
-
如果研究X对于Y的影响,Y为定量数据则可以使用线性回归分析。如果Y是定类数据,此时则需要使用Logit(logistic)回归分析。Logit回归共分为三种,分别是二元Logit(Logistic)回归、多分类Logit(Logistic)回归,有序Logit(Logistic)回归(也称Oridinal回归),此三个方法的区别在于因变量Y的数据类型。如下表:
项 特征 举例 其它 二元Logit(Logistic)回归 Y为定类且选项仅2个 是否愿意购买(愿意用1表示,不愿意用0表示 Y的数字个数仅2个,且数字只能为0和1 多分类Logit(Logistic)回归 Y为定类且选项大于2个 总统候选人偏好(特朗普、希拉里、卢比奥) 类别通常较少,比如3~8个之间 有序Logit(Logistic)回归 Y为定类且有序 幸福感(不幸福、比较幸福和十分幸福) 类别通常较少,比如3~8个之间 如果是有序Logit(logistic)回归,其因变量Y为定类且有序,即因变量的属性类别上为类别数据,但是类别之前可以对比大小,比如“不幸福,比较幸福和十分幸福”这是三种类别,但同时此三种类别可以对比大小,数字越大代表越幸福(此类数据也称有序数据)。如果因变量为此类数据时,则需要使用有序logit回归分析。
有时候,有序Logit(logistic)回归的数据也可以直接进行线性回归分析,而且结论上基本一致,线性回归分析时要求因变量Y应该满足正态性,而有序Logit(logistic)回归则需要因变量Y为类别数据且有序。针对自变量X,并没有特别的数据类型要求,如果是定量数据直接放入就好,如果是定类数据可能需要进行‘虚拟(哑)变量’设置。
-
特别提示
-
有序Logit回归的分析要求数据满足平行性检验,如果不满足,SPSSAU建议使用多分类Logti回归分析即可;
-
如果自变量个数非常多,建议用户可先进行卡方检验,筛选出p 值小于0.05的自变量放入模型中。
-
有序Logit回归案例
-
1、背景
当前有一份研究数据是用来研究民众幸福度影响因素,包括性别,年龄,学历和年收入水平共4个潜在的影响因素对于幸福水平的影响情况。幸福水平共由三项表示,分别是“不幸福,比较幸福和十分幸福”,由于Y为定类数据且有序,因而适用于有序Logit回归分析。
-
2、理论
有序Logit回归分析用于研究X对于Y的影响关系,如果X为定类数据,一般需要做虚拟(哑)变量设置,Y为有序定类数据。有序Logit回归分析时,首先进行模型平行性检验,如果p 值大于0.05,说明满足平行性检验,如果p 值小于0.05,说明不满足平行性检验,此时SPSSAU建议使用多分类Logit回归分析;满足平行性检验后,接着再具体研究影响关系情况即可,比如是正向影响还是负向影响关系等;除此之外,还可以写出有序Logit回归分析的模型构建公式,以及模型的预测准确率情况等。
除此之外,有序Logit回归模型涉及到多类连接函数,SPSSAU默认使用logit连接函数,如果模型没有特别的要求,应该首选使用logit连接函数,尤其是因变量的选项数量很少的时候。连接函数可能会对平行性检验起到影响,如果平行性检验无法通过时,可考虑选择更准确的连接函数进行尝试,按照因变量选项的分布情况划分,各类连接函数的使用场景说明如下:
连接函数 模型公式 使用说明 Logit log(ξ/(1−ξ)) 因变量各选项分布较为均匀,或者选项个数较少时使用; Probit Φ−1(ξ) 因变量接近正态分布时使用 补充log-log log(−log(1−ξ)) 因变量水平高的选项出现概率高,且选项个数较多时使用 负log-log −log(−log(ξ)) 因变量水平低的选项出现概率高,且选项个数较多时使用 Cauchit tan(π(ξ−0.5)) 因变量存在极端值时使用 具体使用情况举例说明:
有序Logistic回归分析因变量频数分布 名称 选项 频数 百分比 因变量y 1.0(不满意) 120 67.42% 2.0(中立) 31 17.42% 3.0(满意) 27 15.17% 总计 178 100.0 上表格中:因变量y共分为三个类别,并且水平高的选项“3.0(满意)”比例很低,因此可使用“负log-log”连接函数,当然依旧可以使用logit连接函数进行研究(这里因变量仅3个选项,SPSSAU认为使用logit连接函数更适合),其性能最佳。
