:胎儿受精周龄=13.481 + 0.091*身长(cm) + 0.000*头围(cm) + 0.006*体重(g)。身长(cm)的回归系数值为0.091(t =3.148,p =0.016<0.05),意味着身长(cm)会对胎儿受精周龄产生显著的正向影响关系。头围(cm)的回归系数值为0.000(t =0.000,p =1.000>0.05),意味着头围(cm)并不会对胎儿受精周龄产生影响关系。体重(g)的回归系数值为0.006(t =5.035,p =0.002<0.01),意味着体重(g)会对胎儿受精周龄产生显著的正向影响关系。总结分析可知:身长(cm), 体重(g)会对胎儿受精周龄产生显著的正向影响关系。但是头围(cm)并不会对胎儿受精周龄产生影响关系。
总结分析可知:身长(cm), 体重(g)会对胎儿受精周龄产生显著的正向影响关系。但是头围(cm)并不会对胎儿受精周龄产生影响关系。
-
6、剖析
-
Lasso回归分析需要特别注意两点,分别是共线性判断和分析步骤。
-
是否呈现出共线性,一定需要有理有据,比如VIF值过高,也或者自变量之间的相关关系过高(比如大于0.6);如果数据并没有共线性,依旧建议使用普通线性最小二乘法回归。
-
Lasso回归建模共分为两步,分别是寻找最佳K值和建模。轨迹图中,如果过了某点时趋于稳定,则该点对应的K值为最佳K值,以及K值是越小越好。
本案例数据参考资料:
张文彤,董伟.SPSS统计分析高级教程[M]. 第2版. 北京:高等教育出版社, 2015.04: 130-132.
-
疑难解惑
-
F 值括号里面的两个值分别是什么?
-
如果是F 值想计算得到p 值,需要提供两个自由度值df 1和df 2。一般情况下,df 1等于自变量数量;df 2等于样本量 - (自变量数量+1)。此两个值仅为中间过程值,规范格式上需要写成这样而已,无其它实际意义。
-
智能分析每次都提示k值为0.99?
-
SPSSAU提供的智能分析是一种建议性质,它会结合交叉对比算法自动提供一个建议;实际研究中,lasso回归K值的判断带有较强的主观性质,因而研究者可结合岭迹图选择合适的K值。同时可将SPSSAU提供的建议K值,与主观判断得到的K值分别进行分析,然后对比各项指标(比如R方值)进行使用即可。
-
lasso回归分析前是否需要对数据进行标准化处理?
-
lasso回归时,可先对数据进行标准化处理(数据处理->生成变量功能),然后再进行lasso回归分析,当然也可以直接针对标准化回归系数进行分析即可,SPSSAU默认有输出标准化回归系数。
-
Lasso回归与岭回归如何选择?
-
Lasso回归和岭回归时,它们均可以解决共线性问题,但一般使用岭回归相对较多,正常情况下二者去解决共线性回归时结论应该保持一致。与此同时,lasso回归可用于‘特征筛选’,但岭回归并无此功能。Lasso回归和岭回归在数学原理上的区别为损失函数的不同,lasso回归使用L1正则化,岭回归使用L2正则化。
-
lasso回归时提示‘某标题数字恒定,请检查数据!’?
-
如果出现某标题数字恒定,建议先做通用方法里面的描述分析,查看最大值和最小值,如果二者完全一致则说明该项全部数字恒定,将该项从模型中移出后再次分析即可。
-
lasso回归时没有输出标准化回归系数?
-
如果某标题数字恒定则不会输出标准化回归系数。建议先做通用方法里面的描述分析,查看最大值和最小值,如果二者完全一致则说明该项全部数字恒定,将该项从模型中移出后再次分析即可。