
信息量权重法也称变异系数法,信息量权重法是一种客观赋权法。其思想在于利用数据的变异系数进行权重赋值,如果变异系数越大,说明其携带的信息越大,因而权重也会越大,此种方法适用于专家打分、或者面试官进行面试打分时对评价对象(面试者)进行综合评价。
比如有5个水平差不多的面试官对10个面试者进行打分,如果说某个面试官对面试者打分数据变异系数值较小,说明该面试官对所有面试者的评价都基本一致,因而其携带信息较小,权重也会较低;反之如果某个面试官对面试者打分数据变异系数值较大,说明该面试官对所有面试者的评价差异较大,因而其携带信息大,权重也会较高。
最终面试者的综合评价得分,是结合面试官的权重与面试官打分相乘计算得到,综合评价得分越高那么该面试者评价越好。
-
特别提示
-
信息量权重的适用场景较小,通常只用于专家评价打分时使用,此方法只利用了数据内容的波动性情况,但其简单易懂计算也特别简单。
信息量权重案例
-
1、背景
当前公司进行招聘一名市场部经理,共有10名面试者,并且5名企业高管对10名面试者进行打分。数据如下:

2、理论
信息量权重法只利用变异系数这一个指标进行赋权,其计算简单,但同时其只考虑了数据的变异波动性,因而需要谨慎使用,其只适用于专家打分(比如面试官打分,专家评价)这一种情况,其余数据请勿使用。最终将专家打分与专家的权重进行相乘,计算得到每个评价对象(面试者)的综合评价得分,选出最优先的评价对象(面试者)。
3、操作
本例子中共有5名面试官,因此拖拽5项进入分析框中,并且选择“保存综合得分”,便于得到每个评价对象(面试者)的综合得分数据。如下图所示:

4、SPSSAU输出结果
SPSSAU共输出一个表格,表格里面包括平均值、标准差、CV系数(变异系数)和权重值等。评价对象(面试者)的综合得分会保存在原始数据中,下载即可使用。
5、文字分析
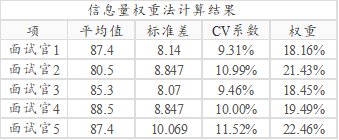
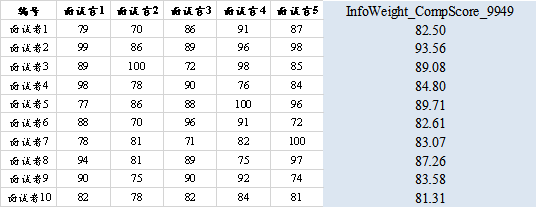
从上表格可以看出:面试官5的权重最高,其次是面试官2,以及输出10名面试者的综合评价得分如下表格,可以看出,面试者2的综合评价得分最高为93.56分,因此面试者2最终应该被录用为市场部经理。
6、剖析
涉及以下几个关键点,分别如下:
-
信息量权重法仅考虑数据的变异性,即数据的波动情况如何,不考虑其它任何信息。因此其仅适用于专家打分得到综合得分的场合。
疑难解惑
-
为什么分析样本量小于实际样本量?
-
如果分析时出现‘分析样本量’小于样本量,有3种可能。1是免费版(免费版仅分析前100行数据);2是做过‘筛选样本’功能(即主动设置只分析其中一部分数据);3是原始数据中有缺失数据(系统右上角‘我的数据’处可查看原始数据,也可下载原始数据等)。