如果说因变量y的分类类别很多,而且做正态性检验接近正态分布,此时可考虑使用Probit连接函数,但是此类情况非常少见,因为分类数据很难出现正态分布的现象;以及Cauchit连接函数是因变量类别出现极端值现象时使用,比如某个类别仅出现1个或者2个样本,此类情况的使用非常少,与其让极端值存在,还不如先对各选项进行合并处理,或者将异常值处理后再分析,因此Cauchit的使用非常少见。
SPSSAU默认使用logit连接函数进行分析,并且也建议使用此项,从连接函数的角度上看,logit连接函数最适用于各个类别分布较为均匀时;但现实研究来看logit连接函数的效能很高。如果各选项分布不均匀,此时可考虑合并组别等,也或者直接使用多分类logistic回归。
-
特别提示
-
如果X为定类数据,通常情况下需要将X进行虚拟(哑)变量设置【SPSSAU中生成变量功能中有】;
-
如果模型不满足平行性检验, SPSSAU建议使用多分类Logti回归分析;
-
如果模型没有通过似然比检验,意味着模型构建无意义,此时也建议使用多分类Logti回归分析进行尝试等;
-
如果X非常多(比如超过10个),此时可以先对定类的X与Y进行卡方分析,对定量的X与Y进行方差分析,先看有没有差异关系,将最终有差异关系的X放入有序Logit回归模型中,这样X会较少,并且X与Y均有差异关系,也更可能有影响关系,此时有序Logit回归模型的预测准确率会更高。
-
-
3、操作
本例子中研究X对于Y的差异;X分别为性别,年龄,学历和年收入水平,Y为幸福水平,幸福水平共由三项表示,分别是“不幸福,比较幸福和十分幸福”。由于性别为类别数据,所以将其设置为虚拟哑变量,并且以“男”作为参照项,因为放入“女”到模型中,放置如下:
-
4、SPSSAU输出结果
SPSSAU共输出五个表格,分别是因变量频数分布统计表格,平行性检验表格,模型似然比检验表格,回归模型分析结果表格和回归模型预测准确率表格。
有序Logistic回归分析因变量频数分布 名称 选项 频数 百分比 幸福水平 不幸福 168 45.16% 比较幸福 77 20.70% 非常幸福 127 34.14% 总计 372 100.0 第1个表格展示因变量各个类别的分布情况。如果因变量各类别分布非常分散,则需要对类别进行重新组合后再次进行分析。同时,如果因变量的类别个数非常多,也需要针对类别进行重新组合后才能进行分析。
有序Logistic回归模型平行性检验 模型 -2倍对数似然值 卡方值 df p 原假设 720.126 最终 718.268 1.858 4 0.762 第2个表格展示模型的平行性检验,检验的原假设为模型满足平行性,因而如果p 值大于0.05则说明模型接受原假设,即符合平行性检验。反之如果p 值小于0.05则说明模型拒绝原假设,模型不满足平行性检验。平行性是有序Logit回归的前提条件,如果不满足平行性,SPSSAU建议使用多分类Logit回归模型。
有序Logistic回归模型似然比检验 模型 -2倍对数似然值 卡方值 df p AIC 值 BIC 值 仅截距 782.636 最终 720.126 62.510 4 0.000 732.125 755.639 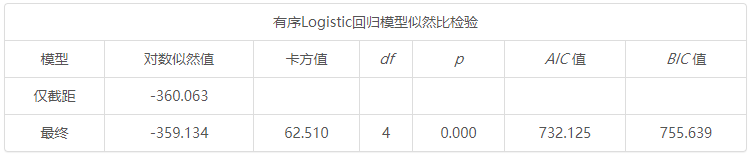
第3个表格展示模型的似然比检验结果,其原假设是模型的回归系数全部均为0,因此如果p 值小于0.05,则说明拒绝原假设,即说明模型有效;反之如果p 值大于0.05则说明接受原假设,即说明模型回归系数全部均应该为0,模型无意义。同时上表格还列出赤池信息准则AIC和BIC 值,如果进行过多次模型分析(比如模型的自变量个数变化时),然后需要对比模型的优劣,则可通过此两个指标进行分析,此两个指标值越小越好,没有固定范围标准。
有序Logistic回归模型分析结果汇总 项 回归系数 标准误 z 值 p 值 OR值 OR值95% CI(LL) OR值95% CI(UL) 性别_男 -0.072 0.205 -0.352 0.725 0.930 0.623 1.390 年龄 -0.027 0.009 -2.921 0.003 0.973 0.955 0.991 学历 0.311 0.089 3.502 0.000 1.365 1.147 1.625 年收入水平 0.508 0.105 4.849 0.000 1.662 1.354 2.041 McFadden R 方:0.080 Cox 和 Snell R 2:0.155 Nagelkerke R 2:0.176 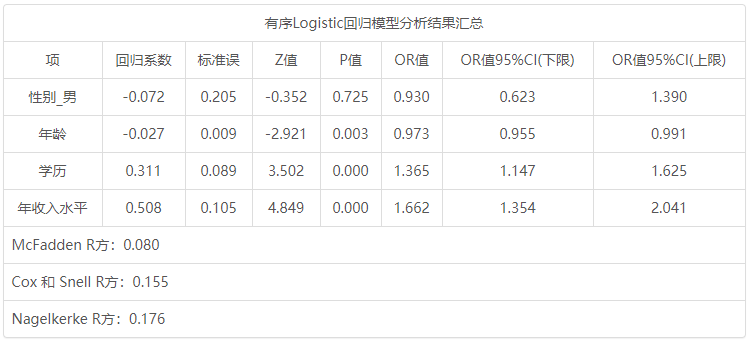
第4个表格展示模型的结果,包括回归系数的显著性,模型R 2值等。上表格中包括因变量阈值,其值基本无意义,仅从数学角度上看有此值输出而已。
有序Logistic回归模型预测准确率 项 实际频数 预测准确频数 预测准确率 不幸福 168 132 78.571% 比较幸福 77 0 0.000% 非常幸福 127 75 59.055% 总计 372 207 55.645% 第5个表格展示模型的预测准确率情况,包括各个类别和整体的预测准确率。如果模型用于预测分析,则预测准确率非常重要,如果模型用于研究影响关系,则不太关注预测准确率值。通常情况下样本量较小,预测准确率均非常低,但是多数实证研究的目的在于研究影响关系,因而预测准确率的关注度较小。
-
5、文字分析
有序Logistic回归分析因变量频数分布 名称 选项 频数 百分比 幸福水平 不幸福 168 45.16% 比较幸福 77 20.70% 非常幸福 127 34.14% 总计 372 100.0 本次有序Logit回归模型将性别(女性作为参照项), 年龄, 学历, 年收入水平作为自变量,将幸福水平作为因变量进行有序logistic回归分析,从上表可知:幸福水平共分为三个类别,分布较为均匀,其中比较幸福这一类别的占比较低为20.70%。
有序Logistic回归模型平行性检验 模型 对数似然值 卡方值 df p 原假设 -360.063 最终 -359.134 1.858 4 0.762 首先对模型进行平行性检验,从上表可知:平行性检验的原假设是各回归方程互相平行,分析显示接受原假设(χ2=1.858,p =0.762> 0.05),因而说明本次模型通过平行性检验,模型分析结论可信,可继续进一步的分析。
有序Logistic回归模型似然比检验 模型 对数似然值 卡方值 df p AIC 值 BIC 值 仅截距 -360.063 最终 -359.134 62.510 4 0.000 732.125 755.639
在模型通过平行性检验后,接着对模型整体有效性进行分析(模型似然比检验),从上表可知:此处模型检验的原定假设为:是否放入自变量(性别, 年龄, 学历, 年收入水平)两种情况时模型质量均一样;分析显示拒绝原假设(χ2=62.510,p =0.000< 0.05),即说明本次构建模型时,放入的自变量具有有效性,本次模型构建有意义。
有序Logistic回归模型分析结果汇总 项 回归系数 标准误 z 值 p 值 OR值 OR值95% CI(LL) OR值95% CI(UL) 性别_男 -0.072 0.205 -0.352 0.725 0.930 0.623 1.390 年龄 -0.027 0.009 -2.921 0.003 0.973 0.955 0.991 学历 0.311 0.089 3.502 0.000 1.365 1.147 1.625 年收入水平 0.508 0.105 4.849 0.000 1.662 1.354 2.041 McFadden R 方:0.080 Cox 和 Snell R 2:0.155 Nagelkerke R 2:0.176
从上表可知,将性别(女性作为参照项), 年龄, 学历, 年收入水平共4项为自变量,而将幸福水平作为因变量进行有序logistic回归分析,从上表可以看出,模型伪R 2值(McFadden R 2)为0.080,意味着性别, 年龄, 学历, 年收入水平可以解释幸福水平的8.0%变化原因。最终具体分析可知:
性别(男)的回归系数值为-0.072,但是并没有呈现出显著性(z =-0.352,p =0.725>0.05),意味着相对于女性,男性的幸福水平并没有明显的变化,即说明性别对于幸福水平没有影响关系。
年龄的回归系数值为-0.027,并且呈现出0.01水平的显著性(z =-2.921,p =0.003< 0.01),意味着年龄会对幸福水平产生显著的负向影响关系。以及优势比(OR值)为0.973,意味着年龄增加一个单位时,幸福水平的减少幅度为0.973倍。
学历的回归系数值为0.311,并且呈现出0.01水平的显著性(z =3.502,p =0.000< 0.01),意味着学历会对幸福水平产生显著的正向影响关系。以及优势比(OR值)为1.365,意味着学历增加一个单位时,幸福水平的增加幅度为1.365倍。
年收入水平的回归系数值为0.508,并且呈现出0.01水平的显著性(z =4.849,p =0.000< 0.01),意味着年收入水平会对幸福水平产生显著的正向影响关系。以及优势比(OR值)为1.662,意味着年收入水平增加一个单位时,幸福水平的增加幅度为1.662倍。
总结分析可知:学历, 年收入水平会对幸福水平产生显著的正向影响关系,以及年龄会对幸福水平产生显著的负向影响关系。但是性别并不会对幸福水平产生影响关系。
有序Logistic回归模型预测准确率 项 实际频数 预测准确频数 预测准确率 不幸福 168 132 78.571% 比较幸福 77 0 0.000% 非常幸福 127 75 59.055% 总计 372 207 55.645% 通过模型预测准确率去判断模型拟合质量,从上表可知:研究模型的整体预测准确率为55.65%,模型拟合情况较差。但本研究模型的重点在于找出对幸福水平有影响的因素,因此准确率的关注意义较小。
-
6、剖析
有序Logit回归分析涉及以下几个关键点,分别如下:
-
如果X为定类数据,通常情况下需要将X进行虚拟(哑)变量设置【SPSSAU中生成变量功能中有】;
-
如果模型不满足平行性检验, SPSSAU建议使用多分类Logti回归分析;
-
如果模型没有通过似然比检验,意味着模型构建无意义,此时也建议使用多分类Logti回归分析进行尝试等;
-
如果X非常多(比如超过10个),此时可以先对定类的X与Y进行卡方分析,对定量的X与Y进行方差分析,先看有没有差异关系,将最终有差异关系的X放入有序Logit回归模型中,这样X会较少,并且X与Y均有差异关系,也更可能有影响关系,此时有序Logit回归模型的预测准确率会更高。
-
通常情况下样本量较小,模型预测准确率均非常低;同时多数实证研究的目的在于研究影响关系,因而预测准确率的关注度较小。
-
连接函数默认使用Logit,如果平行性检验无法通过时,可考虑选择使用其它更适合的连接函数。同时如果平行性检验无法通过时,SPSSAU建议对因变量各组别合并处理后重新进行分析,也可以使用多分类logistic回归,或者合并组别后进行多分类logistic回归分析等。
-
疑难解惑
-
提示‘数据质量异常’
-
如果出现数据质量异常提示,通常是由于以下原因所致,可逐一进行检查:
-
第一:样本量非常少,如果样本量太少(比如10个)很可能出现此提示,建议加大样本量;
-
第二:自变量之间相关性非常强,建议使用【通用方法->相关分析】进行检验自变量之间的相关性,如果某两项之间的相关性高于0.7则说明相关性过高,建议删除部分项后再次进行分析;
-
第三:某个或多个分析项值基本恒定无变化,如果某个自变量全部都是恒定数字,一定会出现数据质量异常;也或者某个自变量的数字基本恒定(比如500个样本,某项有499个都是数字1),此时也很可能出现数据质量异常。建议使用频数分析进行检验,若有此类数据,从模型中移除出去即可;
-
第四:平行性检验,个别情况下会出现模型无法拟合平行性检验的情况(迭代次数超出范围也不收敛),建议可放弃平行性检验。以及如果出现此种情况,也可以考虑换用研究方法,比如换用通用方法里面的线性回归,也或者进阶方法里面的多分类Logit回归。
-
McFadden R 方、Cox & Snell R 方和Nagelkerke R 方相关问题?
-
Logit回归时会提供此3个R 方值,此3个R 方均为伪R 方值(并非像线性回归的R 方值意义一样),其值越大越好,但其无法非常有效的表达模型的拟合程度,意义相对交小,而且多数情况此3个指标值均会特别小,研究人员不用过分关注于此3个指标值。
-
提示‘数据质量异常’如何解决?
-
建议按以下步骤进行检查并解决。
-
第一:是否选中‘平行性检验’,有时候无法进行平行性检验,建议放弃‘平行性检验’,也或者改用多分类Logit回归即可;
-
第二:将所有项做相关分析,如果两两项之间的相关关系非常强(比如大于0.8)说明共线性问题严重,将此类自变量移除出去,再次分析就好;也或者自变量X与因变量Y之间基本完全没有关系(比如相关系数小于0.1),此时也可考虑移除此类自变量,再次分析就好;
-
第三:自变量中放入虚拟变量,比如学历有5项,虚拟变量出来为5项,5项全部都放入了模型,这一定会出错;
-
第四:数据分布严重不均匀。如果因变量有5个不同的数字,其中某项的比例仅为1%,也或者频数仅为个位数;此时有可能出现无法收敛模型无法拟合;
-
第五:分析样本量过小,比如分析项有10个,但分析样本量仅20个。
-
z 值的意义是什么?
-
z 值=回归系数/标准误,该值为中间过程值无意义,只需要看p 值即可。有的软件会提供wald值(但不提供z 值,该值也无实际意义),wald值= z 值的平方。
-
平行性检验出现null值?
-
如果平行性检验出现null值,意味着数据拟合时无法进行平行性检验。建议可直接放弃平行性检验,也或者改用多分类logit回归即可。
-
如何进行有序probit回归(order probit)?
-
可通过spssau的参数设置,在进行有序logit时,开始分析按钮右侧‘连接函数’参数选择为“probit”,此时得到的结果即为有序probit回归结果。
-
Logit回归时少了一项(阈值)?
-
有序logit回归或者多分类logit回归时,spssau默认会设置第一项作为参照项,因此输出结果时会少一项。
-
p for trend这个指标如何计算?
-
p for trend指标是指某个X对于Y的影响时的趋势情况如何。实际研究中计算该指标,其步骤如下:
-
第1步:对X进行分组处理得到新的标题Xnew,比如预期将血压分为低、中和高共三组:
-
第2步:对Xnew中的组别赋值编码数字,比如低赋值编码为0,中为1,高为2(此种方式为常见的编码方式,当然也可使用低/中/高组分别的中位数作为赋值编码数字);
-
第3步:将Xnew纳入模型中,其对应得到p值即为p for trend指标。
-
原理上:即将X分成几个组别,并且用不同的数字标识出各个组别的相对大小后得到分组后的Xnew,这样Xnew只包括几个数字且数字代表各个等级组别,此时将Xnew纳入模型时,其得到的p 值即为p for trend。
-
另提示:将X进行分组和编码,建议可使用SPSSAU数据处理-》数据编码功能实现,也或者在EXCEL中处理。